Calculation method and apparatus
A calculation method and technology for configuration files, applied in the field of big data, can solve problems such as inability to meet requirements, unfixed content, and high performance requirements, and achieve the effect of flexible and convenient configuration process, improved development efficiency, and reduced workload.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
no. 1 example
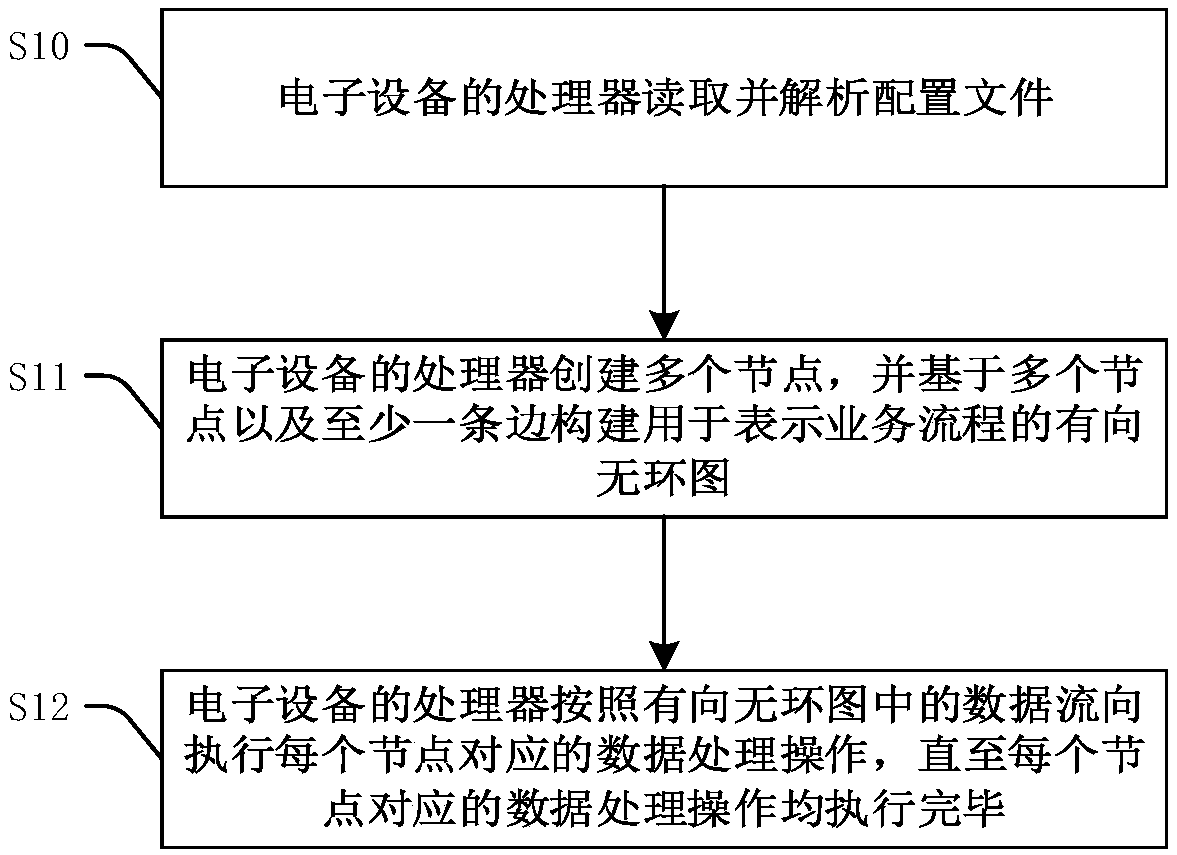
[0069] figure 2 A flow chart of the calculation method provided by the first embodiment of the present invention is shown. This calculation method can be applied to, but not limited to, Spark programs. In the following descriptions, the application of the method in the Spark program is taken as an example for illustration, but this does not constitute a limitation to the protection scope of the present invention. refer to figure 1 , the calculation method includes:
[0070] Step S10: the processor of the electronic device reads and parses the configuration file.
