

A combined video description method based on multi-modal features and multi-layer attention mechanism
A video description and attention technology, applied in the field of video description, can solve the problems of ignoring the multi-modal features of the video and failing to use the attention mechanism effectively, and achieve the effect of improving the accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0031] In order to make the purpose, technical solution and advantages of the present invention clearer, the present invention will be further described in detail below in conjunction with the implementation methods and accompanying drawings.
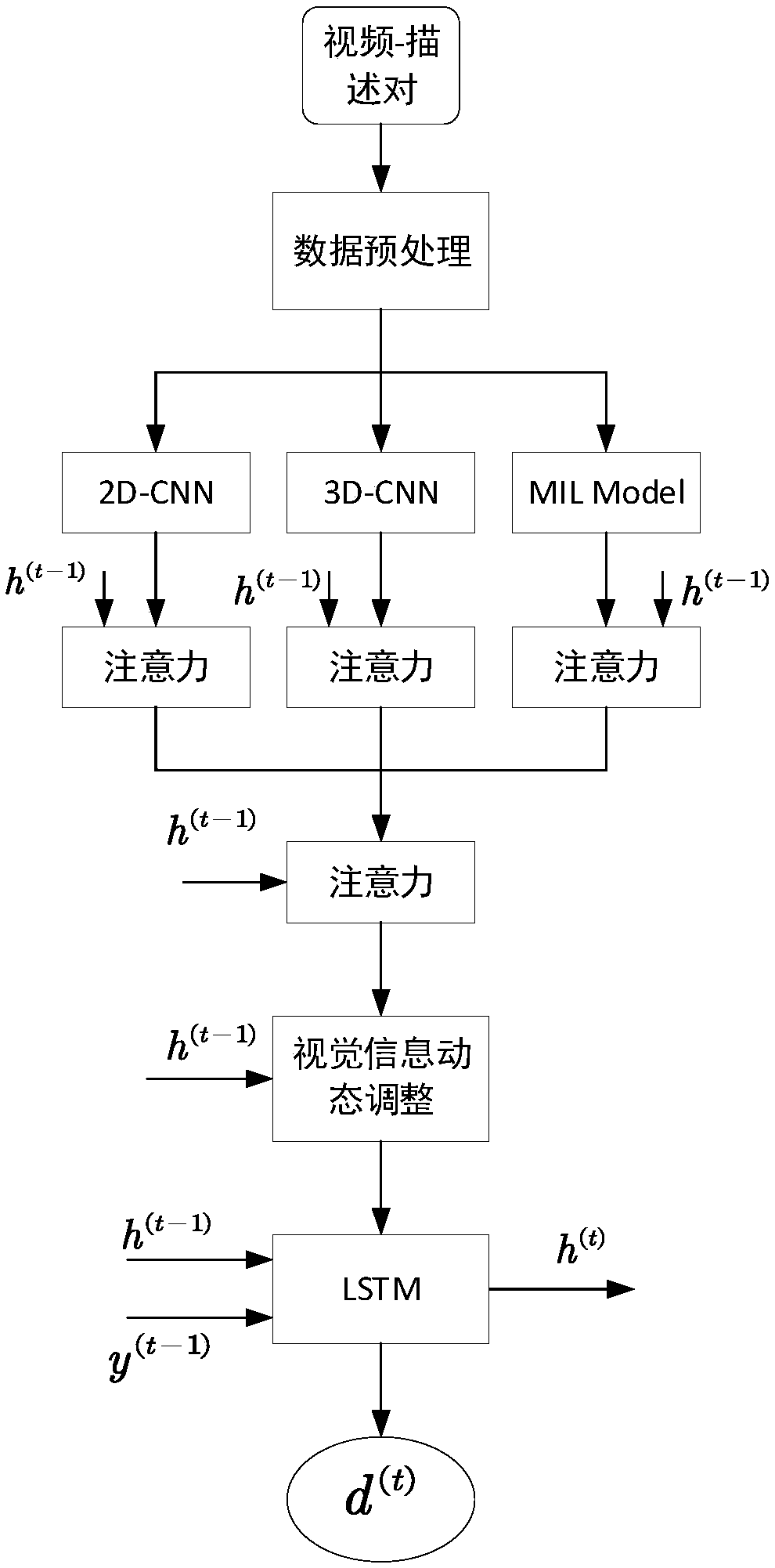
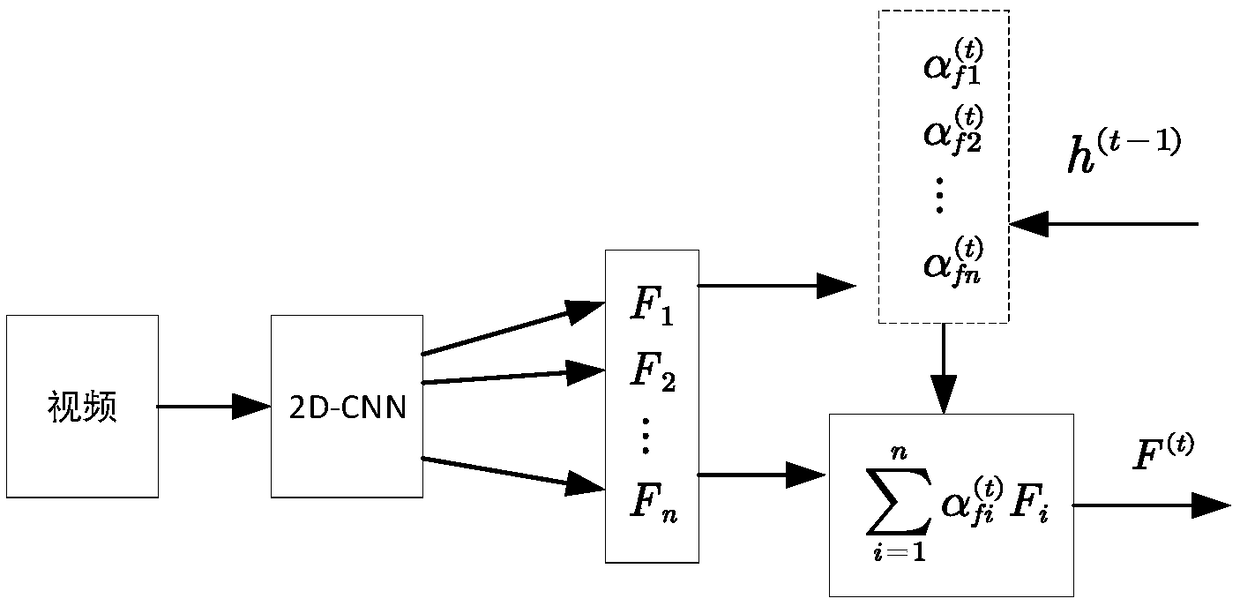
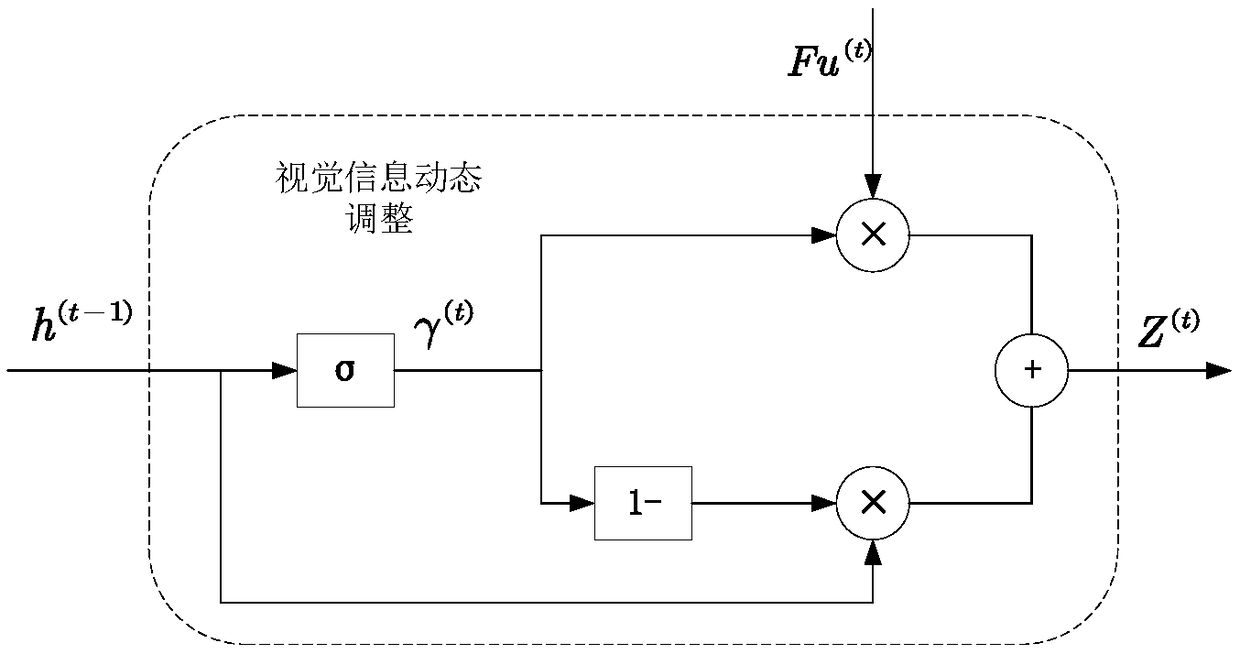
[0032] see figure 1 , the present invention extracts multi-modal data features for video and combines multi-modal data fusion with attention mechanism, and the specific steps of generating semantic description are as follows:
[0033] S1. Data preprocessing.
[0034] Segment the sentence of the sentence described in the video, and count all the words that appear to form a vocabulary V; then add words to the vocabulary V and words As the beginning and end of the sentence; at the same time, add at the beginning of each video description sentence , add at the end of the sentence .
[0035] Each word is then encoded to get a binary vector representation of each word. That is to say, each word is expressed in the form of one-hot (one...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More