

Improved Kmeans clustering method based on SimHash
A kmeans clustering and clustering technology, which is applied in the field of computer networks, can solve problems such as difficulty in guaranteeing clustering quality, high computational overhead, and long time consumption
Active Publication Date: 2017-04-05
CHINA INTERNET NETWORK INFORMATION CENTER
View PDF2 Cites 11 Cited by
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
The clustering problem is a typical partition-based problem. The simplest and most commonly used algorithm in the partition-based clustering algorithm is the Kmeans clustering algorithm, but the pure Kmeans algorithm has two obvious disadvantages: one is that it needs to Specify the number of clusters beforehand; if the number of clusters is not known in advance, the clustering quality is difficult to guarantee; second, it is necessary to iteratively calculate the centroid. When the sample data is large, not only the calculation cost is large but also time-consuming , cannot be applied to large amounts of data
Method used
the structure of the environmentally friendly knitted fabric provided by the present invention; figure 2 Flow chart of the yarn wrapping machine for environmentally friendly knitted fabrics and storage devices; image 3 Is the parameter map of the yarn covering machine
View moreImage
Smart Image Click on the blue labels to locate them in the text.
Smart ImageViewing Examples


Examples
Experimental program
Comparison scheme
Effect test
specific Embodiment
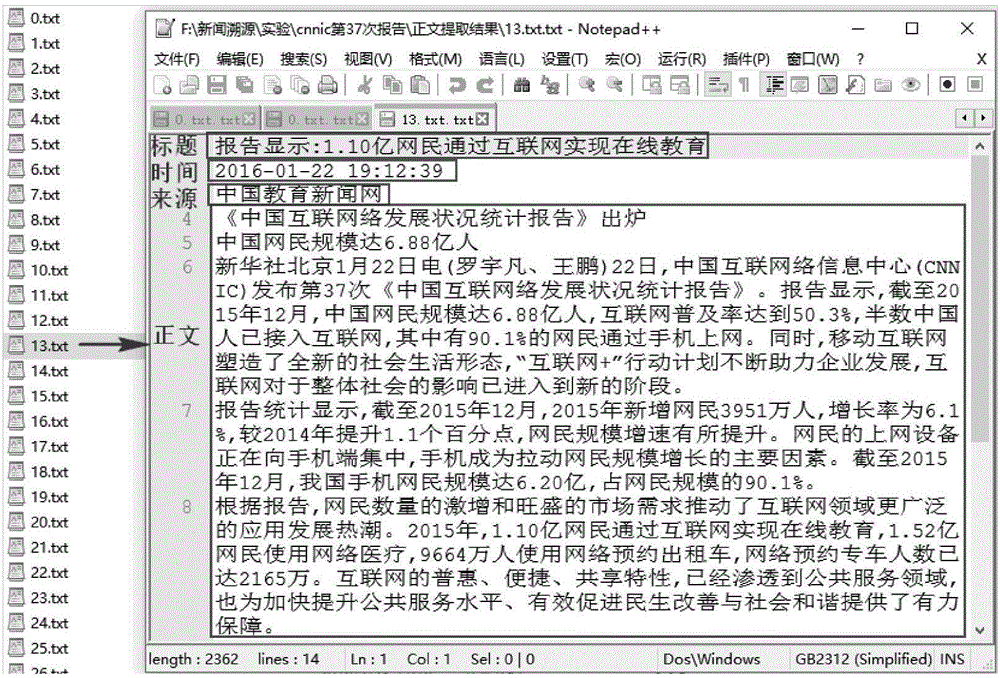
[0053] The text of the key information of the news web pages to be clustered exists in the local folder in the text file format (.txt), such as figure 1 As shown in , the text content format of key news information is: title, time, source and text, and the four are separated by newlines.
[0054] Specify the directory of the files to be clustered, run the improved Kmeans clustering algorithm, and generate "xxx_cluster_result.txt", the file format is: cluster label\tpage number in the cluster (page numbers are separated by spaces), and the clustering result file is as follows figure 2 shown.
