

Visual feature representing method based on autoencoder word bag
An autoencoder and visual feature technology, applied in neural learning methods, instruments, biological neural network models, etc., can solve problems such as overfitting, difficulty in learning effective features, and difficulty in discovering data structures. Applicability, practicality, simple and feasible effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0035] A method for representing visual features based on an autoencoder bag-of-words of the present invention will be described in detail below with reference to the embodiments and the accompanying drawings.
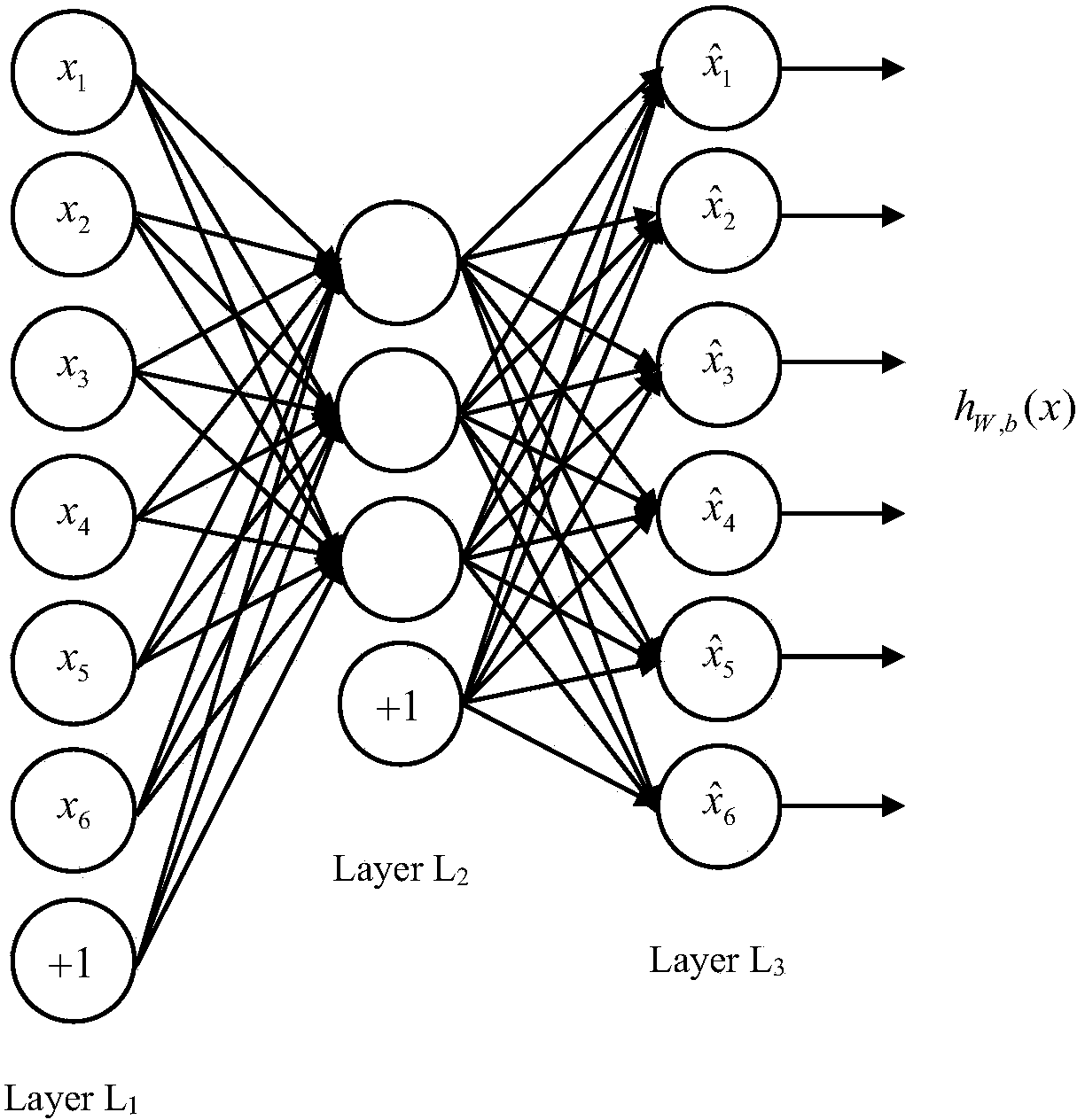
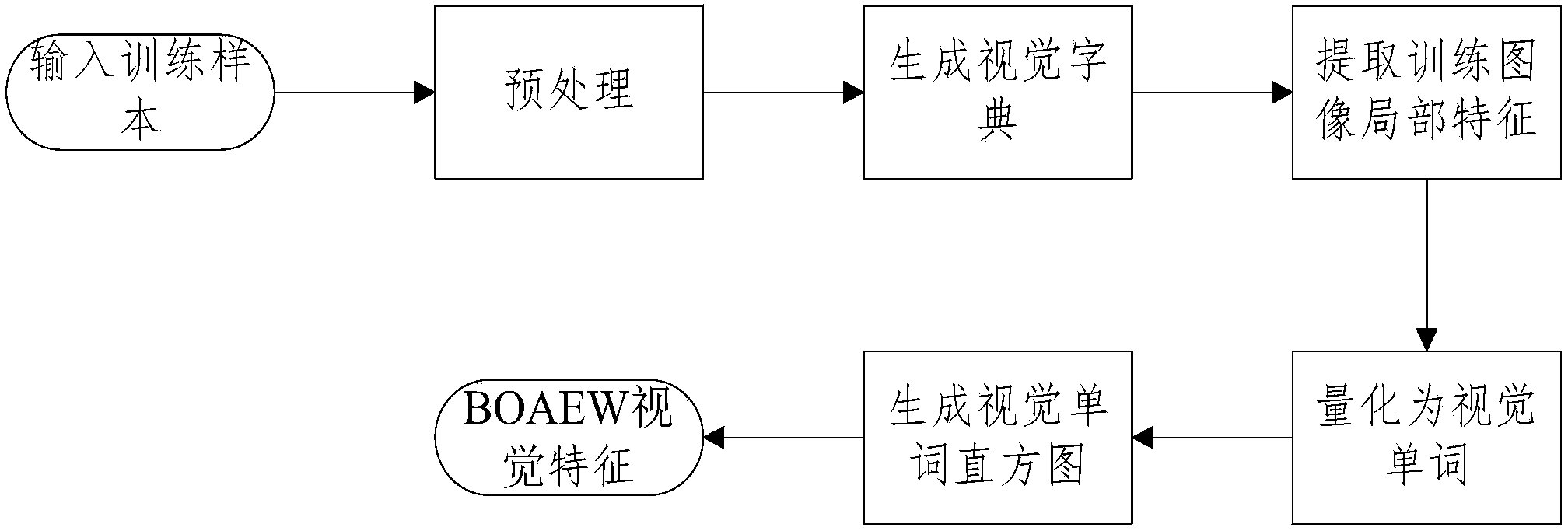
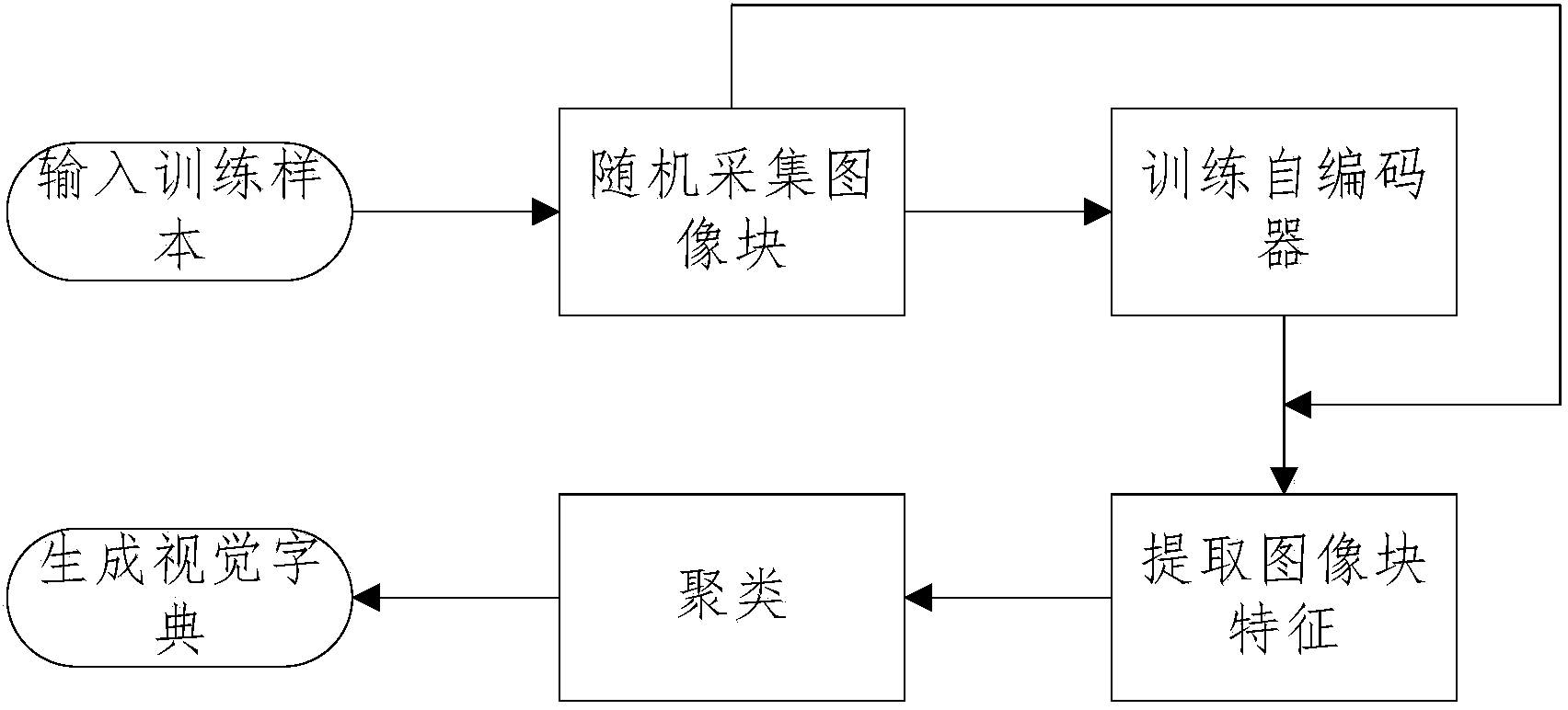
[0036] A visual feature representation method based on an autoencoder bag of words of the present invention is mainly based on a traditional feature representation method based on a visual bag of words, and uses an autoencoder in unsupervised learning to extract local features of an image for the first time. To replace the manually designed feature, the present invention calls the visual feature representation method based on the autoencoder word bag Bag of Autoencoder Words (BOAEW). BOAEW combines the bag-of-visual-words framework and unsupervised feature learning methods to improve feature representation capabilities.
[0037] In supervised learning, the training samples are labeled with categories. In contrast, in unsupervised learning, the training set has no categ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More