

Management method and system for medical image desensitization data based on content uniqueness
A technology of medical imaging and management methods, applied in the field of data management, can solve problems such as loss, achieve the effect of saving storage costs and avoiding repeated storage
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0021] The technical solutions of the present invention will be further described below in conjunction with the embodiments and the accompanying drawings.
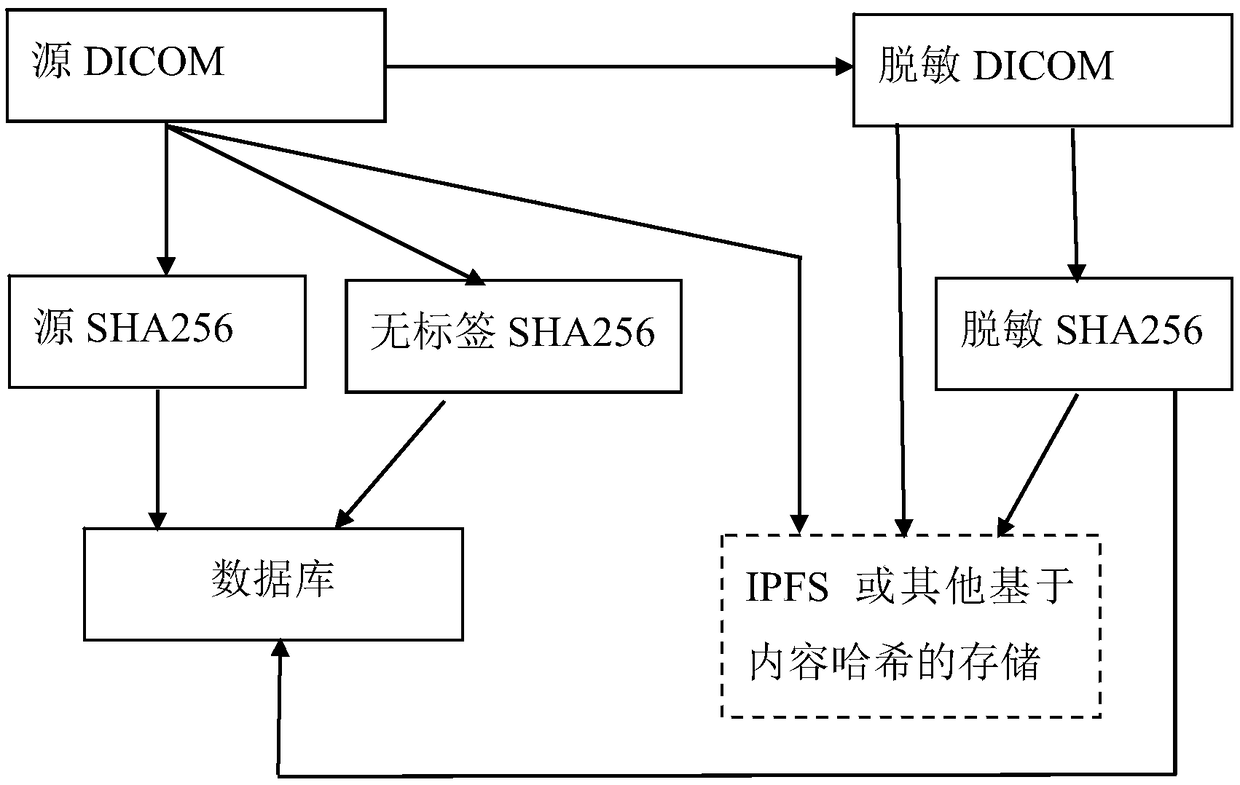
[0022] refer to figure 1 As shown, the present invention is a management method of medical image desensitization data based on content uniqueness, which is applied to the management of image desensitization data in medical systems, and at least includes the following steps:
[0023] Obtain the source data of medical image desensitization and DICOM desensitization data, and calculate the SHA256 hash value of the two data, and store the unique identifiers corresponding to the two data into the database; that is, in this step, calculate the source data and desensitization data respectively. The SHA256 hash value of the sensitive data DICOM is used as the unique identification of the two, because the DICOM tags of the source data and the desensitized data are not exactly the same, so the SHA256 values of the two will not be ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More