

Speech recognition text enhancement system fused with multi-modal semantic invariance
A speech recognition and enhancement system technology, applied in speech recognition, speech analysis, biological neural network models, etc., can solve problems such as inapplicability, high error rate, and large amount of training data, so as to improve performance and reduce data dependence.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

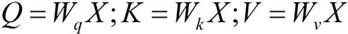
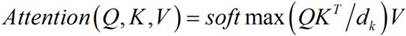
Examples
Embodiment
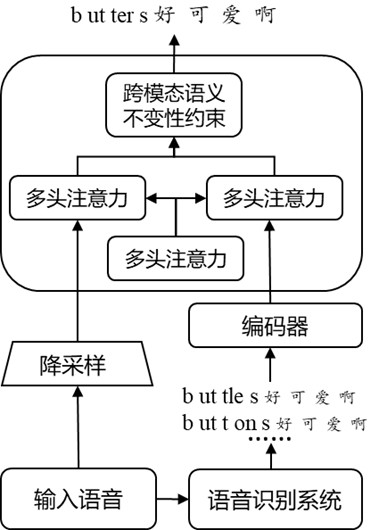
[0062] Such as figure 1 As shown, a speech recognition text enhancement system that incorporates multimodal semantic invariance includes:
[0063] Acoustic feature extraction module, acoustic down-sampling module, coder and decoder; Described acoustic feature extraction module is divided into the short-time audio frame of fixed length to speech data frame processing, extracts fbank acoustic feature to described short-time audio frame, Input the acoustic features into the acoustic downsampling module for downsampling to obtain an acoustic representation; input the speech data into an existing speech recognition module to obtain input text data, and input the input text data to the encoder , to obtain the input text coded representation; input the acoustic representation and the input text coded representation to the decoder for fusion to obtain a decoded representation; input the decoded representation to a softmax function to obtain the target with the highest probability;
...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More