

Training method for hybrid frequency acoustic recognition model and speech recognition method
A technology for identifying models and mixing frequencies, applied in speech recognition, speech analysis, instruments, etc., can solve the problems of model robustness and generalization limitations, insufficient training data, and cumbersome recognition model update and maintenance. Robustness and generalizability, effect of suppressing influence
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0049] The present invention will be further described below in conjunction with the accompanying drawings and specific embodiments, but not as a limitation of the present invention.
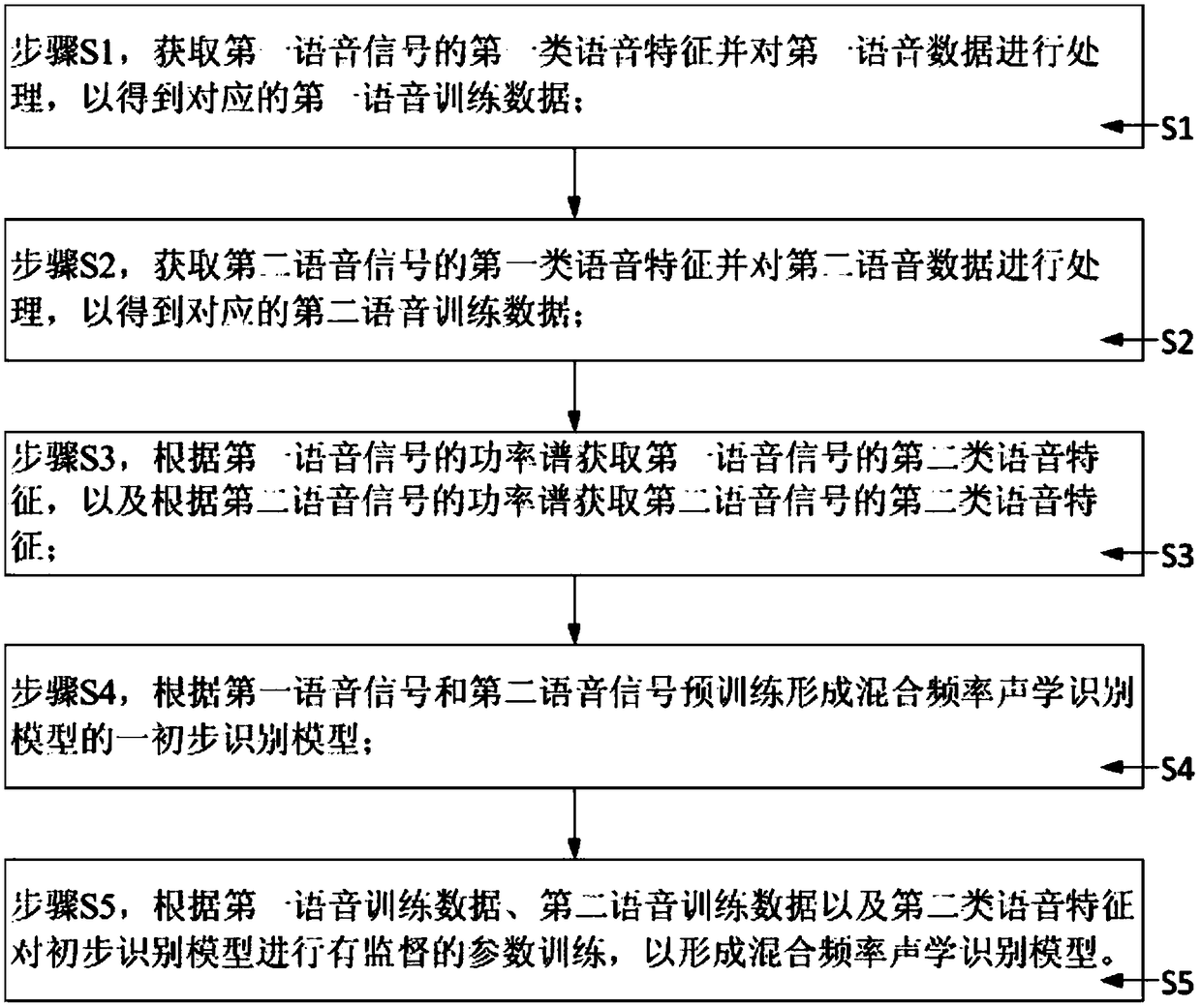
[0050] Based on the above-mentioned problems existing in the prior art, a method for training a mixed-frequency acoustic recognition model is now provided. In this method, a unified mixed-frequency acoustic recognition model is formed through training, so as to separately perform the first The speech signal is acoustically recognized, and the second speech signal with a second sampling frequency is acoustically recognized. In other words, in this training method, a unified acoustic recognition model is trained for recognition on a variety of speech data with different sampling frequencies, rather than a dedicated acoustic recognition model trained for each speech data as in the traditional method.
