Pronunciation evaluating method based on voice identification and voice analysis
A speech analysis and speech recognition technology, applied in speech analysis, speech recognition, instruments, etc., can solve the problems of inaccurate pronunciation, limited teaching effect, inaudible, etc., and achieve the effect of improving accuracy and effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Benefits of technology
Problems solved by technology
Method used
Image


Examples
no. 1 example
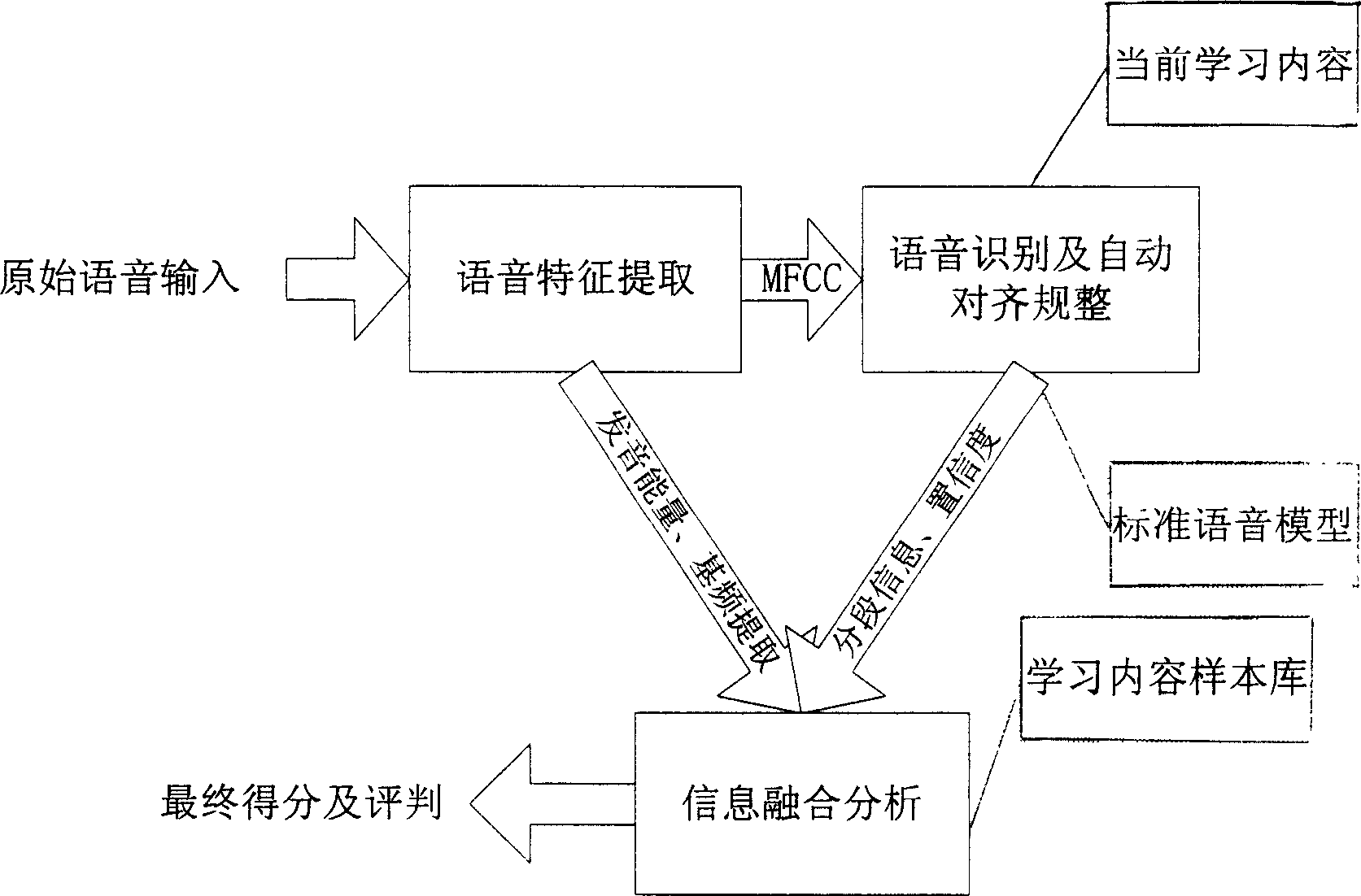
[0036] figure 1 It is a system block diagram of the pronunciation evaluation method of this embodiment. As shown in the figure, the pronunciation evaluation system of this embodiment includes a speech feature extraction module, a speech recognition and automatic alignment module, and an information fusion analysis module. After the original voice is input, it first enters the voice feature extraction module for feature extraction. The feature extraction process is to process the original voice signal in frames and obtain the data of each frame's pronunciation intensity, pronunciation duration, fundamental frequency curve and other characteristics. Then perform MFCC transformation on the original speech signal and enter the speech recognition module. According to the current learning content and standard speech model, the speech signal after MFCC transformation is speech recognized and automatically aligned, and the matching can be accurate to every English word in the sentence....
no. 2 example
[0072] The main difference between this embodiment and the first embodiment is that this embodiment also evaluates the pronunciation authenticity of syllables to more accurately point out the difference between the user's pronunciation and the standard pronunciation. In addition, this embodiment uses a different scoring method .
