Text clustering method based on random neighbor embedding
A technology of random nearest neighbor embedding and text clustering, which is used in text database clustering/classification, unstructured text data retrieval, special data processing applications, etc., and can solve problems such as high clustering accuracy, fast running speed, and slow running
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment
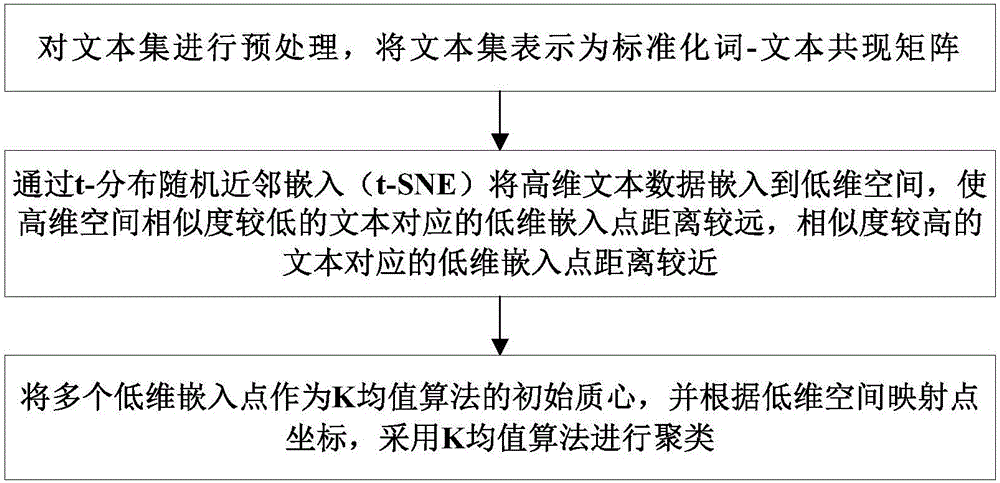
[0039] like figure 1 As shown, a text clustering method based on random neighbor embedding includes the following steps:
[0040] S01: Preprocessing the text set, expressing the text set as a standardized word-text co-occurrence matrix;
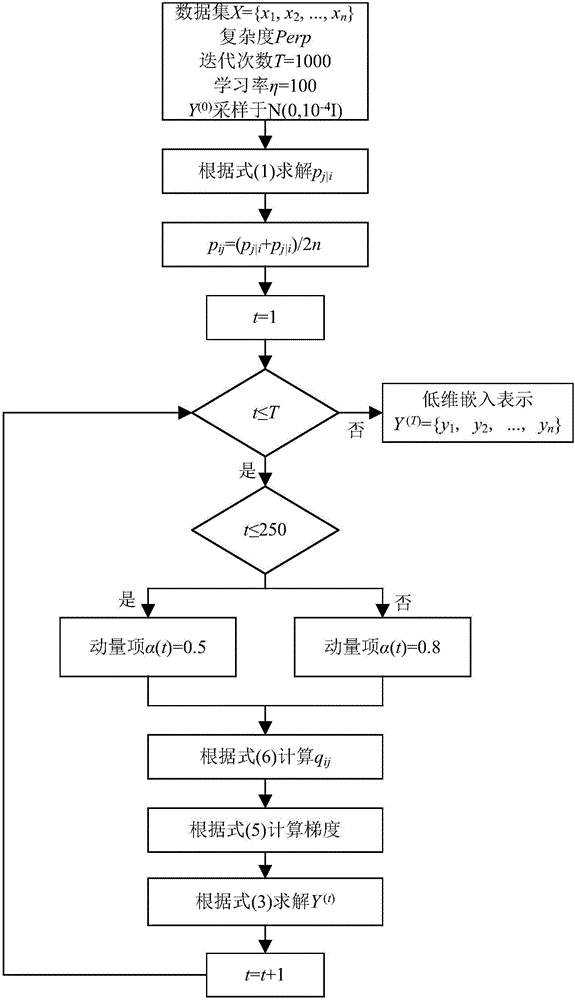
[0041] S02: Embed high-dimensional text data into low-dimensional space through t-distributed stochastic neighbor embedding (t-SNE), so that the distance between the low-dimensional embedding points corresponding to the text with low similarity in high-dimensional space is relatively far, and the text with high similarity is relatively far away. The low-dimensional embedding points corresponding to the text are relatively close;
[0042] S03: Use multiple low-dimensional embedded points as the initial centroid of the K-means algorithm, and use the K-means algorithm for clustering according to the low-dimensional space mapping point coordinates.
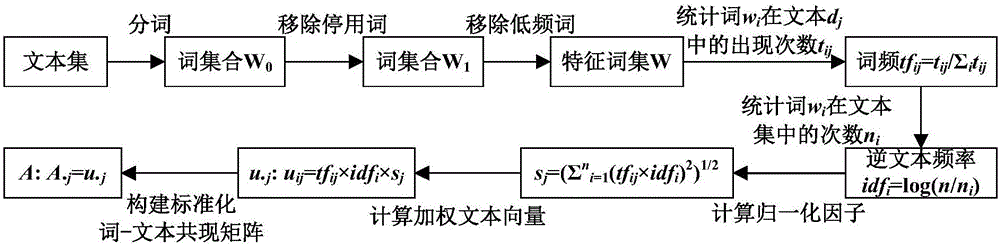
[0043] The construction of standardized word-text co-occurrence matrix is as follows: figur...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com