

Web text-based acquiring and screening method of seismic macroscopic anomaly information
A technology of abnormal information and screening method, applied in the field of text data mining, which can solve problems such as no general method proposed by no one, implementation difficulties, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0118]下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。
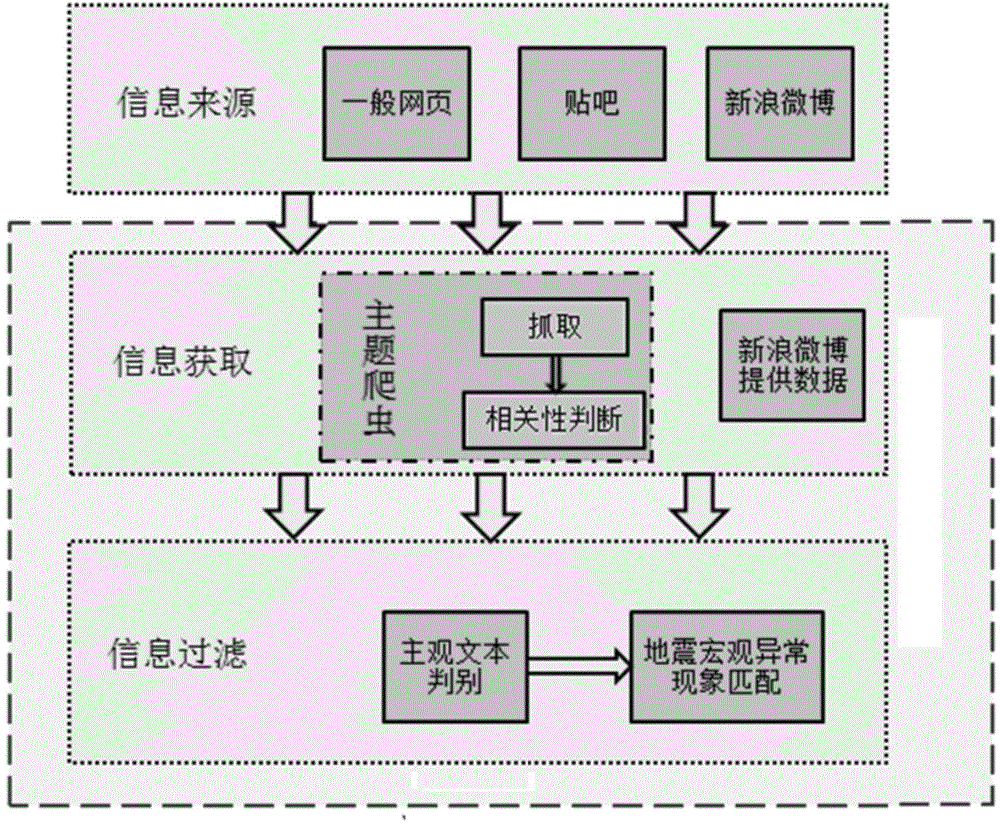
[0119]本发明提供一种基于网络文本的地震宏观异常信息获取与筛选方法,用于抓取地震主题网络文本并筛选出其中的地震宏观异常相关信息。
[0120]如图1为基于网络文本的地震宏观异常信息获取与筛选方法的流程图。具体实现步骤如下:
[0121]步骤1,信息获取。
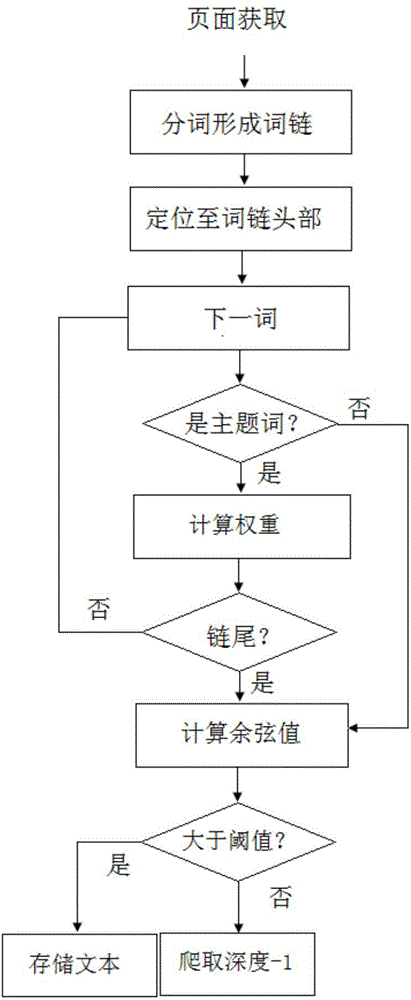
[0122](1)相关性判别
[0123]相关性判别是主题信息获取的第一个阶段,是主题信息获取的第一个阶段,主要工作是判断当前网络文本的主体相关性。页面内容主题相关性计算方法流程图如图2所示。对于贴吧的帖子列表页面和微博的关键词搜索页面,不需计算该页面的主题相关性。余弦值的阈值设定为一般网页0.1,贴吧0.3,微博0.1。