the structure of the environmentally friendly knitted fabric provided by the present invention; figure 2 Flow chart of the yarn wrapping machine for environmentally friendly knitted fabrics and storage devices; image 3 Is the parameter map of the yarn covering machine
Login to View More PUM
 Login to View More
Login to View More Abstract
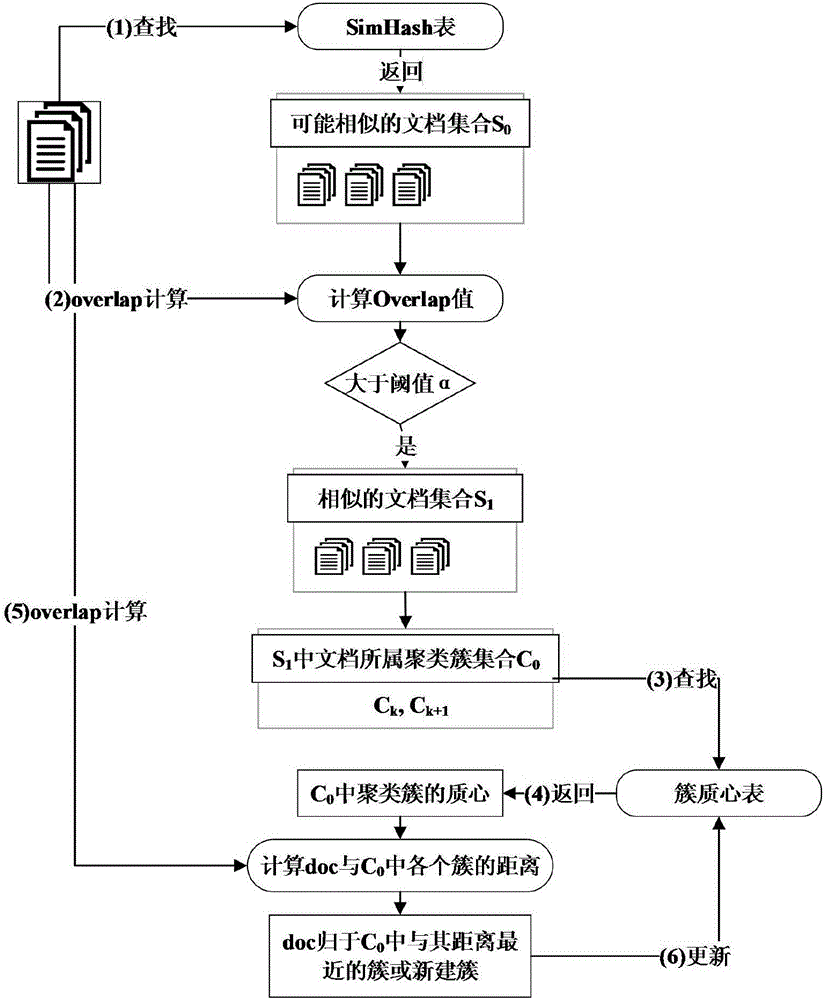
The invention discloses an improved Kmeans clustering method based on SimHash. The method includes the following steps: 1. using the SimHash algorithm to compute the fingerprint of each to-be-clustered file, generating one SimHash table; 2. selecting one to-be-clustered file, based on the fingerprint of the file, checking the SimHash table to obtain one similar file set S0; 3. putting the files from the S0 that have an Overlap value with the to-be-clustered file greater than a threshold [alpha] to a similar file S1; 4. back to a cluster C0 belonged to the S1, computing the distances between the to-be-clustered file and the centers of mass of all clusters in the C0, classifying the to-be-clustered file to a cluster I which is closest to the to-be-clustered file and smaller than the threshold and updating the center of mass of the cluster I, or creating a new cluster k, and taking the to-be-clustered file as a first element of the cluster k; if C0 is empty, creating a cluster j, taking the to-be-filed cluster as a first element of the cluster j. According to the invention, the method increases the effects of clustering.
Description
technical field [0001] The invention relates to an improved Kmeans clustering method based on SimHash, belonging to the technical field of computer networks. Background technique [0002] In today's era of explosive growth of Internet information, deduplication and clustering of information, as an important technical means, has been researched and favored by more and more scholars. The deduplication and clustering of text information is an important part of it. Therefore, the present invention only involves deduplication and clustering of text information. The clustering of text information mainly involves two aspects: the first is the text representation mode, that is, what to use to represent the text; the second is to choose the appropriate clustering algorithm. At present, there are many kinds of text representation modes, and the popular ones are Vector Space Model (VSM), probability model, language model, etc.; similarly, in the selection of clustering algorithm, the...
Claims
the structure of the environmentally friendly knitted fabric provided by the present invention; figure 2 Flow chart of the yarn wrapping machine for environmentally friendly knitted fabrics and storage devices; image 3 Is the parameter map of the yarn covering machine
Login to View More Application Information
Patent Timeline
 Login to View More
Login to View More IPC IPC(8): G06K9/62
CPCG06F18/23211
Inventor李晓东向菁菁耿光刚
OwnerCHINA INTERNET NETWORK INFORMATION CENTER