

A distributed acceleration method and system for a deep learning training task
A deep learning and distributed technology, applied in the field of deep learning, can solve the problems of reducing training accuracy, reducing single communication traffic, etc., to achieve the effect of improving cluster expansion efficiency, compressing communication time, and accelerating the training process
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

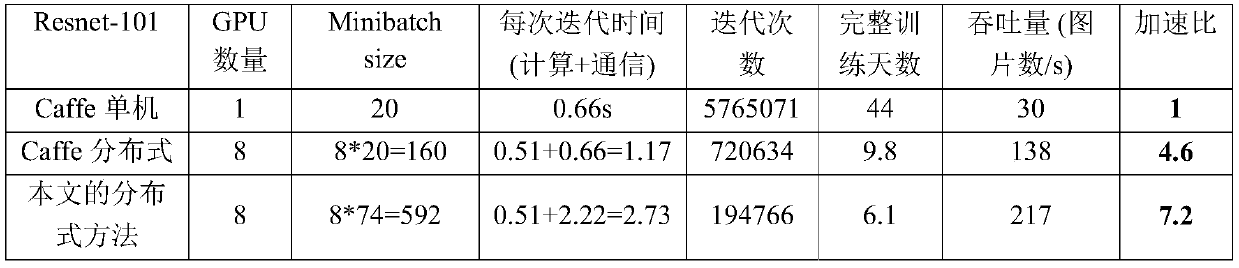
Examples
Embodiment Construction
