

Information push method, device and system
An information push and pre-push technology, applied in the field of communications, can solve problems such as spam, and achieve the effect of avoiding spam and improving accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0033] The technical solutions in the embodiments of the present invention will be clearly and completely described below in conjunction with the accompanying drawings in the embodiments of the present invention. It should be understood that the described embodiments are only some of the embodiments of the present invention, not all of them. example. Based on the embodiments of the present invention, all other embodiments obtained by persons of ordinary skill in the art without making creative efforts belong to the protection scope of the present invention.
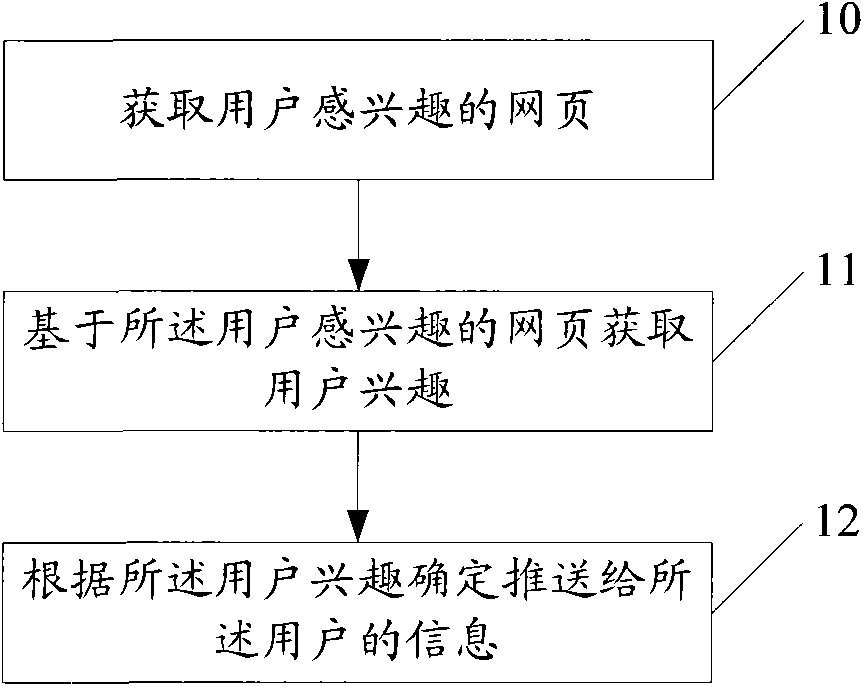
[0034] An embodiment of the present invention provides an information push method, including the following steps:
[0035] Obtain the web pages that the user is interested in;
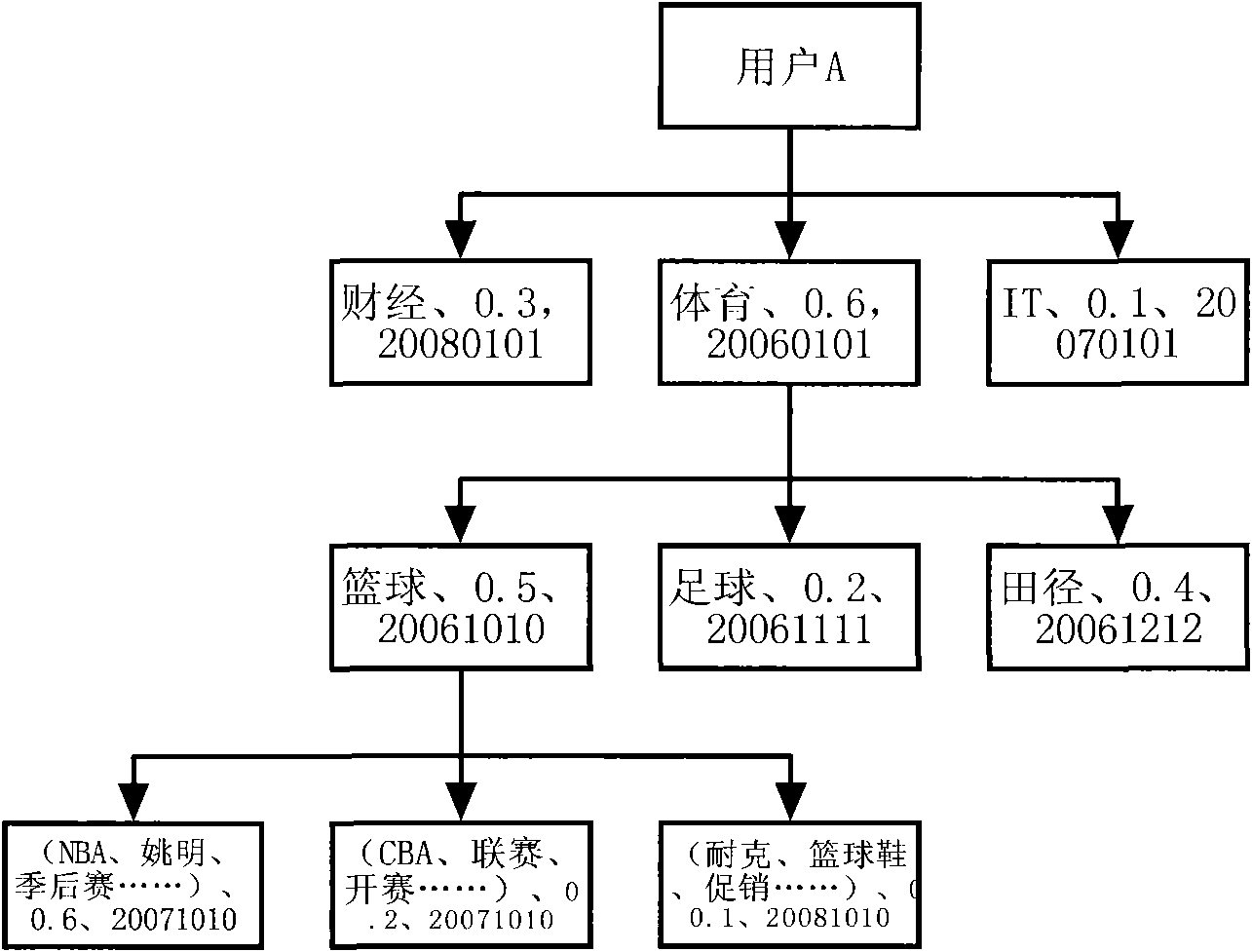
[0036] Acquiring user interests based on the webpages the user is interested in;
[0037] The information to be pushed to the user is determined according to the user interest.
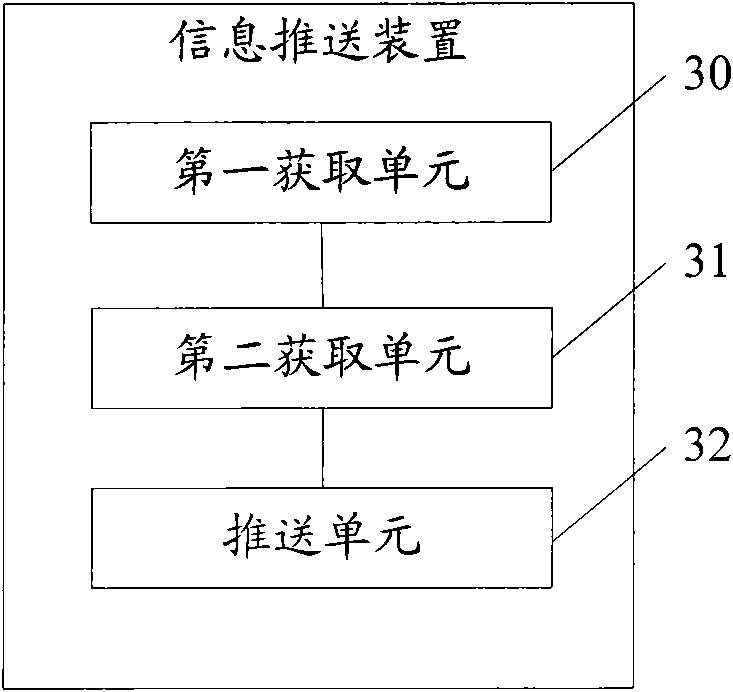
[0038] The information pushing method provided by the embodiment ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More