Method and terminal for crawling third-party website data
A website and data technology, applied in the field of crawling third-party website data, can solve the problems of easy omission, time-consuming and labor-intensive, unable to guarantee the accuracy of data, etc., to achieve the effect of ensuring integrity, saving manpower and time costs
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
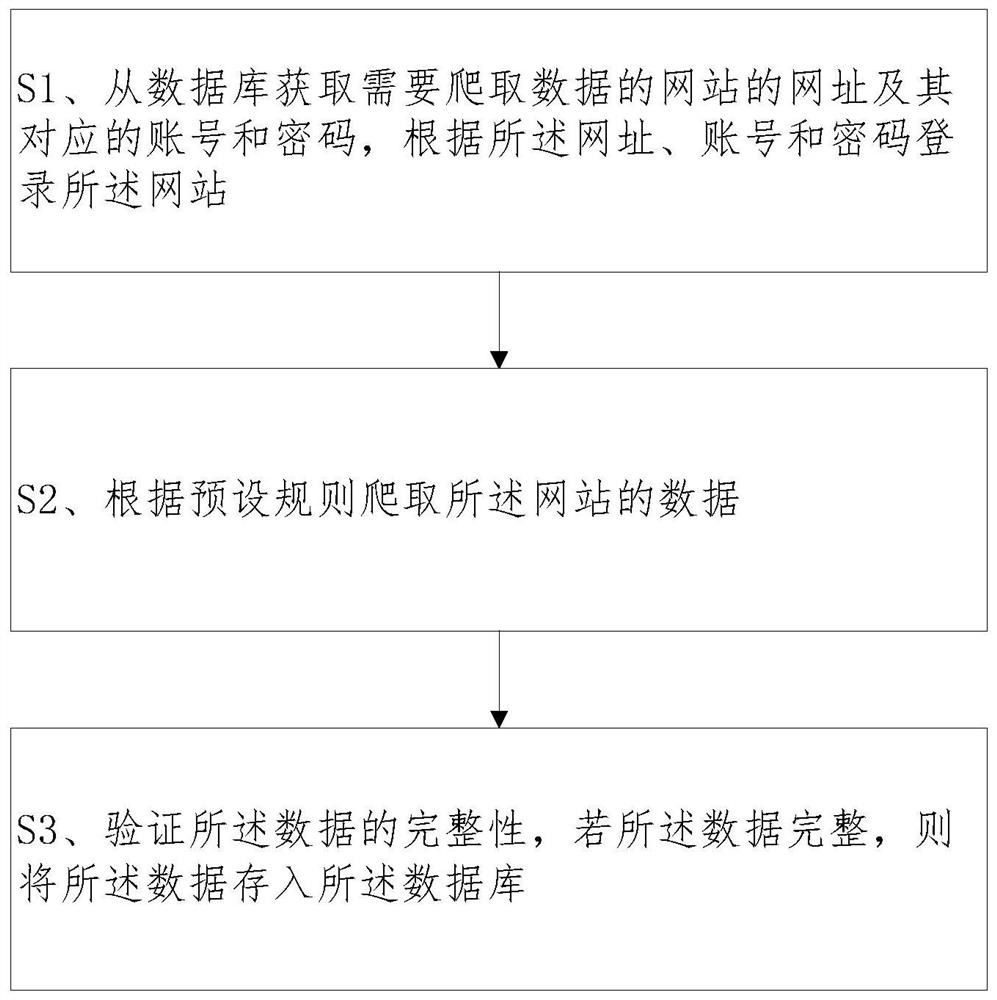
[0064] Please refer tofigure 1 As shown, a method of crawling third-party website data includes:
[0065] S1. Obtain the website address and the corresponding account number and password of the website that needs to crawl data from the database, and log in to the website according to the website address, account number and password;
[0066] S2. Crawling the data of the website according to preset rules;
[0067] S3. Verify the integrity of the data, and if the data is complete, store the data in the database.
[0068] Wherein, before said S1 includes:
[0069] S0. Store the websites that need to crawl data and their corresponding account numbers and passwords into the database.
[0070] Wherein, logging in to the website according to the website address, account number and password in S1 includes:
[0071] Open described website according to described website, judge whether described website has the detection to manual operation behavior, if exist, then simulate manual ope...
Embodiment 2
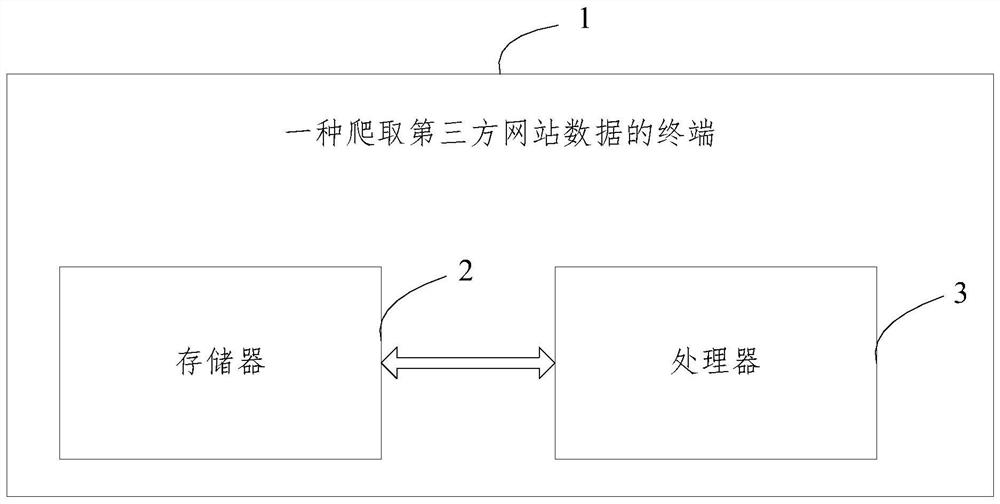
[0083] Please refer to figure 2 , a method terminal 1 for crawling third-party website data, including a memory 2, a processor 3, and a computer program stored on the memory 2 and operable on the processor 3, when the processor 3 executes the computer program Implement the steps in Embodiment 1.
[0084] In summary, the present invention provides a method and terminal for crawling third-party website data. After obtaining the website information to be crawled from the database, the data of these websites can be crawled autonomously according to the preset rules, and can be used for these websites. The integrity of the data is judged to ensure the integrity of the crawled data, and at the same time avoid manual login to multiple websites to crawl the data, saving manpower and time costs.
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More 
PatSnap Eureka turns technology decisions into work you can execute. Powered by our Innovation Knowledge Graph, it runs expert workflows across engineering, life sciences, materials and intellectual property. Get your review-ready output in minutes.



