Core content mining method and equipment for large-scale voice data
A technology of voice data and core content, applied in the computer field, can solve problems such as low mining efficiency and inconsistent content, and achieve the effect of improving efficiency and accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
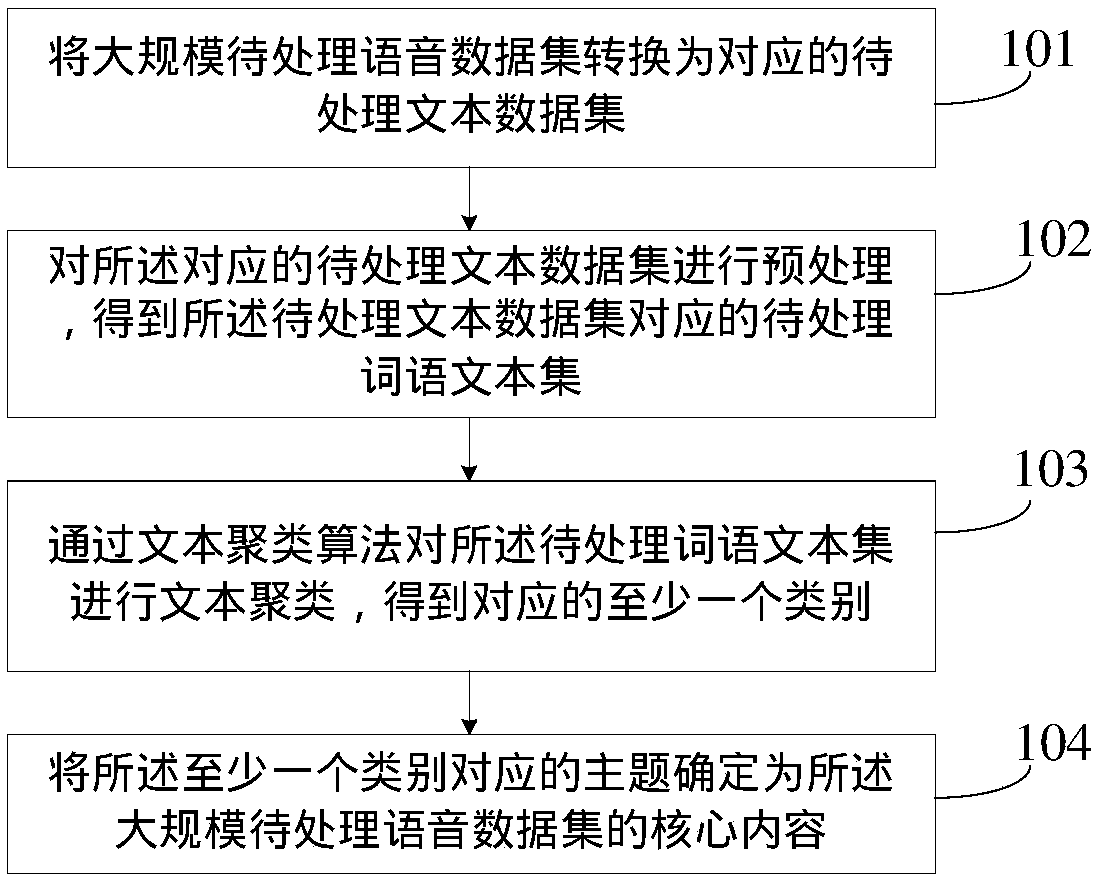
[0042] figure 1 It is a flow chart of the steps of a method for mining the core content of large-scale speech data provided by Embodiment 1 of the present invention, as figure 1 As shown, the method may include:
[0043] Step 101, converting a large-scale speech data set to be processed into a corresponding text data set to be processed.
[0044] In the embodiment of the present invention, the large-scale voice data set to be processed includes multiple pieces of voice data to be processed, and the corresponding text data set to be processed includes corresponding pieces of text data to be processed. For example, assuming that the large-scale speech data set to be processed includes 3 pieces of speech data to be processed, and the corresponding 3 pieces of text data to be processed are obtained after conversion, then these 3 pieces of text data to be processed constitute the text data set to be processed.
