

Clustering method and system aiming at massive similar short texts
A short text and text technology, applied in the field of clustering and system for massive similar short texts
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
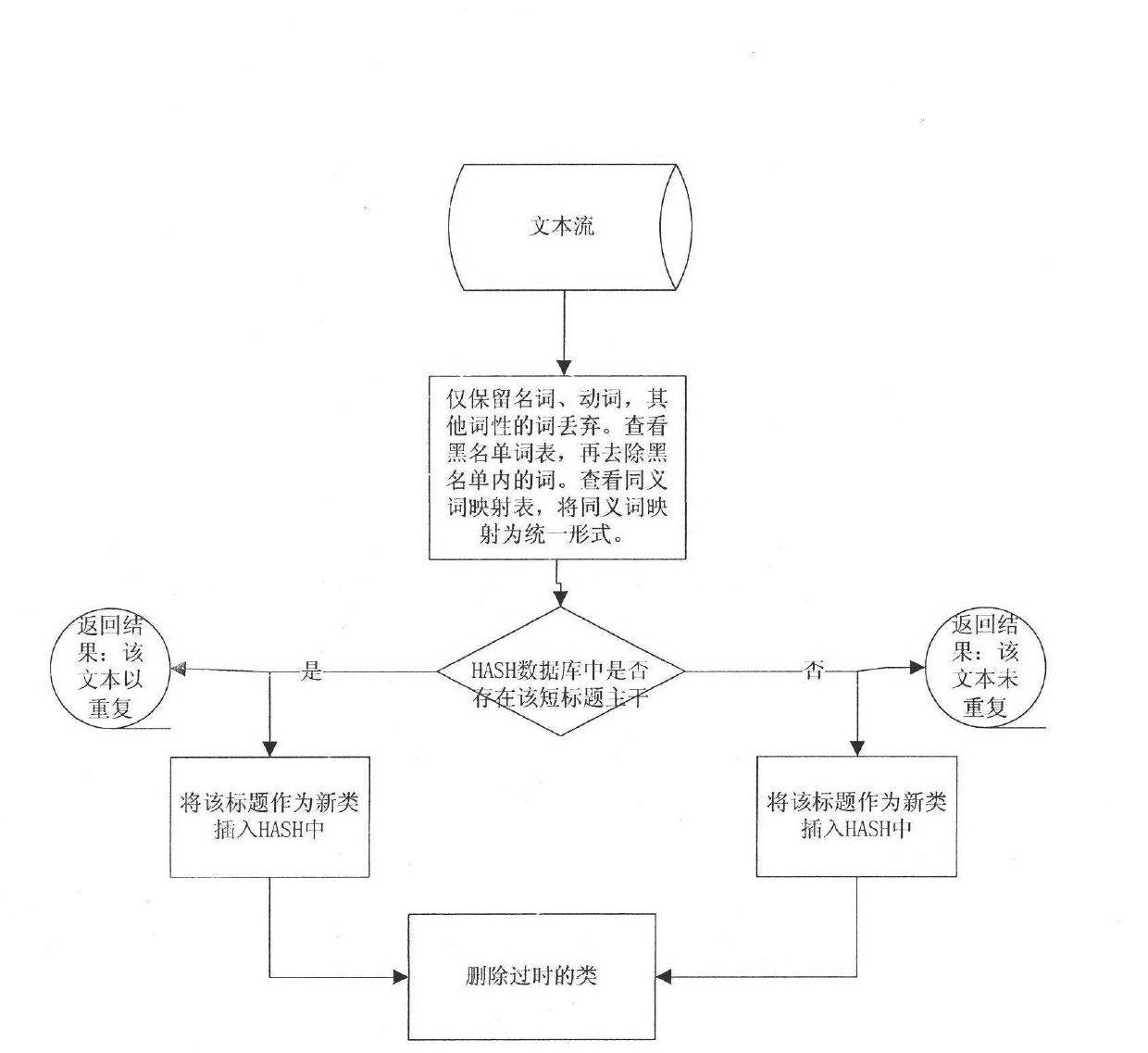
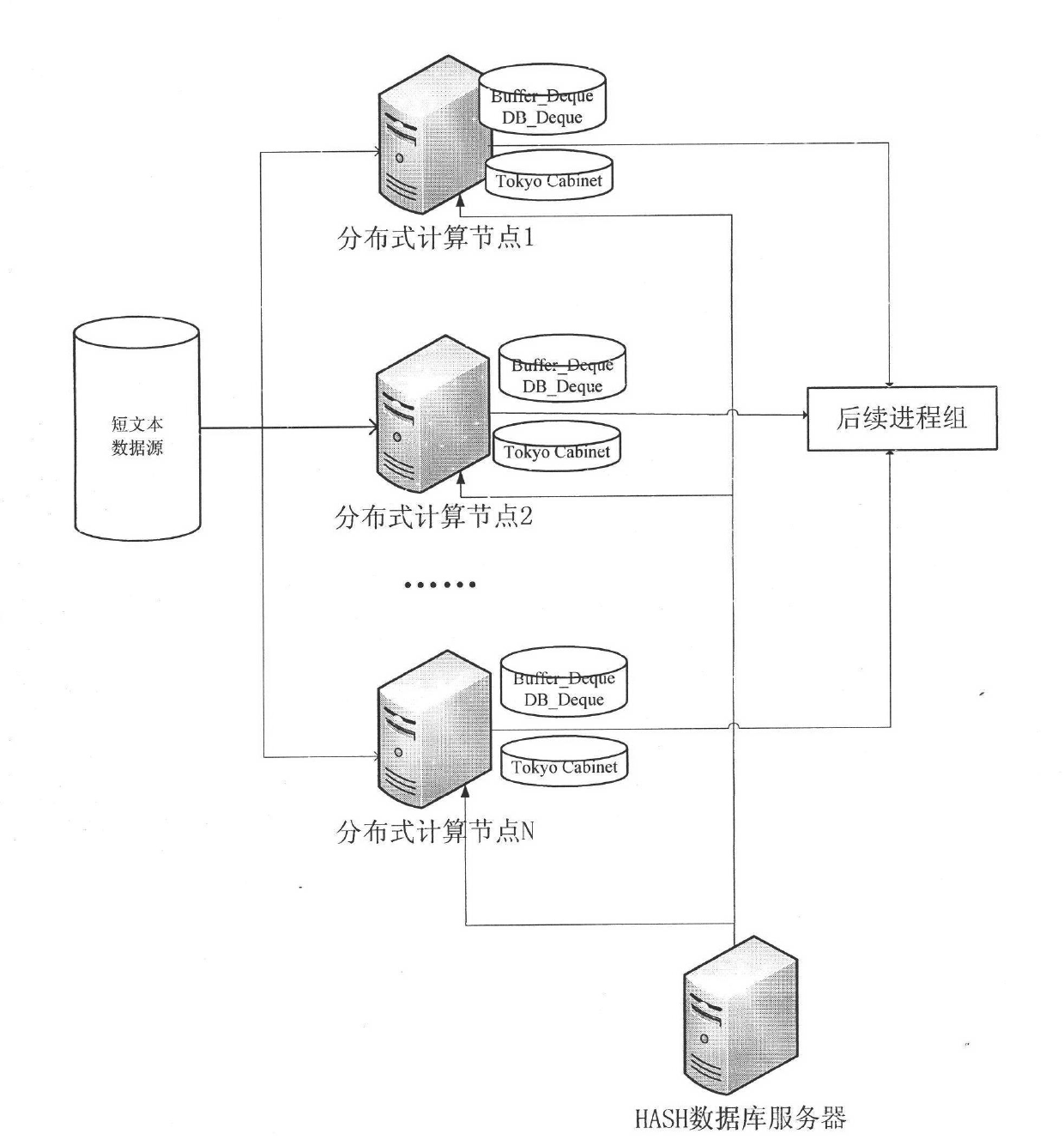
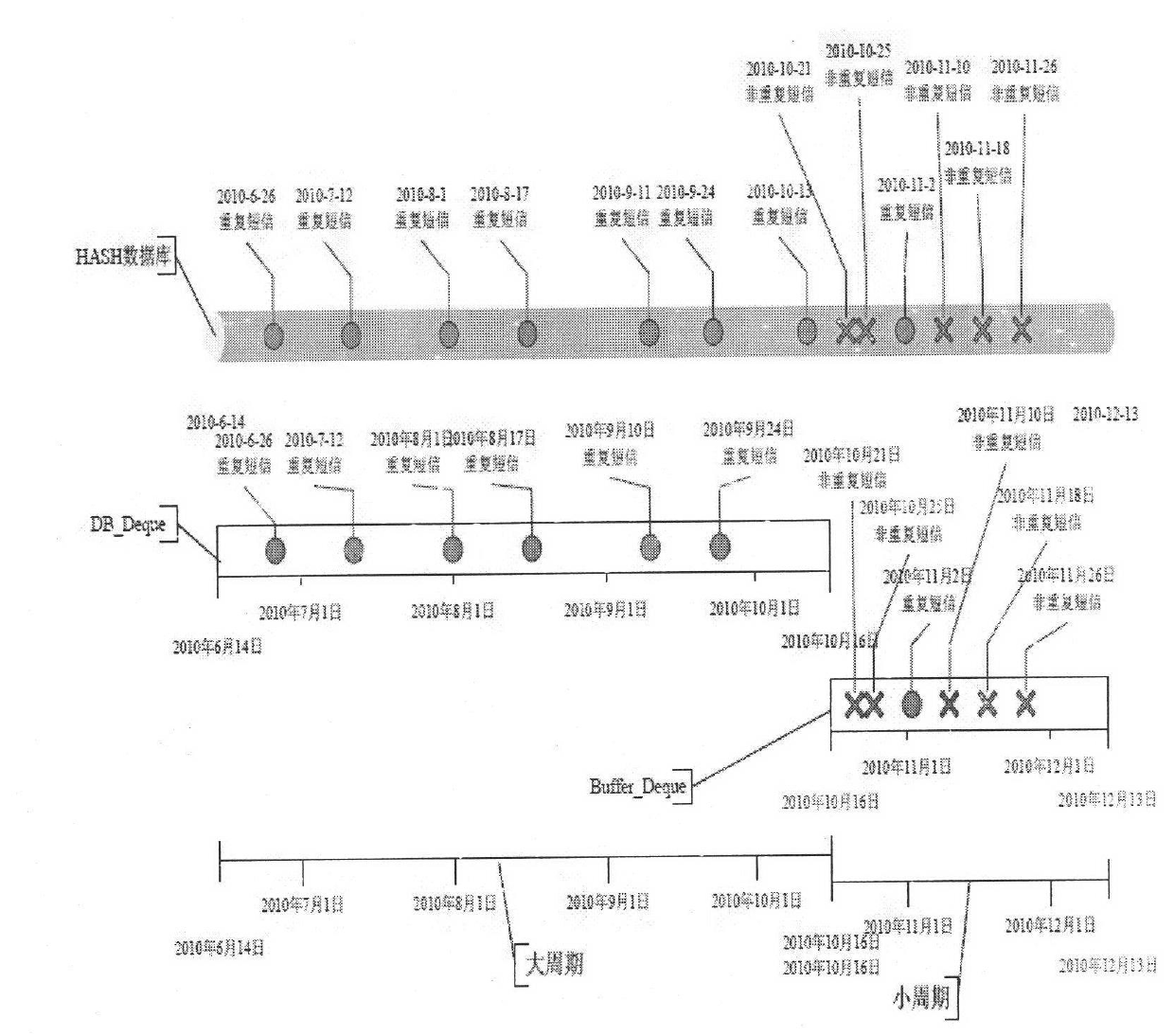
[0039] In order to process massive network data, the above solutions must be deployed in a distributed manner. Each distributed processing node obtains data from the short text data source, and after extracting the short text trunk, communicates with the HASH database server, and searches the short text trunk in the HASH database to determine whether the short text is repeated. The number of such short texts is updated in the local TokyoCabinet HASH table, and the processing results are transmitted to subsequent processes for further processing. At the same time, in order to improve the processing speed, two cache structures of BUFFER_DEQUE and DB_DEQUE are used on each processing node to make a secondary cache for the repeated text category information in the HASH server.
[0040] 1. The structure needs to be explained
[0041] 1) The reason why the processing node sets the cache
[0042] In order to ensure high read performance of the hash server, it is very important to l...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More