

Balance clustering compression method based on data similarity
A clustering compression and data similarity technology, applied in the direction of electrical digital data processing, special data processing applications, instruments, etc., can solve the problems of insufficient execution efficiency, uneven, data-dependent system load, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

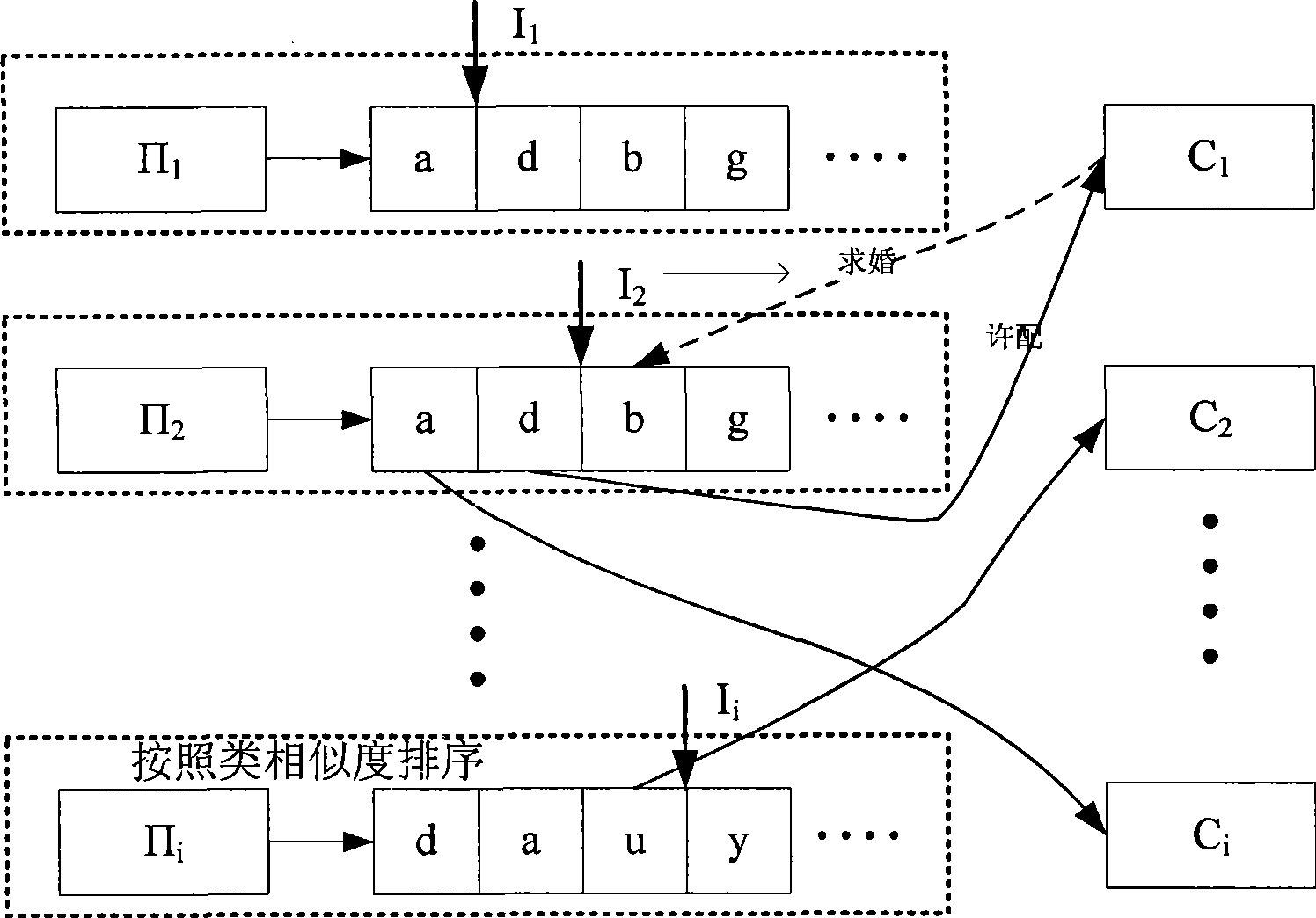
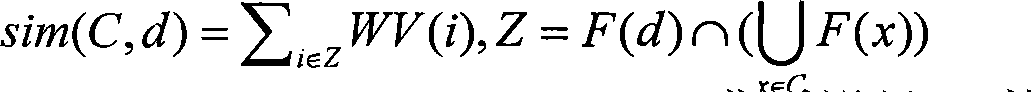
Examples
Embodiment Construction
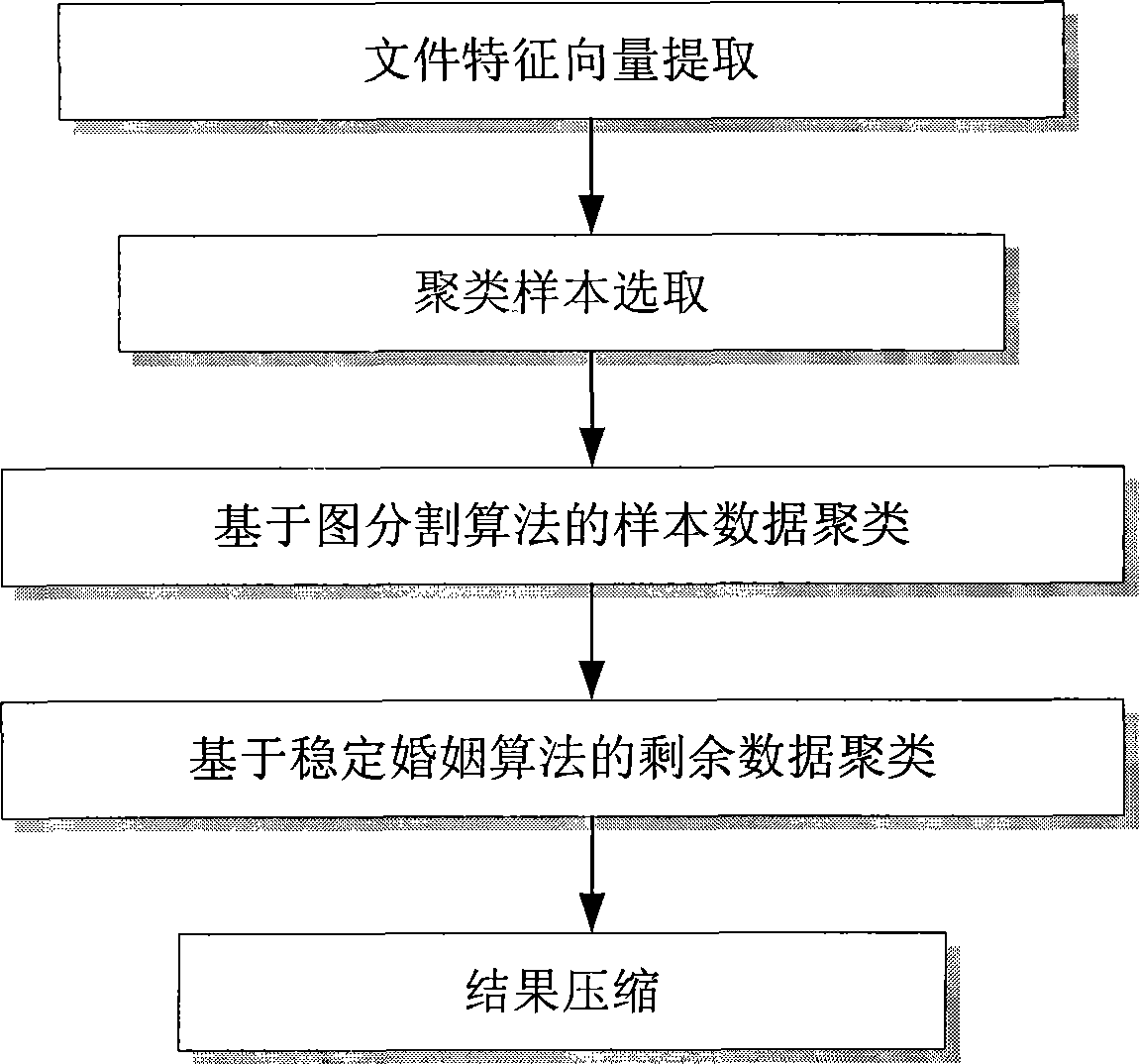
[0055] Such as figure 1 As shown, the implementation steps of the present invention are as follows:
[0056] 1. File feature vector extraction:
[0057] The feature vector is extracted from the document data to calculate the document similarity. The specific implementation steps are as follows:
[0058] 1) Choose an independent permutation function (h 1 , H 2 ,..., h k }, each permutation function is independent of each other, here an independent linear function is used, namely h i =a i x+b i mod p, where a i , B i , Is a randomly generated integer;
[0059] 2) Scan the input file f byte by byte from front to back, use the efficient Rabin fingerprint function to calculate the fingerprint of the data in the current sliding window, record the fingerprint as fp, and use the k independent permutation functions mentioned above to act on the fingerprint fp to obtain k Replace fingerprint h 1 (fp), h 2 (fp), …, h k (fp), record the feature vector F(f) of file f as {F 1 (f), F 2 (f),......
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More