Triggering way and device of promoting key words
A keyword and keyword library technology, applied in the field of search, can solve the problems of low accuracy and recall rate of triggering promotion keywords, and achieve the effect of improving the accuracy rate and the recall rate.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

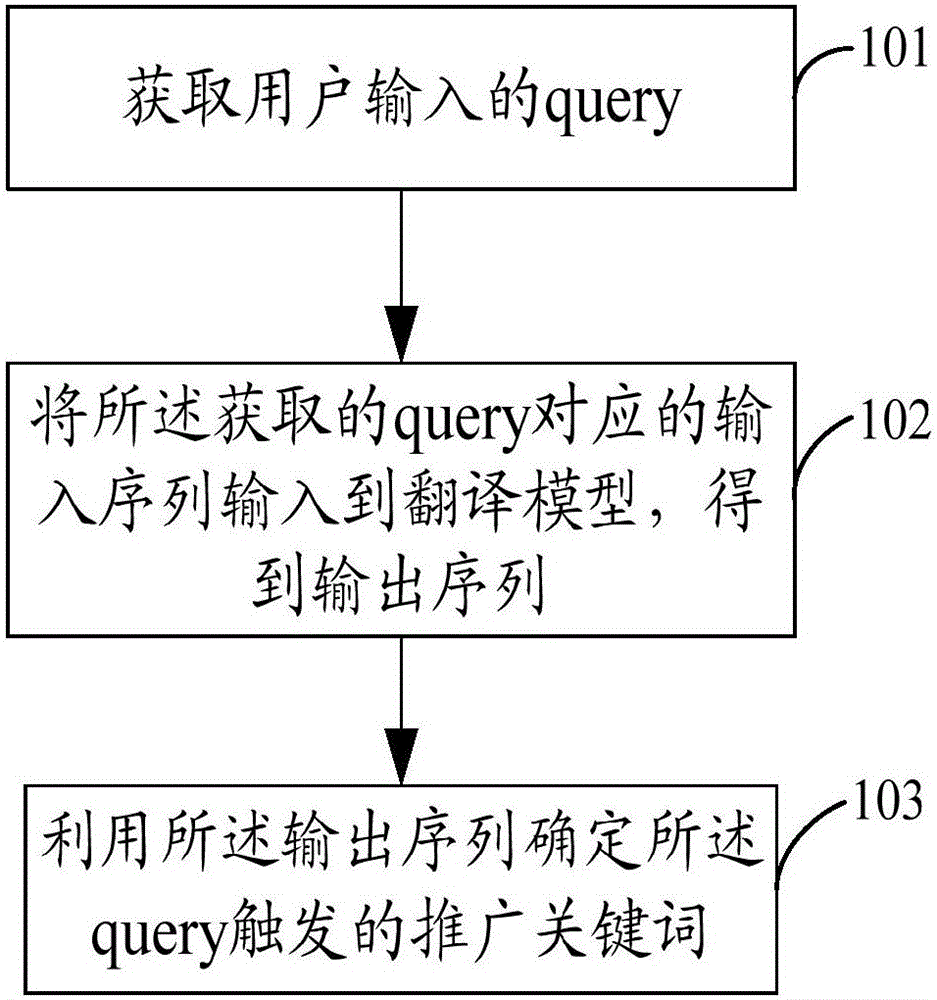
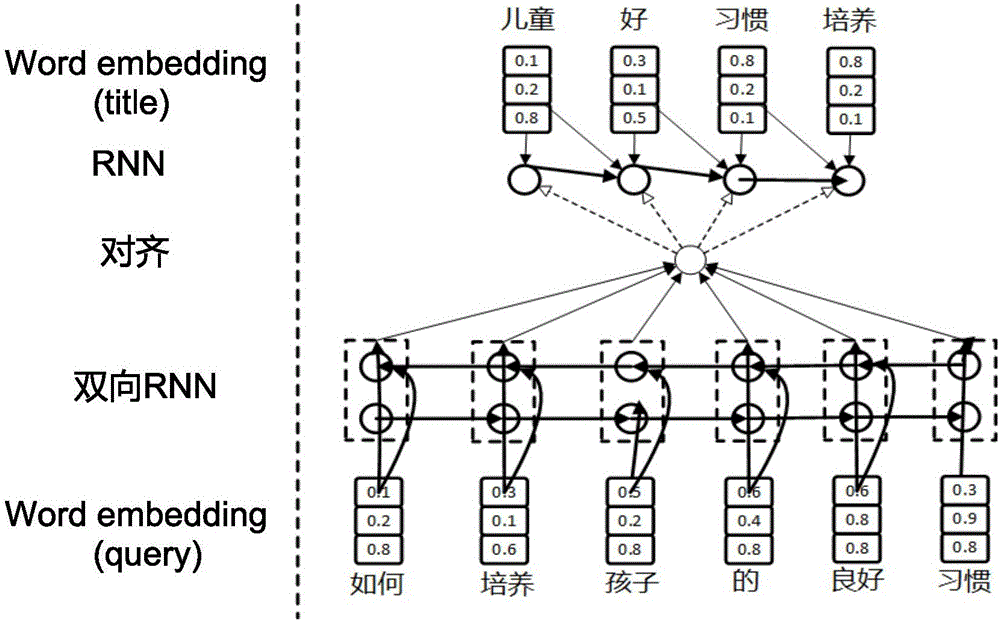
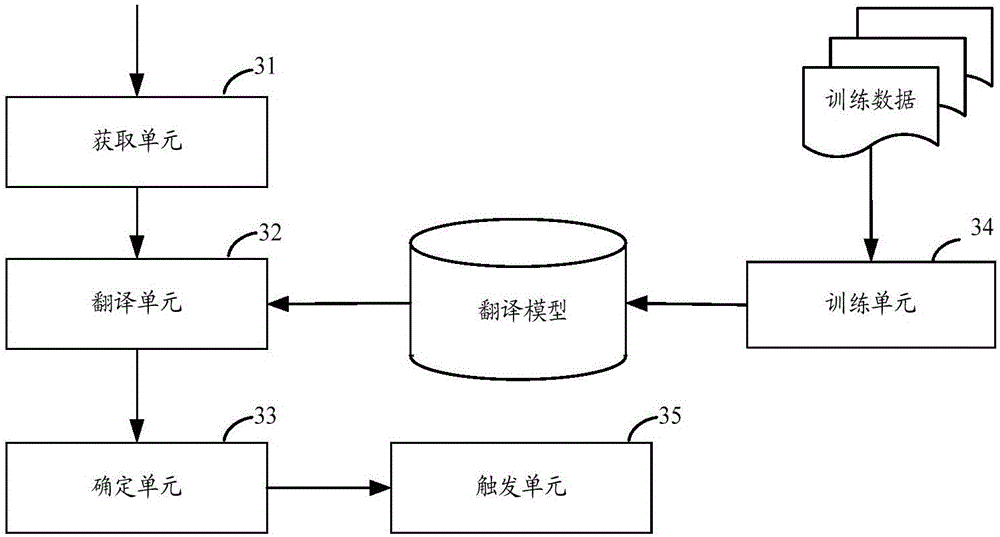
Examples
Embodiment Construction
[0031] In order to make the object, technical solution and advantages of the present invention clearer, the present invention will be described in detail below in conjunction with the accompanying drawings and specific embodiments.
[0032] Terms used in the embodiments of the present invention are only for the purpose of describing specific embodiments, and are not intended to limit the present invention. As used in the embodiments of the present invention and the appended claims, the singular forms "a", "said" and "the" are also intended to include the plural forms unless the context clearly indicates otherwise.
[0033] It should be understood that the term "and / or" used herein is only an association relationship describing associated objects, which means that there may be three relationships, for example, A and / or B, which may mean that A exists alone, and A and B exist simultaneously. B, there are three situations of B alone. In addition, the character " / " in this articl...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - Generate Ideas
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com