[0045] When converting the speech data set to be processed into the ...
Embodiment 2
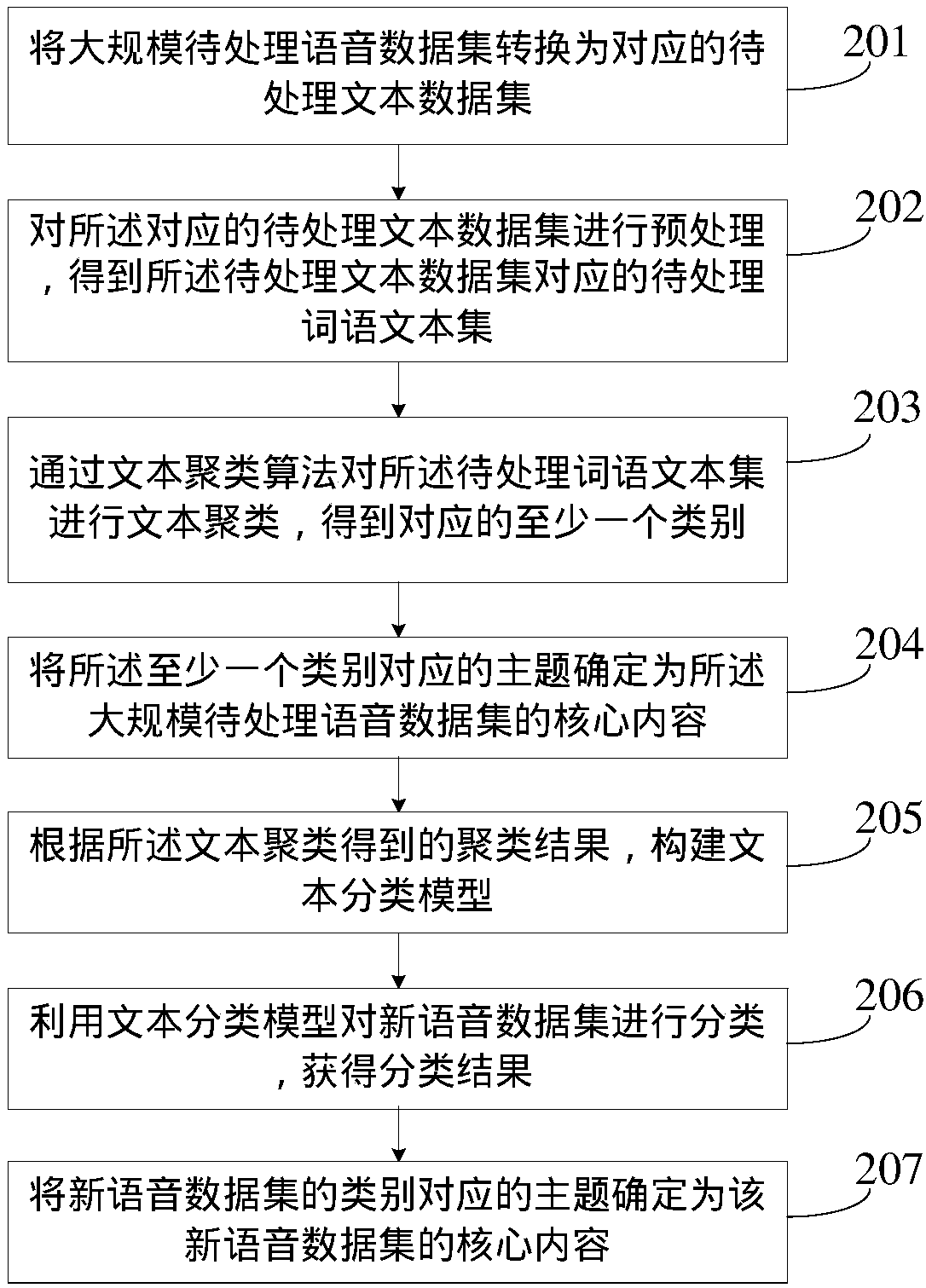
[0060] figure 2 It is a flow chart of the steps of another core content mining method for voice data provided in Embodiment 2 of the present invention, as figure 2 As shown, the method may include:
[0061] Step 201, converting a large-scale speech data set to be processed into a corresponding text data set to be processed.
