

Image noisy point detection method based on convolution neural network
A technology of convolutional neural network and detection method, applied in biological neural network models, image enhancement, image data processing, etc., can solve problems such as limited functions, achieve accurate detection results and improve learning accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0018] In order to make the technical problems, technical solutions and beneficial effects to be solved by the present invention clearer and clearer, the present invention will be further described in detail below in conjunction with the accompanying drawings and embodiments. It should be understood that the specific embodiments described here are only used to explain the present invention, not to limit the present invention.
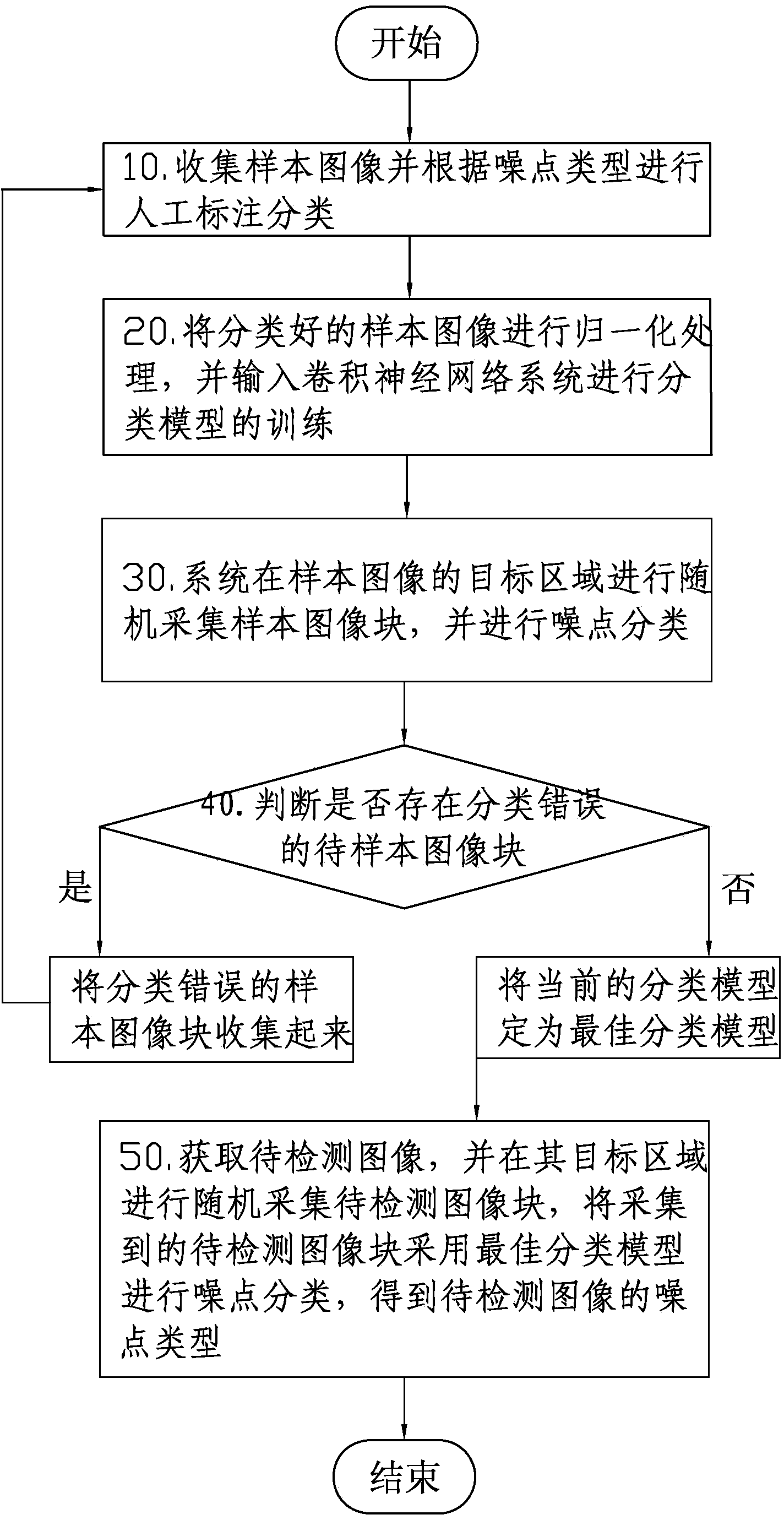
[0019] Such as figure 1 Shown, a kind of image noise detection method based on convolutional neural network of the present invention, it comprises the following steps:
[0020] 10. Collect sample images and perform manual labeling and classification according to noise types;
[0021] 20. Normalize the classified sample images and input them into the convolutional neural network system to train the classification model;
[0022] 30. The system randomly collects sample image blocks in the target area of the sample image, and performs noise classificat...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More