[0071] A configuration file is configured for a business requirement, which is usually a data processing task.
[0072] In the Spark program, after the SparkContext is initialized, use the shell command to pass in the storage location of the configuration file on HDFS, use IO to read the configuration file, and parse its content according to the format of the configuration file, where the configuration file can ...
no. 2 example
[0173] In the second embodiment, the calculation method provided by the embodiment of the present invention is further described by making an analogy to the SQL statement.
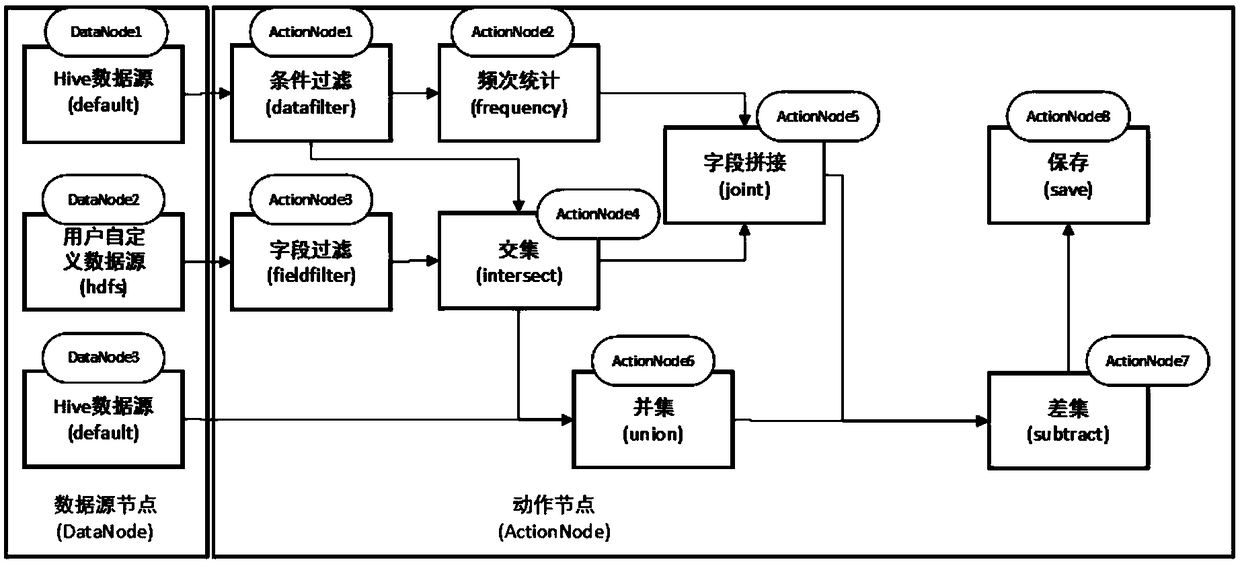
[0174] The default database in Hive has two tables student and sc. The fields of student include sno, sname, sage, and sex, and the fields of sc include sno, cno, and score. Figure 4 A schematic diagram of the content of the student table provided by the second embodiment of the present invention is shown. Figure 5 A schematic diagram of the contents of the score table provided by the second embodiment of the present invention is shown.
[0175] Now there is a requirement: I want to find out all the grades of all female students. If you directly use sparkSQL to operate, that is, use the SQL-like method, then the SQL statement should be:
[0176] select score, cno from sc where sno in (select sno from student where sex = 'female')
[0177] For the convenience of explanation, the SQL statement is modifi...