[0062] The format of general voice data has multiple, for example: MP3 format, WMA format and VMA format etc., so the format of voice data to be processed may be different, in the embodiment of the present invention, after converting large-scale voice data set to be processed Before the corresponding text data set to be processed, the format of the voice data to be processed can be unified. For example, the format of all the voice data to be processed can be unified into MP3 format, or into WMA format, etc., which can facilitate the large Scale the conversion operation of the speech data set to be processed, thereby improving the accuracy of the conve...
Embodiment 3
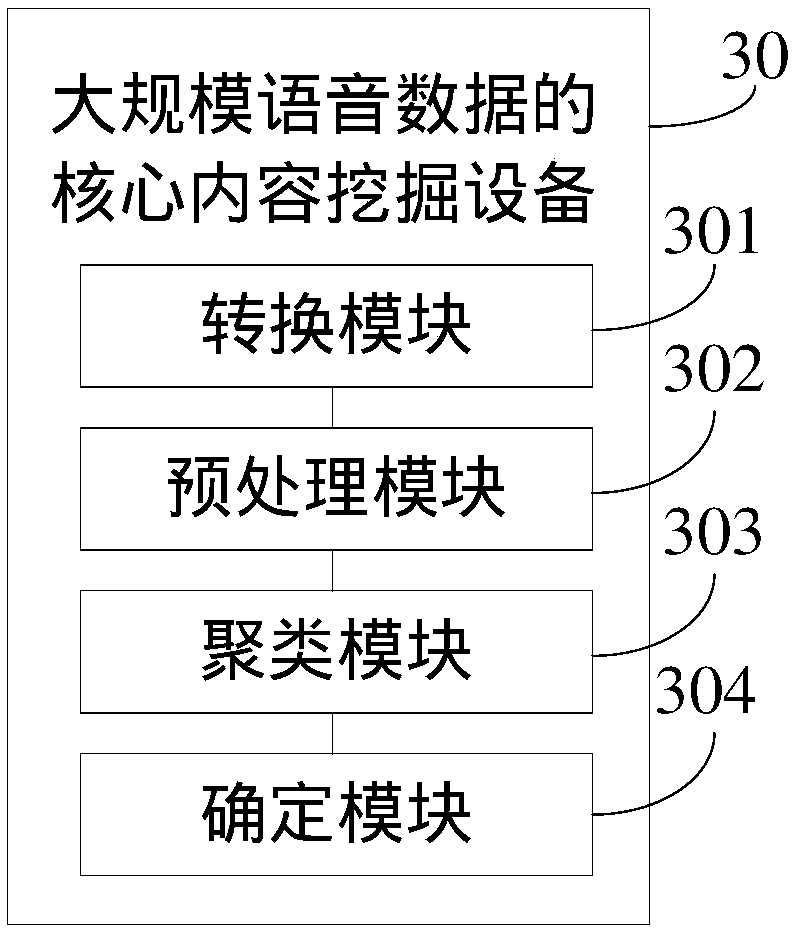
[0108] image 3 It is a core content mining device for large-scale speech data provided by Embodiment 3 of the present invention, such as image 3 As shown, the device 30 may include:
[0109] Conversion module 301, for converting the speech data set to be processed into a corresponding text data set to be processed;
[0110] A preprocessing module 302, configured to preprocess the corresponding text data set to be processed to obtain a word text set to be processed corresponding to the text data set to be processed;
[0111] A clustering module 303, configured to perform text clustering on the word text set to be processed by a text clustering algorithm to obtain at least one corresponding category;
[0112] The determination module 304 is configured to determine the subject corresponding to the at least one category as the core content of the large-scale speech data set to be processed.
[0113] In summary, the core content mining device for large-scale speech data provid...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com