Method and apparatus for quickly searching for contents required to be queried
A content and fast technology, applied in the field of search engines, can solve the problems of wide data sources, limited search features, and many repeated content, and achieve the effect of efficient and accurate query, high matching efficiency, and good user experience
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


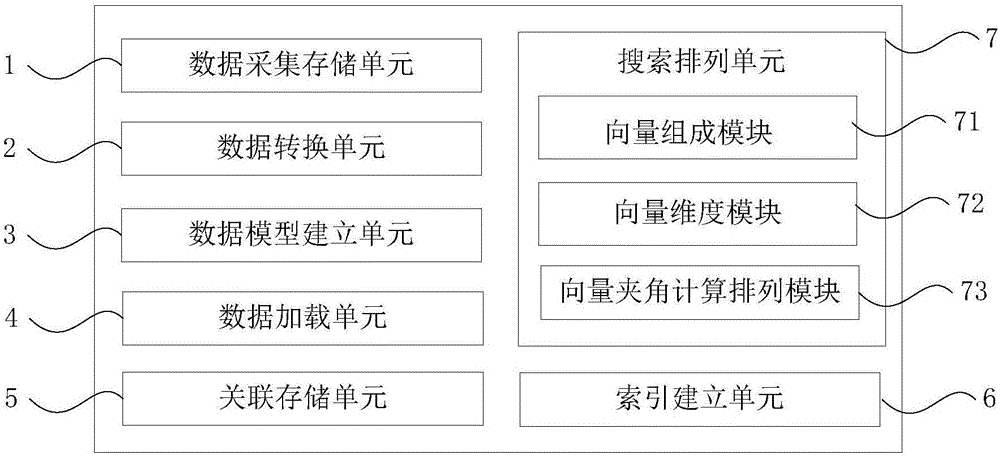
Examples
Embodiment Construction
[0047] The following will clearly and completely describe the technical solutions in the embodiments of the present invention with reference to the accompanying drawings in the embodiments of the present invention. Obviously, the described embodiments are only some, not all, embodiments of the present invention. Based on the embodiments of the present invention, all other embodiments obtained by persons of ordinary skill in the art without making creative efforts belong to the protection scope of the present invention.
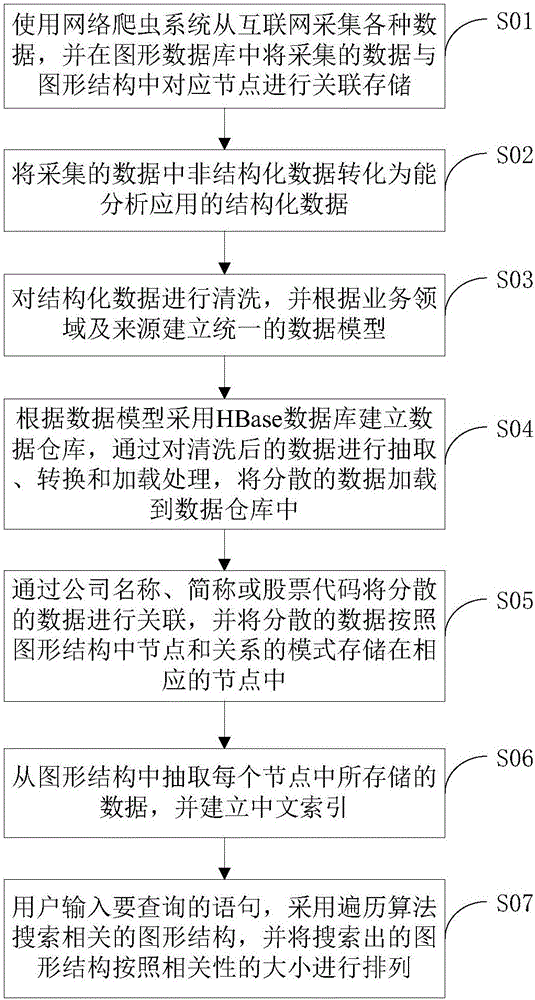
[0048] In the embodiment of the method and device for quickly searching the content to be queried in the present invention, the flow chart of the method for quickly searching the content to be queried is as follows figure 1 shown. figure 1 In , the method for quickly searching for the content to be queried includes the following steps:
[0049] Step S01 uses the web crawler system to collect various data from the Internet, and associates the collected data wi...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More 
PatSnap Eureka turns technology decisions into work you can execute. Powered by our Innovation Knowledge Graph, it runs expert workflows across engineering, life sciences, materials and intellectual property. Get your review-ready output in minutes.



