Coal mine personnel behavior detection method and device, and storage medium
A detection method and behavior technology, applied in the field of image processing, can solve problems such as low accuracy of behavior detection results and weak data foundation, and achieve the effect of accurate behavior classification results and comprehensiveness
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0049] In order to make the purposes, technical solutions and advantages of the embodiments of the present application clearer, the technical solutions in the embodiments of the present application will be clearly and completely described below in conjunction with the drawings in the embodiments of the present application. Obviously, the described embodiments It is a part of the embodiments of this application, not all of them. Based on the embodiments in this application, all other embodiments obtained by persons of ordinary skill in the art without creative efforts fall within the protection scope of this application.
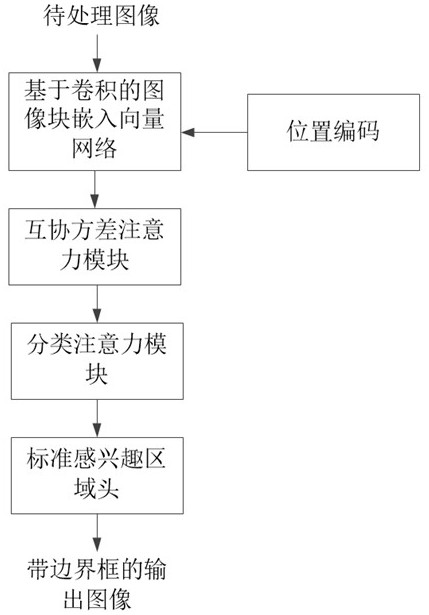
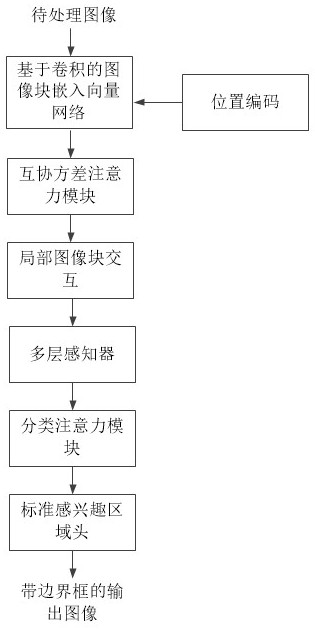
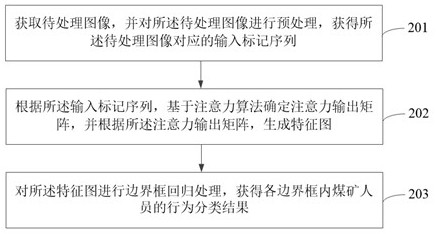
[0050]The production environment of coal mines is relatively complex and requires real-time monitoring, but manual supervision is time-consuming and labor-intensive. With the improvement of video data processing capability and the development of computer vision technology, coal mine intelligent video surveillance system has become an indispensable part of coa...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More 
PatSnap Eureka turns technology decisions into work you can execute. Powered by our Innovation Knowledge Graph, it runs expert workflows across engineering, life sciences, materials and intellectual property. Get your review-ready output in minutes.