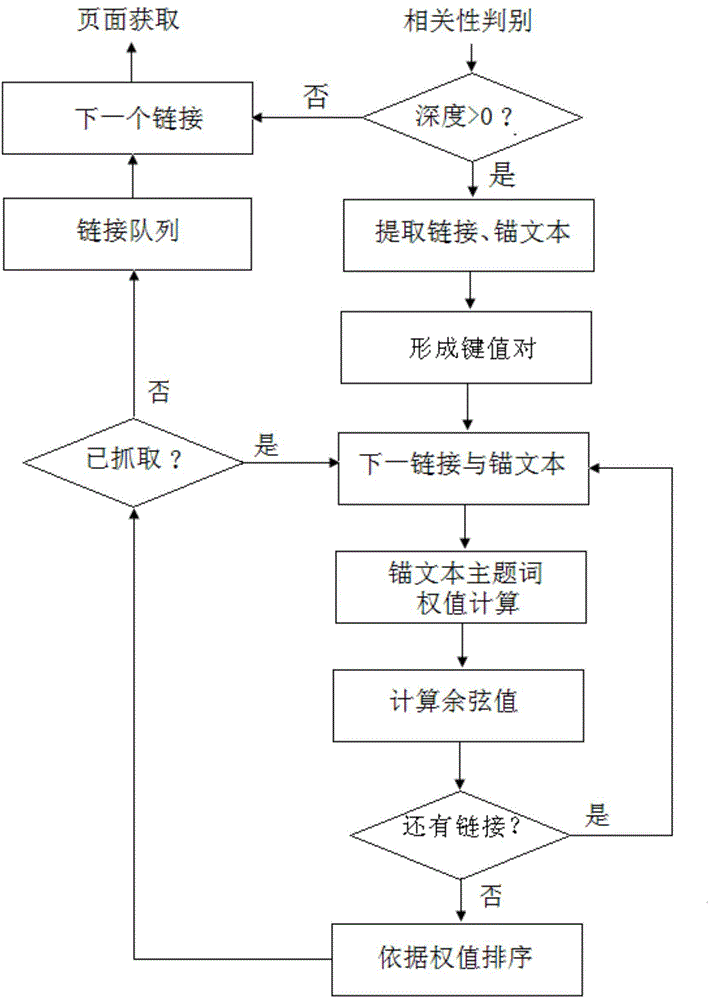
[0124](2)链接排序
[0125]链接排序是主题信息获取的第二步,主要工作是确定主题爬虫的优先性爬取策略。图3是页面内URL链接排序的实现流程,这是体现主题爬虫主题优先性抓取策略的地方。对于一般网页,计算余弦值时需要加入页面的余弦值作为上下文相关性,贴吧和微博页面不需要考虑这点。
[0126](3)信息抽取
[0127]信息抽取是主体信息获取的第三步,主要工作是从主题相关的网络文本页面中定位并抽取出具体的地震宏观异常信息。图4是信息抽取算法流程,其中贴吧和微博结构固定,利用正则表达式可以很方便的提取。
[0128]经过上述步骤,本发明实现了从网络文本获取地震宏观异常相关信息,能够使用主题相关判别和优先策略实现网络信息爬取。该方法能够针对一般网页、论坛(百度贴吧)和社交网络(新浪微博)进行地震宏观异常主题信息提取。
[0129]步骤2,信息筛选。
[0130](1)主观句判别。
[0131]图5是判断主观句的实现流程,根据贝叶斯公式计算似然指数,似然指数大于1时,认为此句属于主观句。
[0132](2)文本主观性判别。
[0133]图6为判断文本主观性的实现过程,主观性判别的阈值为0.5。
[0134](3)地震宏观异常匹配。
[0135]图7为地震宏观异常匹配方法流程。从主题相关并根据主观性进行过滤后的网络文本中进行事物主体词和行为词的匹配进而得出地震宏观异常信息。
[0136]本实施例基于Heritrix框架,应用地震宏观异常主题描述词组,分别针对一般网页、贴吧和社交网络三种信息来源定制...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More