

Text categorization method based on Xgboost categorization algorithm
A classification algorithm and text classification technology, applied in computing, special data processing applications, instruments, etc., can solve the problems of low classification performance, large memory consumption, and low classification accuracy, and achieve simple preprocessing, memory reduction, and dimension reduction. Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
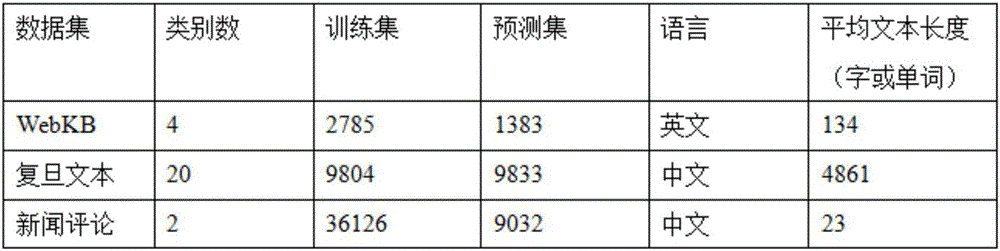
[0033] This implementation case includes 3 specific cases, respectively classifying 3 text corpora with different characteristics, that is, a public English corpus WebKB, which excludes samples without any content, and two Chinese corpora, one of which is a public long Text corpus: Fudan University text classification corpus, and another corpus with very unbalanced Chinese short text samples: news comments, divided into two categories: normal and advertising, with a positive-negative ratio of 2742 / 42416=0.065.
[0034] Table 1 Summary of text classification datasets
[0035]
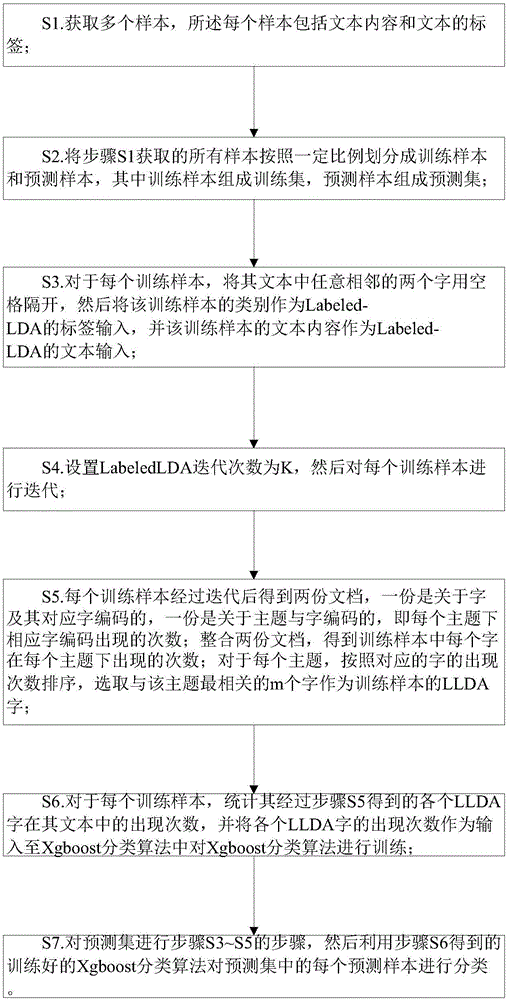
[0036] Such as figure 1 Shown, the specific implementation steps of the text classification method based on Xgboost classification algorithm of the present invention to do feature extraction with Labeled-LDA are as follows:
[0037] Step 1: Text Preprocessing
[0038] Prepare a batch of classified text sets in advance, such as 3 cases, randomly divide the training set and prediction set (news commenta...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More