

Sichuan dialect identification method and apparatus, acoustic model training method and apparatus, and equipment
An acoustic model and training method technology, applied in speech recognition, speech analysis, instruments, etc., can solve the problems of high recognition error rate and low recognition efficiency, achieve good recognition effect and reduce training time.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
no. 1 example
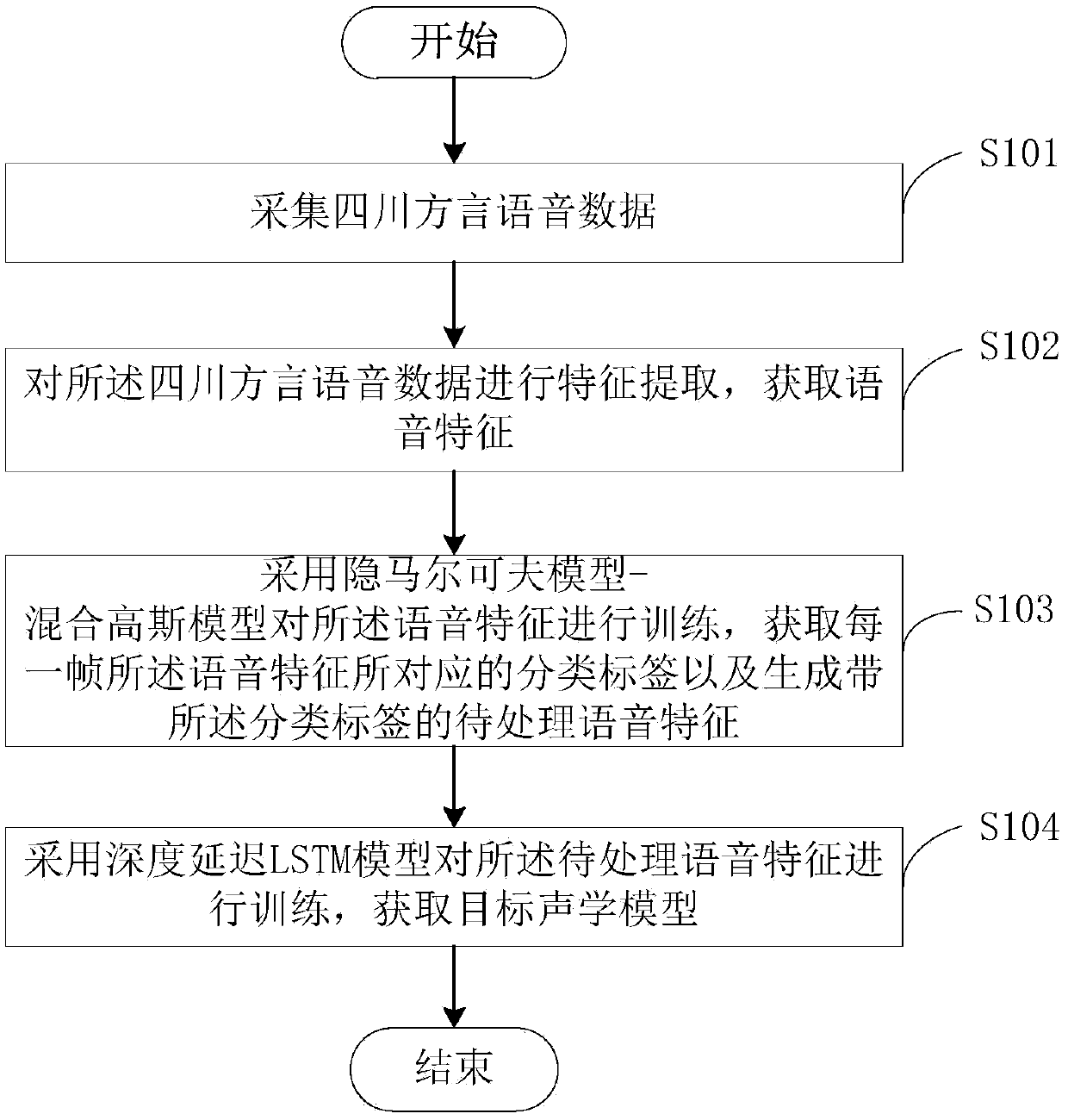
[0029] see figure 1 , is a flow chart of the acoustic model training method provided by the embodiment of the present invention. The following will be figure 1 The specific process shown will be described in detail.