no. 4 example
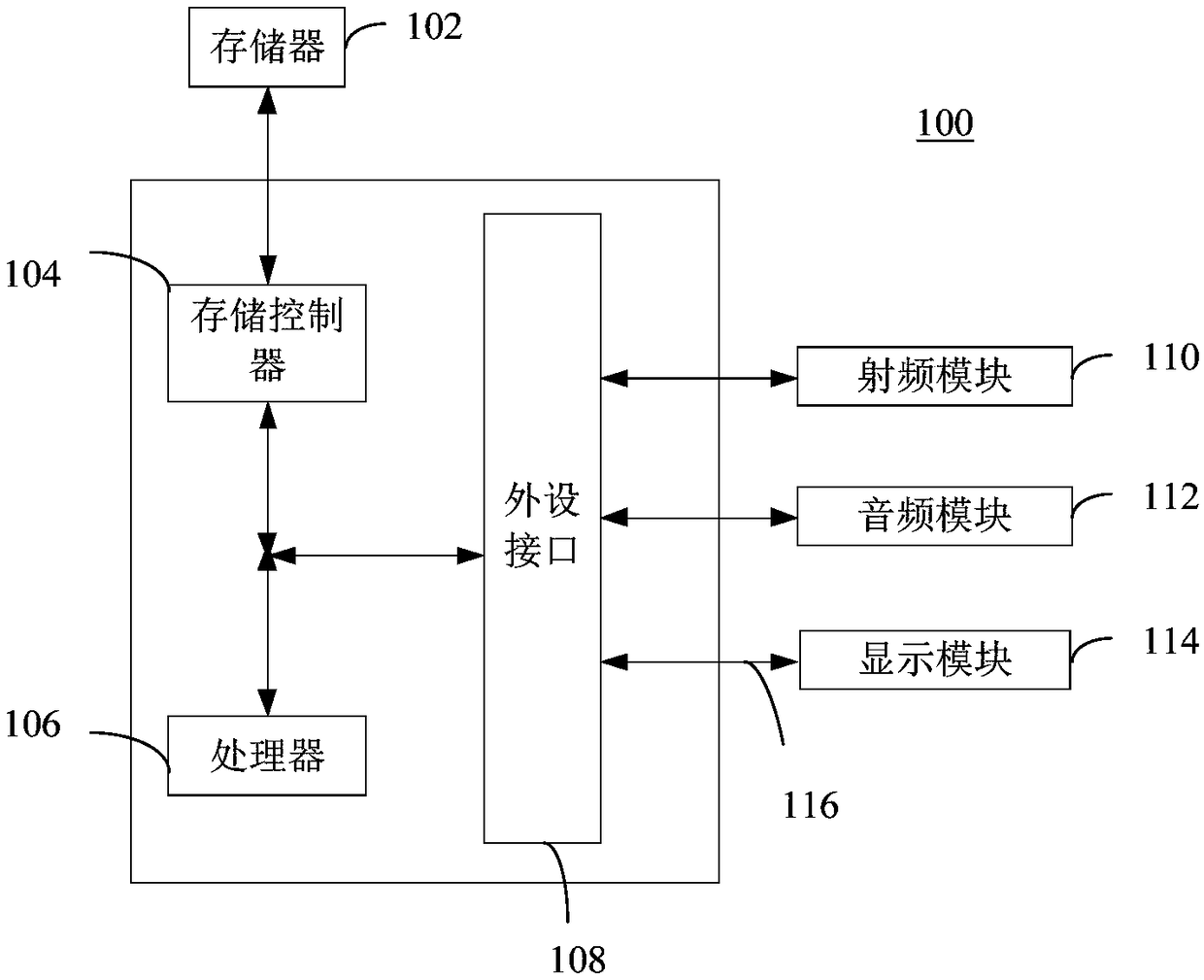
[0194] The fourth embodiment of the present invention provides a computer-readable storage medium. Computer program instructions are stored on the computer-readable storage medium. When the computer program instructions are read and run by a processor, the steps of the calculation method provided by the embodiment of the present invention are executed. . The computer readable storage medium can be implemented as, but not limited to figure 1Memory 102 is shown.
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More 
PatSnap Eureka turns technology decisions into work you can execute. Powered by our Innovation Knowledge Graph, it runs expert workflows across engineering, life sciences, materials and intellectual property. Get your review-ready output in minutes.



