

Method for extracting chapter-level parallel phrase pair of comparable corpus based on parallel corpus training
A parallel corpus and phrase pair technology, applied in the field of chapter-level phrase translation pair extraction, can solve the problems of scarce data resources, dependence on bilingual dictionaries, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image



Examples
specific Embodiment approach 1
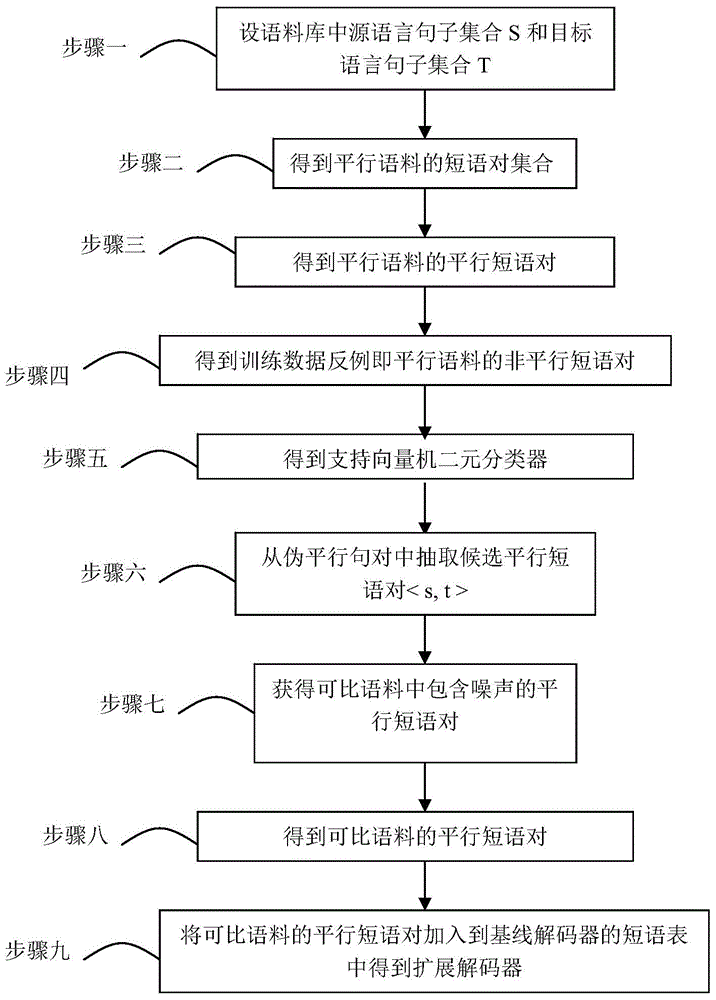
[0030] Specific implementation mode one: a kind of method for extracting parallel phrase pairs based on parallel corpus training based on parallel corpus in this embodiment is specifically prepared according to the following steps:
[0031] Step 1, set the source language sentence set S and the target language sentence set T in the corpus; wherein, the corpus includes parallel corpus and comparable corpus;
[0032] Step 2, respectively divide S and T into phrases according to the specified length, the length of the phrase is 2-7 words, and the divided phrases are combined in pairs to obtain all the phrase pair sets of the parallel corpus; wherein, each phrase pair must contain a phrase from S and a phrase from T;
[0033] Step 3, use the GIZA++ tool to extract the two-way word translation table from the parallel corpus, and use the parallel corpus to establish a phrase-based statistical machine translation system in the Moses system to obtain that most of the phrases contained...
specific Embodiment approach 2
[0054] Specific embodiment 2: The difference between this embodiment and specific embodiment 1 is that in step 3, the specific process of extracting positive examples of training data (marking of positive examples) is as follows:
[0055] (1) Let S k is the word at the k'th position in the source language sentence set S, is the sequence of words from position i to position j in S and T k 'is the word at the k'th position in the target language sentence set T, is the word sequence from position i' to position j' in T; assume a threshold ε, ε∈(0,1);
[0056] (2) The threshold is selected based on experience and actual conditions. If the translation probability of two words in the two-way word translation table is greater than the threshold ε, the two words S k with T k' are mutual translations;
[0057] (3) If and only if S k with T k' When mutual translation is alignment, k∈[i,j] and k'∈[i',j'];
[0058] S k with T k' When there is no mutual translation or alignment...
specific Embodiment approach 3
[0060] Specific embodiment three: the difference between this embodiment and specific embodiment one or two is: in the step 5, extract classification features as follows from the parallel phrase pair of parallel corpus and the non-parallel phrase pair of parallel corpus respectively:
[0061] (1) Phrase length difference: it is the absolute value of the difference between the source language phrase and the target language phrase length;
[0062] (2) Same start: if the beginning of the source language phrase and the beginning of the target language phrase can be translated each other, the value is 1, otherwise the value is 0;
[0063] (3) Same ending: If the ending of the source language phrase and the ending of the target language phrase can be translated each other, the value is 1, otherwise the value is 0;
[0064] (4) The number of words in the phrase: it is the number of words contained in the source language phrase and the target language phrase respectively;
[0065] (5...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More