[0051] The above training methods are as follows: figure 1 shown, including:
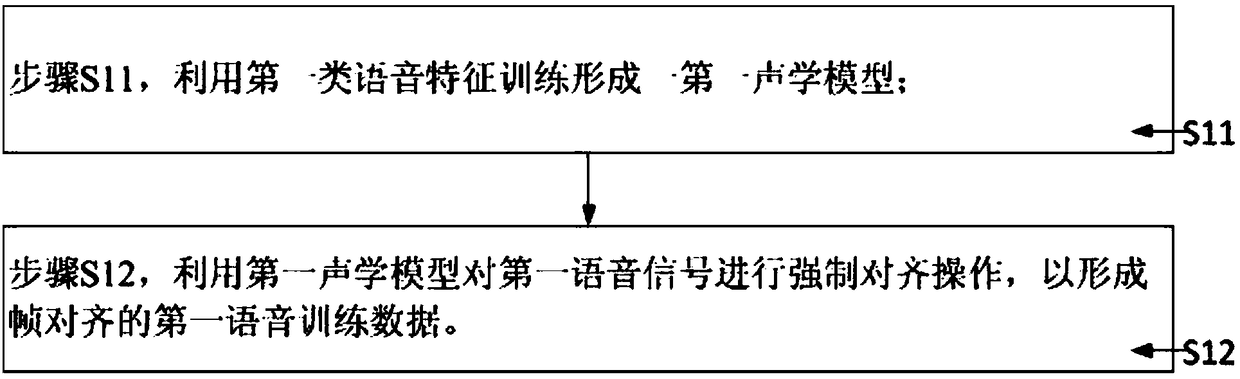
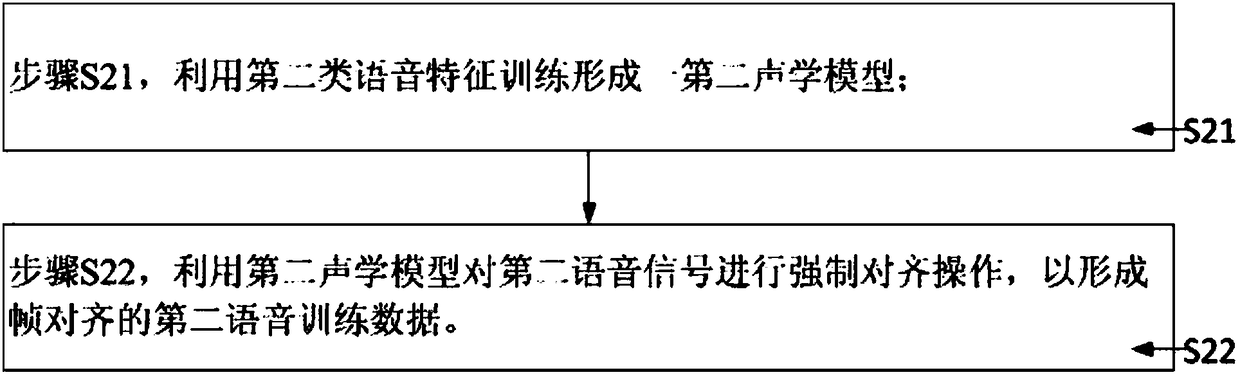
[0052] Step S1, ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More