

Chi square statistic based self-adaption feature selection method
A feature selection method and self-adaptive technology, applied in computing, special data processing applications, natural language data processing, etc., can solve the problem of unsatisfactory classification effects, failure to consider the positive and negative correlation between feature items and categories, and enlarge weights, etc. question
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

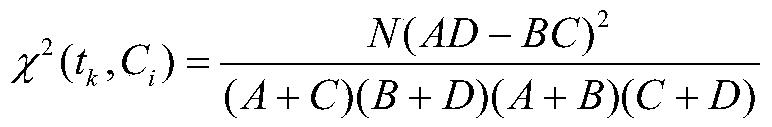
Examples
Embodiment Construction
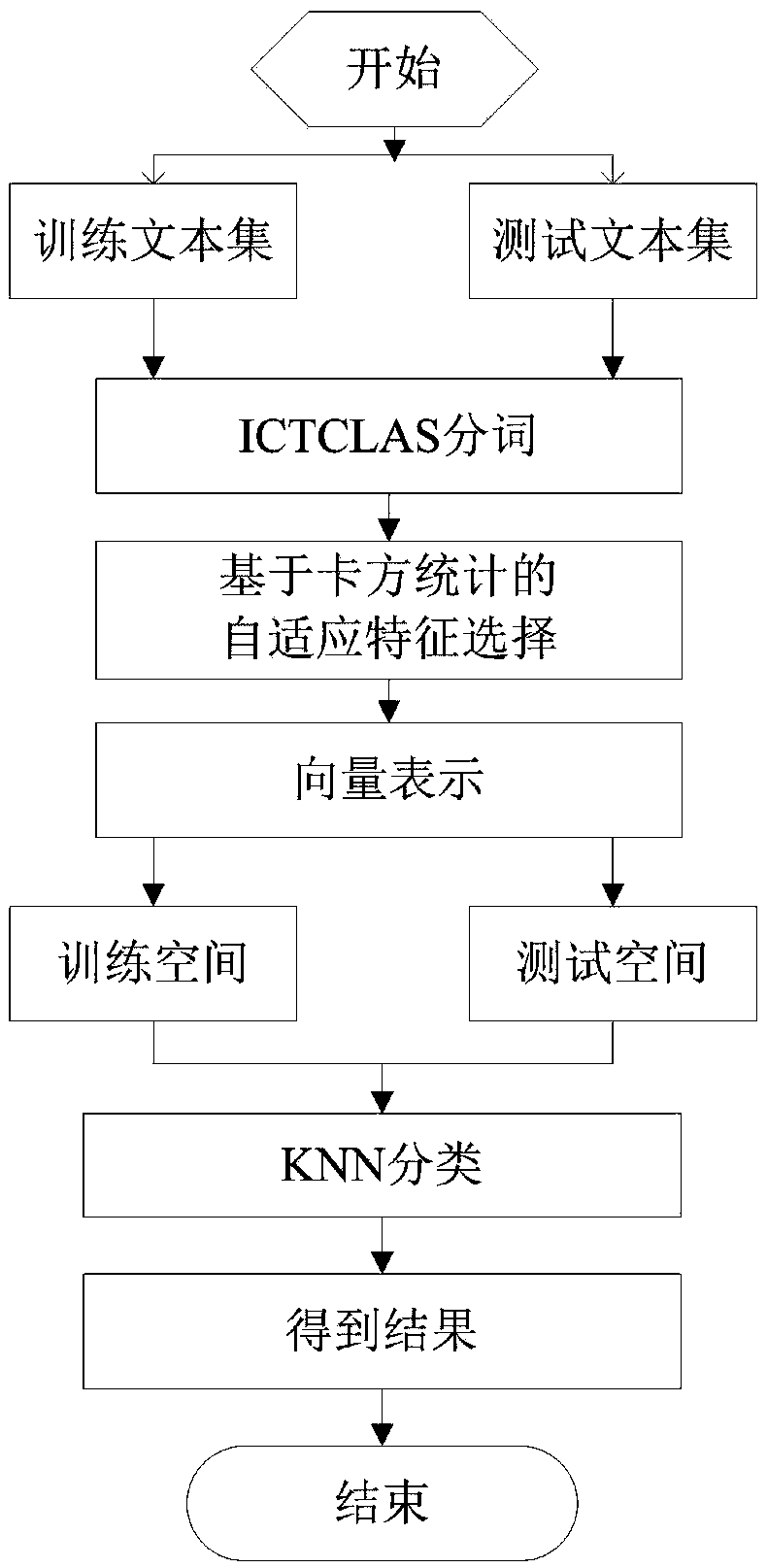
[0043] The present invention is realized by adopting the following technical means:
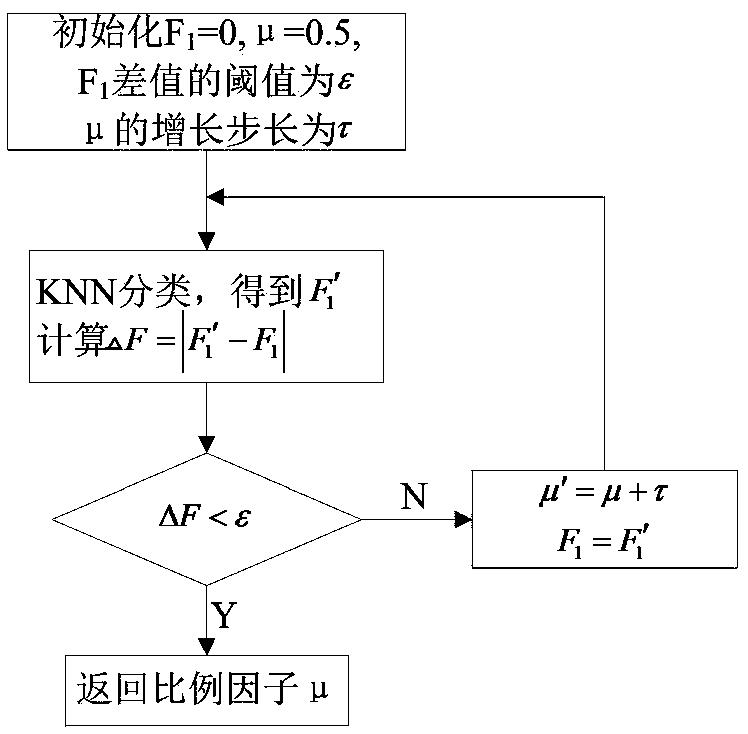
[0044] An adaptive text feature selection method based on chi-square statistics. First, preprocess the training text set and test text set, including word segmentation and stop word processing. Second, perform adaptive text feature selection based on chi-square statistics, define word frequency factor α and inter-class variance β, and introduce them into CHI Algorithm, adding an appropriate scale factor μ to the CHI algorithm, and finally, combined with the classic KNN algorithm, automatically adjusts the scale factor μ to make the improved CHI applicable to different corpora to ensure higher classification accuracy.
[0045] The above-mentioned adaptive text feature selection method based on chi-square statistics is used for text classification, including the following steps:
[0046] Step 1, download the Chinese corpus released by Fudan University from the Internet - the training text set ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More