[0030] Step S101, collecting voice data of Sichuan dialect.
[0031]Wherein, the speech data of Sichuan dialect can be collected through a microphone or the speech data of Sichuan dialect in a video can be collected through a software tool. For example, the user inputs a piece of voice data through the microphone of the mobile phone, or intercepts the voice data played in the video. Here, no specific limitation is made.
[0032] Wherein, the Sichuan dialect voice data is for the Sichuan dialect.
[0033] Wherein, the length of the Sichuan dialect speech data may be multiple frames or one frame. Preferably, the length of the Sichuan dialect voice data is multiple frames.
[0034] In this embodiment, the Sichuan dialect speech data may be speech signals in w...
no. 2 example
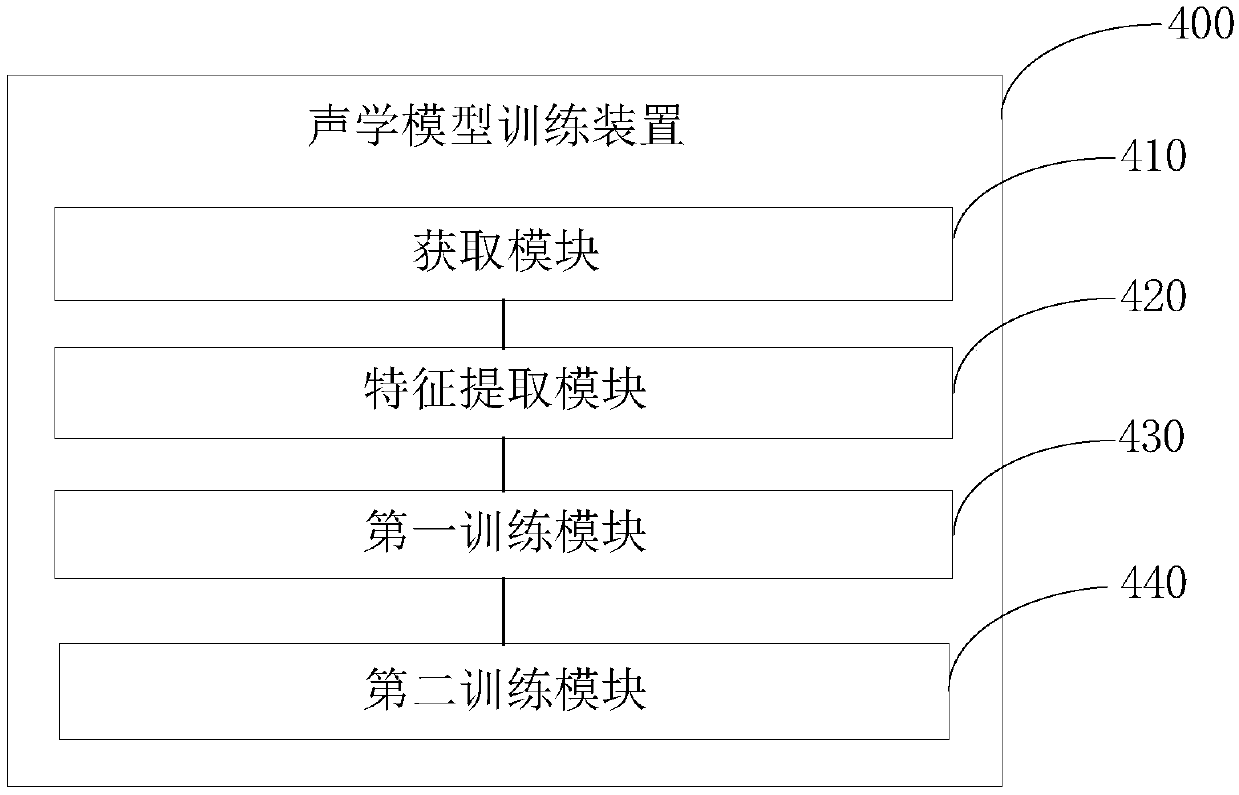
[0074] Corresponding to the sound model training method in the first embodiment, image 3 It shows a voice model training device that adopts the voice model training method shown in the first embodiment in one-to-one correspondence. Such as image 3 The acoustic model training device 400 shown includes an acquisition module 410 , a feature extraction module 420 , a first training module 430 and a second training module 440 . Among them, the implementation functions of the acquisition module 410, the feature extraction module 420, the first training module 430 and the second training module 440 are in one-to-one correspondence with the corresponding steps in the first embodiment. stated.
