

Distributed near-end strategy optimization method based on cognitive behavior knowledge and application thereof
An optimization method and distributed technology, applied in the field of deep reinforcement learning, can solve problems such as sampling complexity limiting the application of reinforcement learning algorithms
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0085] The present invention will be further described in detail below in conjunction with the accompanying drawings and specific embodiments.
[0086] The distributed near-end strategy optimization method based on cognitive behavioral knowledge proposed by the present invention comprises the following steps:
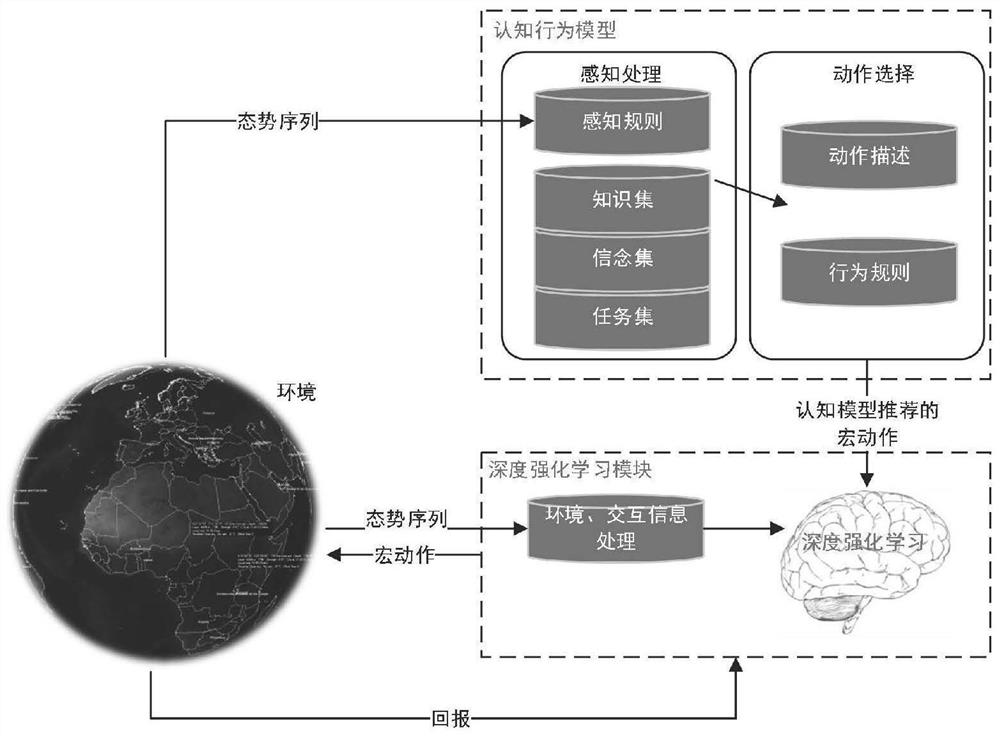
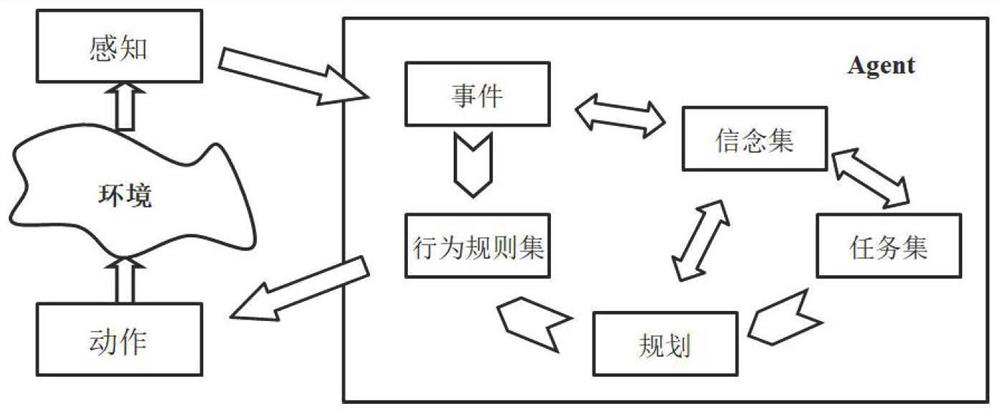
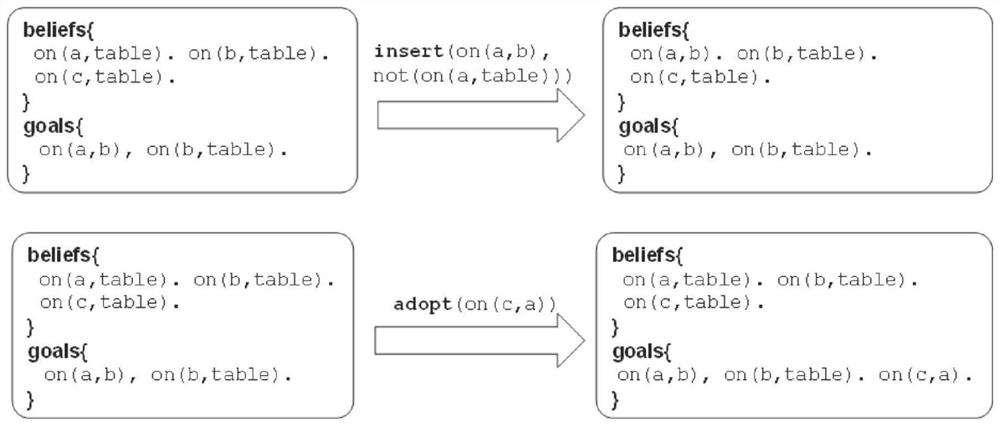
[0087] S1. Using cognitive behavioral knowledge to establish the cognitive behavioral model of the Agent, and introducing the cognitive behavioral model into deep reinforcement learning, constructing a deep reinforcement learning framework based on cognitive behavioral knowledge. The deep reinforcement learning framework based on the cognitive row model is as follows: figure 1 shown. The process of interaction between the GOAL-based cognitive behavioral model and the environment is as follows: figure 2 shown. The invention adopts a unified agent modeling method, and expresses elements such as knowledge, beliefs, intentions, rules, etc. into a form that can be unders...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More