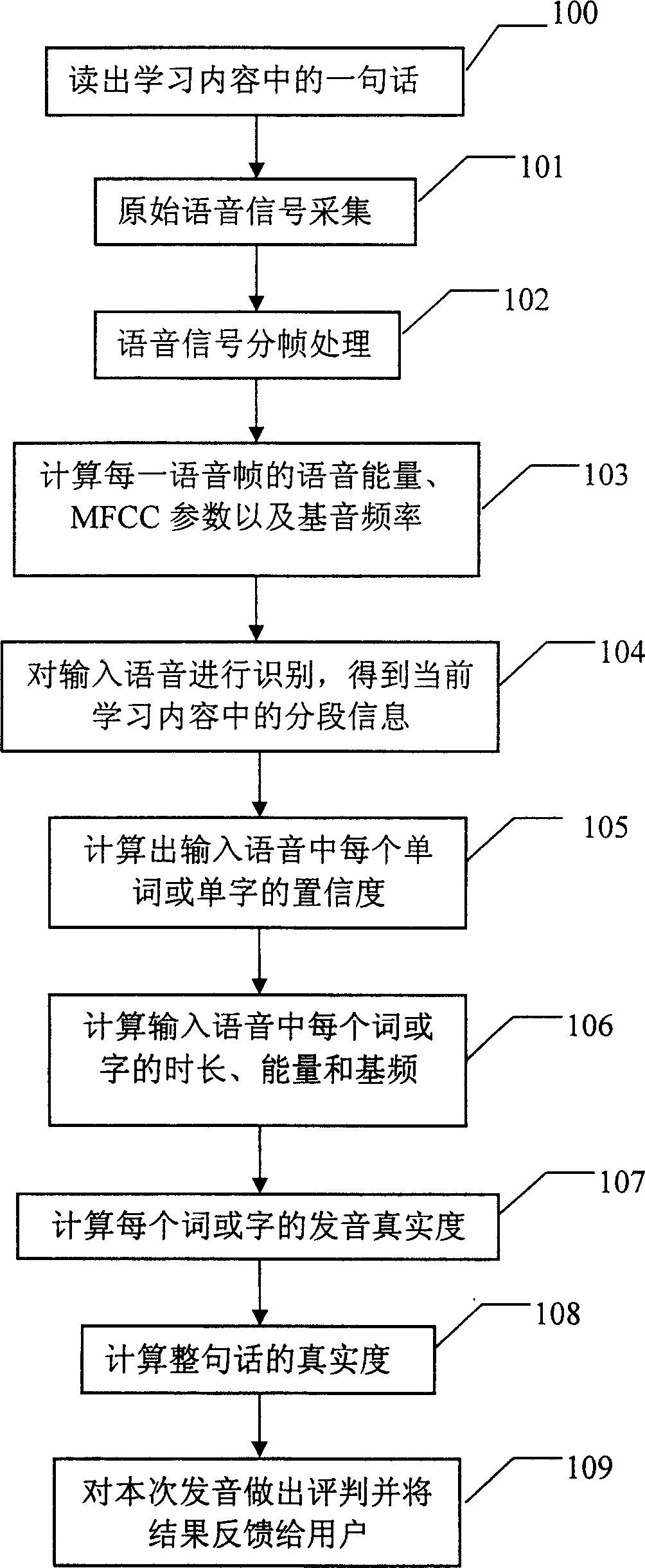
[0073] The pronunciation evaluation system of the present embodiment is the same as the first embodiment, and its method flow includes the following steps:
[0074] Step 200, the user reads a sentence in the learning content;
[0075] Step 201, collect the original voice signal, and convert the analog signal uttered by the user into a digital sampling signal;
[0076] Step 202, the digital signal of voice is processed by frame, usually with 25ms as the length of an analysis frame, after each frame is analyzed, the analysis frame is moved backward by 10ms, and then the processing is repeated until all signal processing is completed;
[0077] Step 20...
PUM
 Login to view more
Login to view more Abstract
Description
Claims
Application Information
 Login to view more
Login to view more - R&D Engineer
- R&D Manager
- IP Professional
- Industry Leading Data Capabilities
- Powerful AI technology
- Patent DNA Extraction
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic.
© 2024 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap