Audio quality evaluating method and device, electronic device and storage medium
A technology of audio quality and audio files, applied in speech analysis, speech recognition, instruments, etc., can solve problems such as time-consuming and laborious, low efficiency of audio quality evaluation, and low coverage of detection samples
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
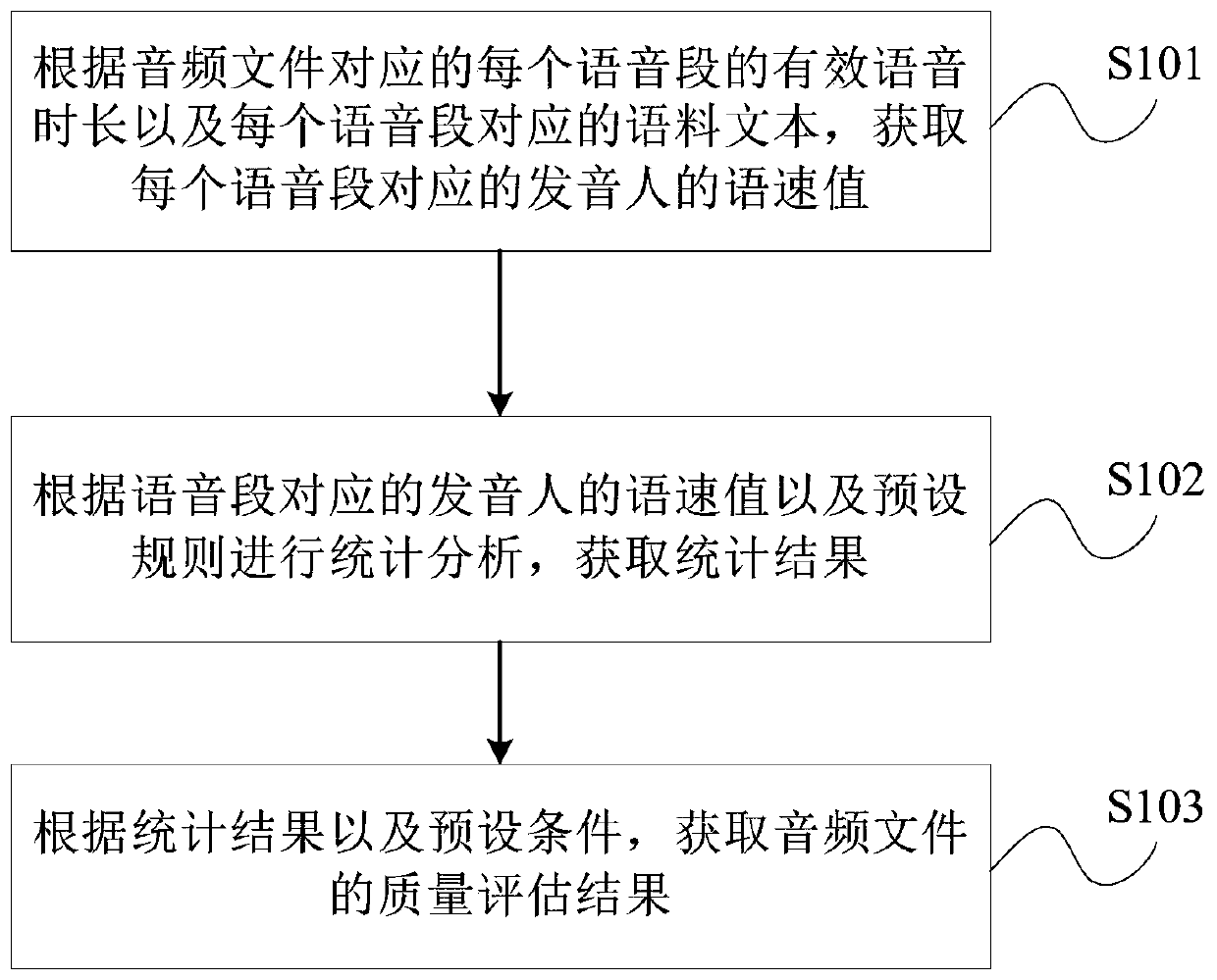
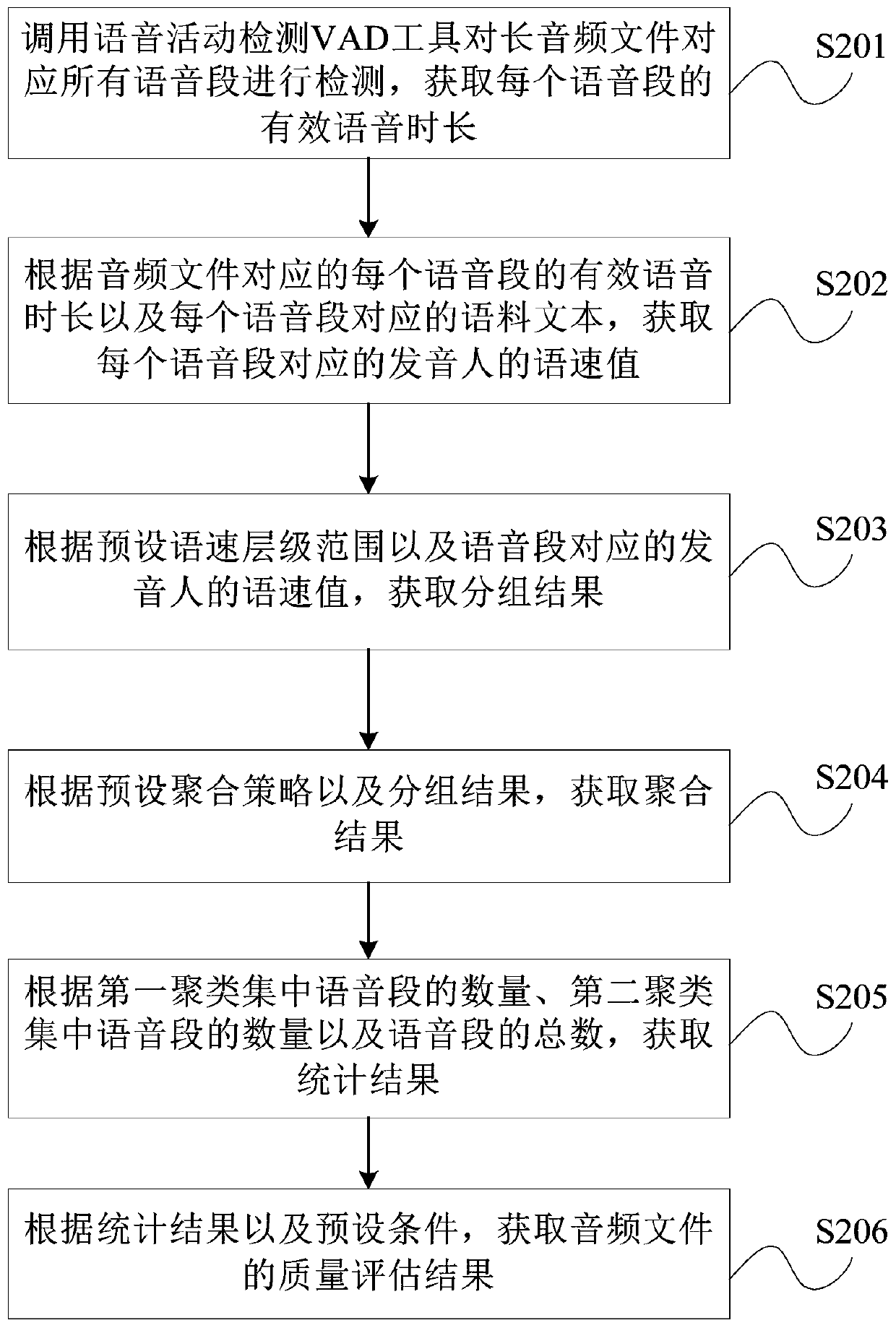
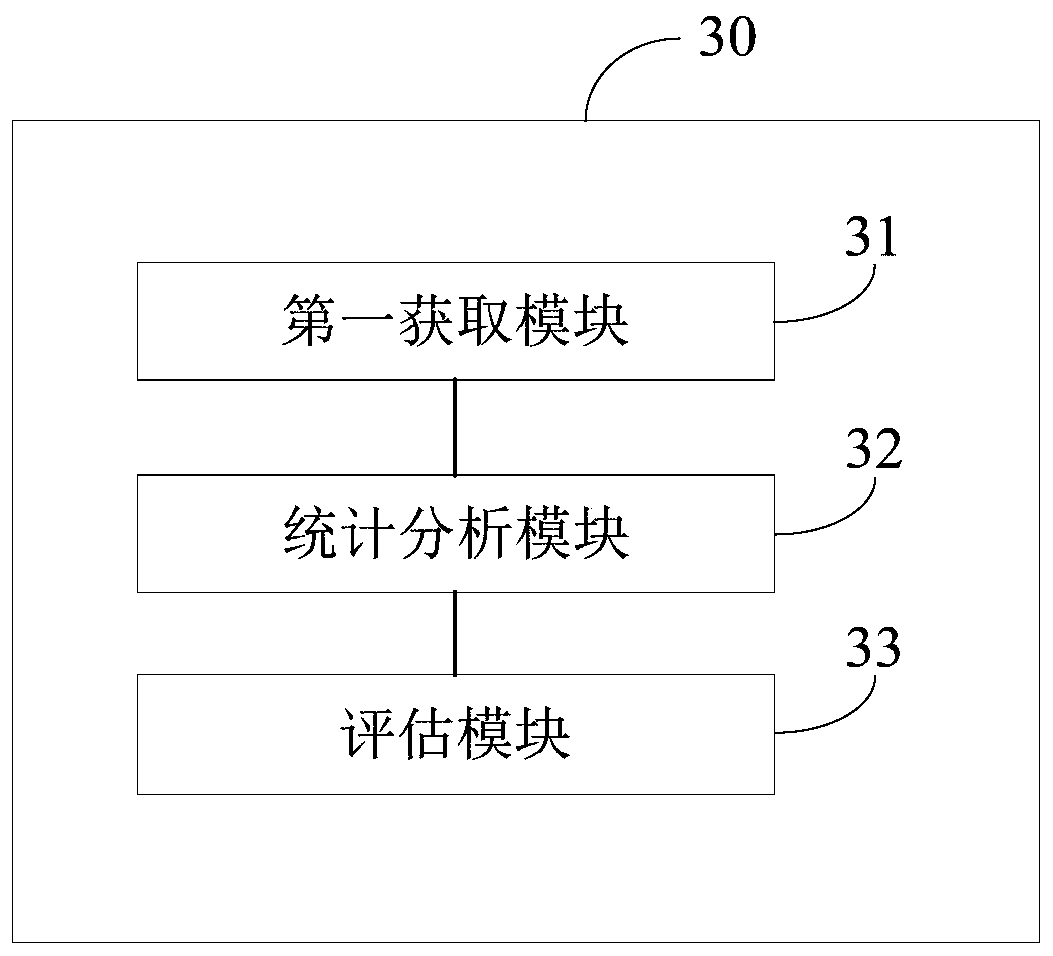
[0040] In order to make the purpose, technical solutions and advantages of the embodiments of the present invention clearer, the technical solutions in the embodiments of the present invention will be clearly and completely described below in conjunction with the drawings in the embodiments of the present invention. Obviously, the described embodiments It is a part of embodiments of the present invention, but not all embodiments. Based on the embodiments of the present invention, all other embodiments obtained by persons of ordinary skill in the art without making creative efforts belong to the protection scope of the present invention.
[0041] Interpretation of professional terms:
[0042] Corpus: It is the basic resource of language knowledge carried by computer as the carrier, and the corpus stores the language materials that have actually appeared in the actual use of language.
[0043] Voice Activity Detection (VAD for short): Also known as voice endpoint detection or v...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - Generate Ideas
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com