Deep reinforcement learning traffic signal control method combined with state prediction
A reinforcement learning and traffic signal technology, which is applied in the traffic control system of road vehicles, traffic signal control, traffic control system, etc., can solve the problems of limited control effect, achieve the effect of easy prediction, improve traffic efficiency, and reduce the amount of data
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
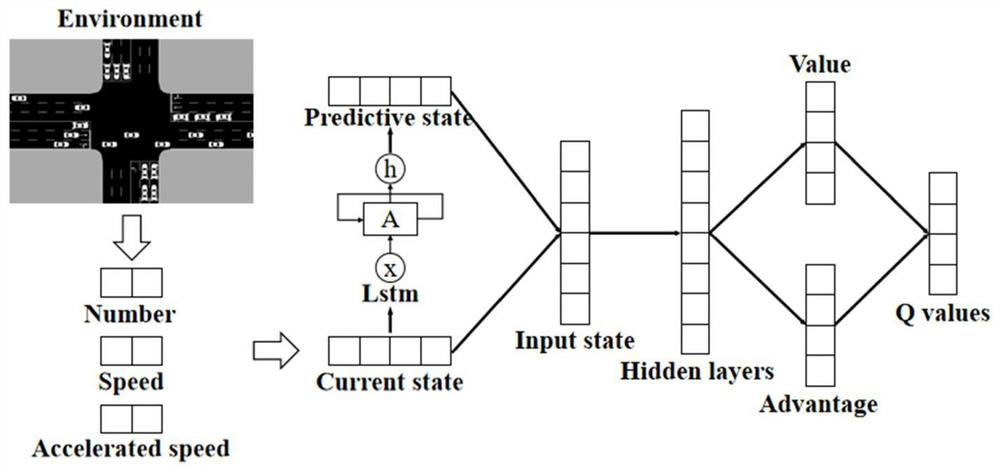
[0021] Such as figure 1 As shown, a deep reinforcement learning traffic signal control method combined with state prediction includes the following steps:
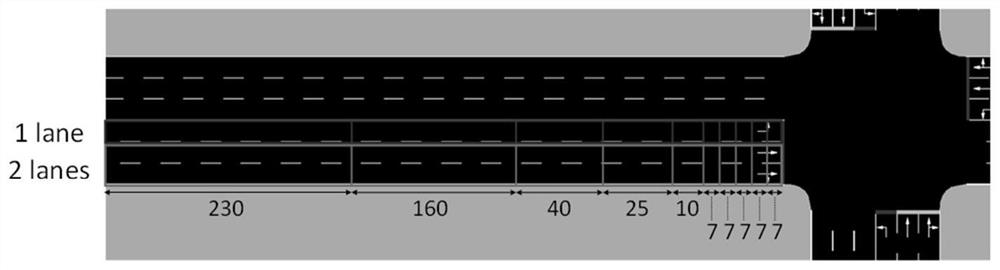
[0022] Step 1: Use SUMO modeling to generate an intersection model. The intersection is a two-way 6-lane lane with a length of 500m. Along the driving direction of the vehicle, the left lane is a left-turn lane, the middle lane is a straight lane, and the right lane is a straight lane plus a right-turn lane. Traffic flow data includes vehicle generation methods, simulation duration, number of vehicles, and driving trajectories. The generation of vehicles in the present invention obeys Weibull distribution, can simulate the situation of high and low traffic peaks in real life, has engineering application value, and its probability density function is:
[0023]
[0024] where λ is the scale parameter set to 1, and a is the shape parameter set to 2. The duration of a simulation round is 2 hours, and the number of vehicle...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More 
PatSnap Eureka turns technology decisions into work you can execute. Powered by our Innovation Knowledge Graph, it runs expert workflows across engineering, life sciences, materials and intellectual property. Get your review-ready output in minutes.