[0075] The obtaining module 410 is used for collecting speech data of Sichuan dialect.
[0076] The feature extraction module 420 is configured to perform feature extraction on the speech data of the Sichuan dialect to obtain speech features.
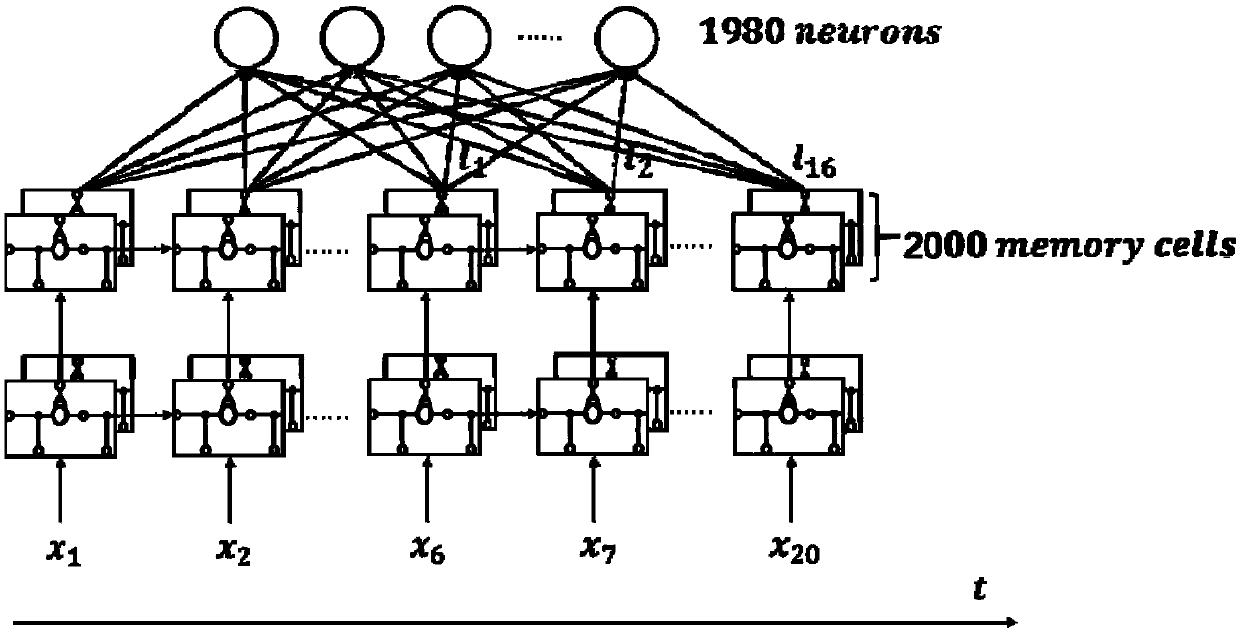
[0077] As an implementation manner, the feat...
no. 3 example
[0084] see Figure 4 , is a flow chart of the Sichuan dialect recognition method provided by the embodiment of the present invention. The following will be Figure 4 The specific process shown will be described in detail.
[0085] Step S201, acquiring voice data input by a user.
[0086] Wherein, user input sound data may be collected through a microphone. For example, a user inputs a piece of voice data through a microphone of a mobile phone.
[0087] Wherein, the length of the voice data may be multiple frames or one frame.
[0088] In this embodiment, the voice data may be voice signals in wav, mp3 or other formats. Here, no specific limitation is made.
[0089] Step S201 , using the target acoustic model obtained by the acoustic model training method and the preset Sichuan dialect dictionary and language model to recognize the speech data, and obtain a recognition result.
[0090] Wherein, the Sichuan dialect dictionary is generated in advance based on a large amoun...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More