Method and device for constructing visual webpage information extracting rule
A technology for web page information and page information, which is applied in network data retrieval, network data indexing, special data processing applications, etc. The difficulty of maintenance and the effect of improving construction efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
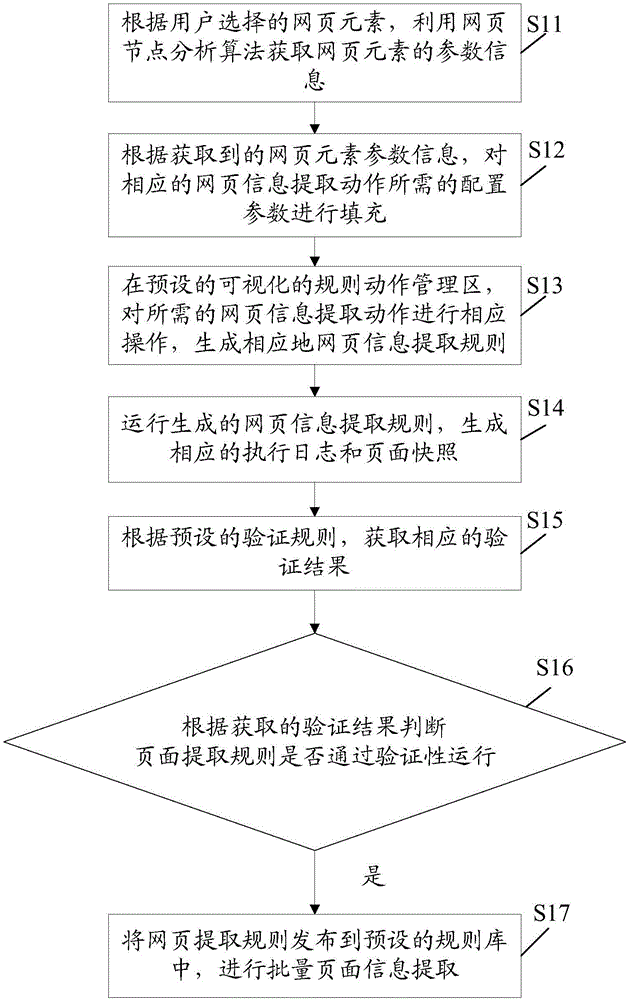
[0044] The embodiment of the present invention provides a method for constructing a visualized web page information extraction rule, see figure 1 , the method can include:
[0045] Step S11, according to the web page element selected by the user, use the web page node analysis algorithm to obtain the parameter information of the web page element, the parameter information may include: xpath, attribute, and text value of the web page element.
[0046] In this embodiment, the web page elements include the web page information that the user wants to extract. xpath is Extensible Markup Language (Extensible Markup Language, referred to as "XML") path language, it is a language used to determine the location of a certain part of the XML document, xpath is based on the tree structure of XML, provides the search in the data structure tree node capabilities. In practical applications, using the webpage node analysis algorithm to obtain the xpath, attributes, and text values of webp...
Embodiment 2
[0075] An embodiment of the present invention provides a device for constructing a visual web page information extraction rule, which adopts the construction method of a visual web page information extraction rule described in Embodiment 1, see Figure 4 , the apparatus may include: a first acquiring module 100 , a processing module 200 , and a first generating module 300 .
[0076] The first acquiring module 100 is configured to acquire parameter information of the webpage element by using a webpage node analysis algorithm according to the webpage element selected by the user, and the parameter information includes: xpath, attribute, and text value of the webpage element.
[0077] In this embodiment, the web page elements include the web page information that the user wants to extract. XPath is an XML path language, which is a language used to determine the location of a certain part of an XML document. Based on the tree structure of XML, xpath provides the ability to find no...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com