

Big data synchronization method and device based on Binlog, HBase and Hive
A data synchronization and big data technology, applied in the database field, can solve the problems of data synchronization performance consumption, etc., and achieve the effect of small data volume, powerful data query support, and high real-time data
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
[0051] Embodiment 1 of the present invention provides a big data synchronization method based on Binlog+HBase+Hive, such as figure 1 shown, including:
[0052] In step 201, monitor the Binlog log file in the relational database to obtain real-time changing data.
[0053] Wherein, the relational database includes: one or more of Oracle, DB2, Microsoft SQL Server, Microsoft Access and MySQL.
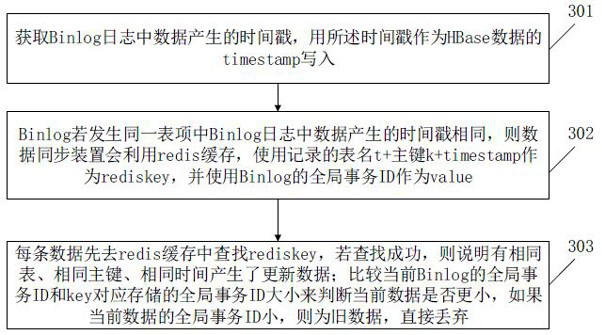
[0054] In step 202, after the data synchronization device obtains the Binlog log file data, it parses and obtains the database name db, the table name t, the operation type o, the primary key k, and all field values; when storing the Binlog log file data in HBase, the corresponding database The name is used as the namespace of the HBase table, and the table db:t is created.
[0055] Among them, in the Hbase database, the naming rule for creating a table is "space name": "table name", that is, the above-mentioned db:t.
[0056] In step 203, the primary key k is used as the rowkey of the ...
Embodiment 2
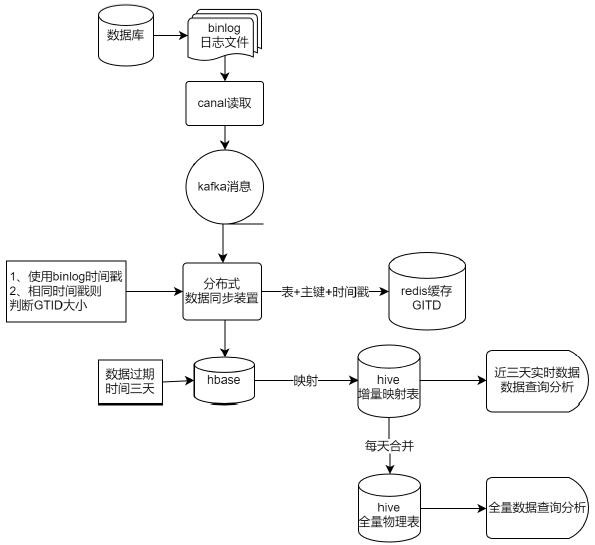
[0071] For the content of the method described in Embodiment 1, in the embodiment of the present invention, another key node is cut in, and the content is presented in combination with specific tools. The corresponding overall process is as follows image 3 shown.
[0072] Part 1: Real-time Binlog acquisition
[0073] As a preference, you can use the canal tool to monitor the MySql database Binlog logs, and then connect the Binlog log data to the message middleware Kafka, and then develop applications for data consumption processing. Or use Ali's logtail tool, and then develop program consumption.
[0074] That is, the method of obtaining real-time changing data by monitoring MySql Binlog log files, compared with the data query and export scheme, does not affect the database performance, and solves the problems of data synchronization performance and timeliness.
[0075] Part II: Real-time Binlog processing
[0076] The data synchronization device is characterized in that i...
Embodiment 3
[0090] like Figure 4 As shown, it is a schematic diagram of the architecture of the big data synchronization device based on Binlog+HBase+Hive according to the embodiment of the present invention. The big data synchronization device based on Binlog+HBase+Hive in this embodiment includes one or more processors 21 and memory 22 . in, Figure 4 A processor 21 is taken as an example.
[0091] Processor 21 and memory 22 can be connected by bus or other means, Figure 4 Take connection via bus as an example.
[0092] Memory 22, as a non-volatile computer-readable storage medium, can be used to store non-volatile software programs and non-volatile computer-executable programs, such as the big data synchronization based on Binlog+HBase+Hive in Embodiment 1 method. The processor 21 executes the big data synchronization method based on Binlog+HBase+Hive by running the non-volatile software programs and instructions stored in the memory 22 .
[0093] The memory 22 may include a hi...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More