

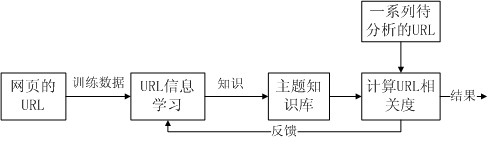
Method for implementing topical crawler system based on learning URL string information
A technology of character string information and topic crawler, which is applied in the direction of electrical digital data processing, special data processing applications, instruments, etc. Effects of Computational Complexity
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
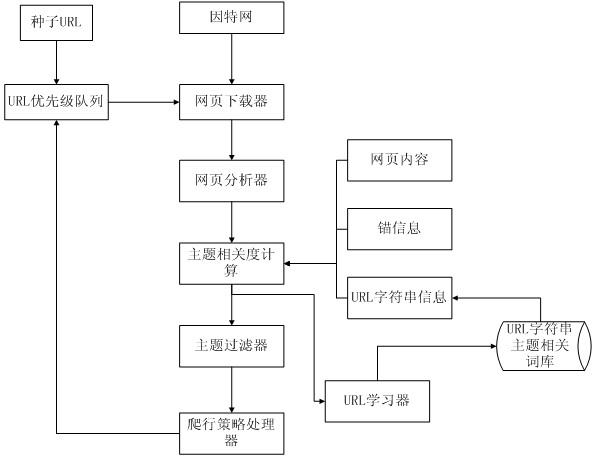
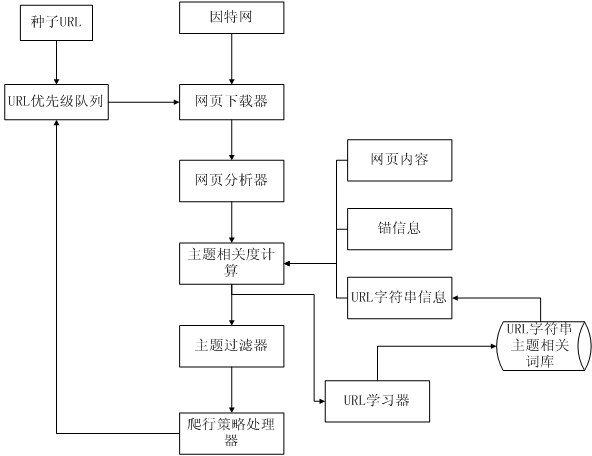
[0026] Below in conjunction with accompanying drawing and specific implementation application process, the present invention is further described:
[0027] refer to figure 1 Execute steps to illustrate the implementation process of the present invention:
[0028] Step 1 - Select the torrent URL:
[0029] According to a given topic, combined with machine learning and manual selection, the URLs of K webpages related to the topic are selected as seed URLs, and the webpage downloader starts to download webpages from the seed URLs.
[0030] Step 2 - Analyze the download page:
[0031] The webpage analyzer analyzes the downloaded webpage content and links, and extracts URL string information, webpage content, and anchor information of the webpage.
[0032] Step 3 - Calculation of topic relevance:
[0033] 1) Correlation calculation model:
[0034] The topic correlation calculation model adopts the space vector model as follows:
[0035] (1)
[0036] in Indicates the w...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More