[0030] The present invention will be further described below in conjunction with the accompanying drawings and specific embodiments.
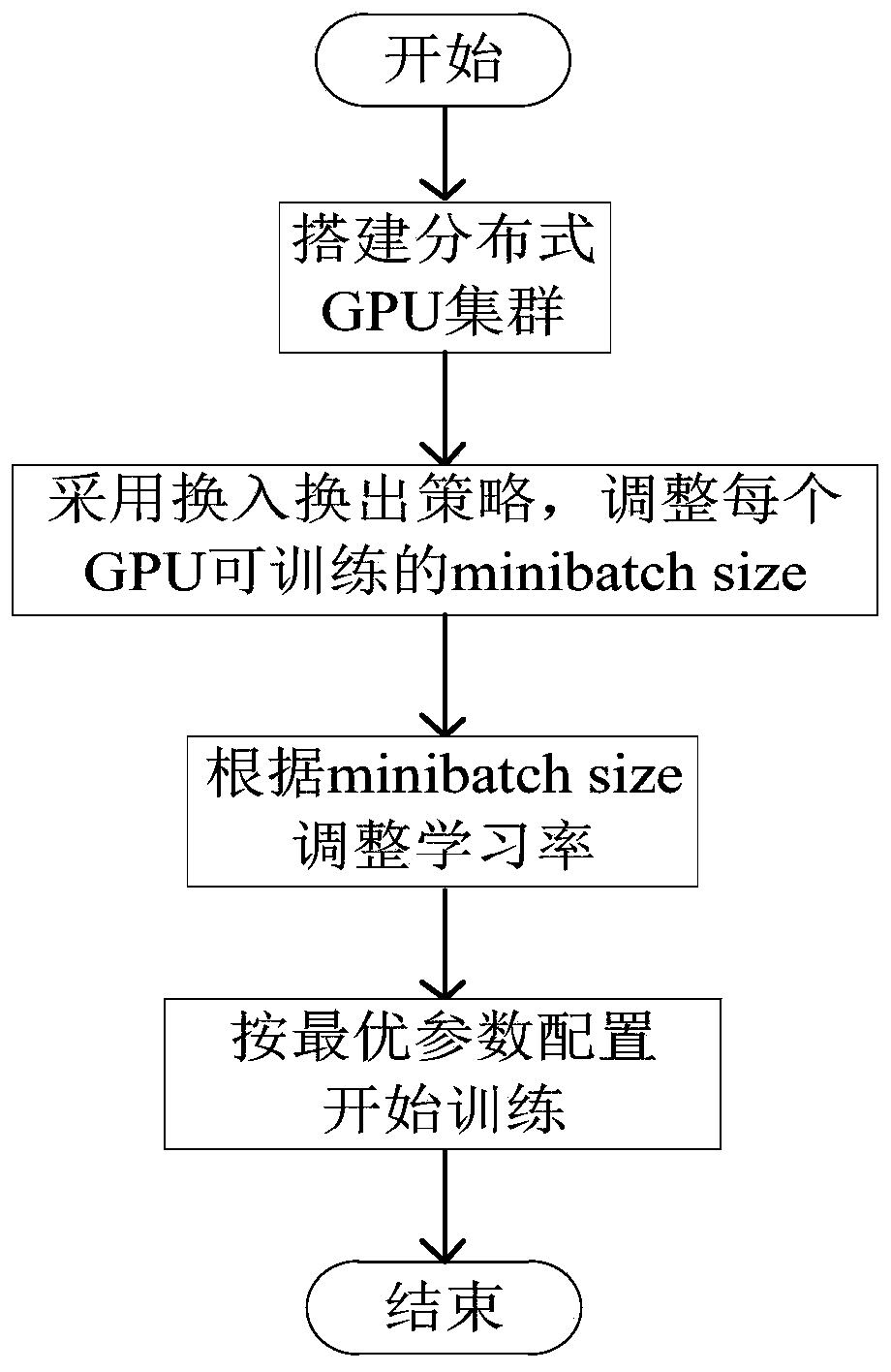
[0031] refer to figure 1 , the present embodiment provides a distributed acceleration method for deep learning training tasks, the method includes the following steps:
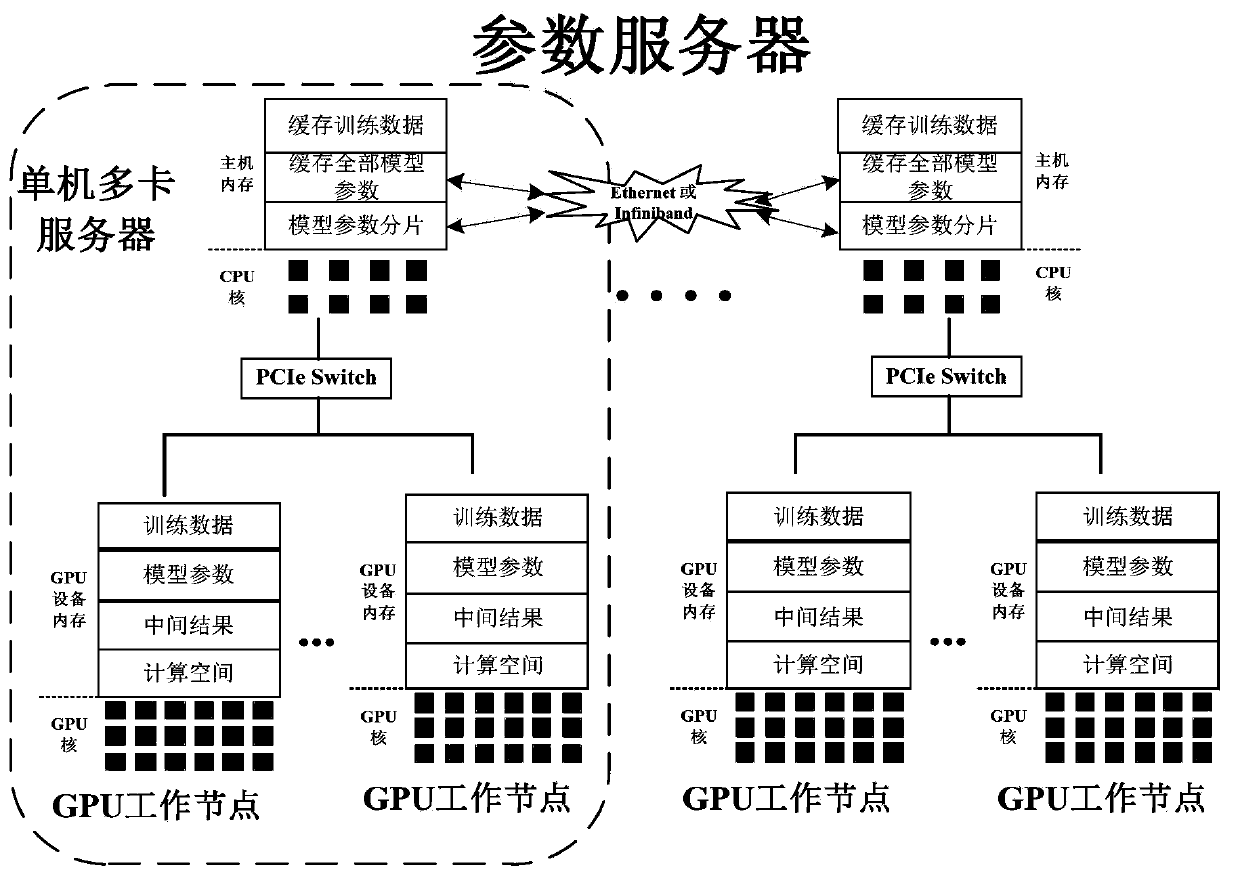
[0032] (1) Build a distributed GPU training cluster, including: divide parameter servers and work nodes, determine communication architecture, refer to figure 2 , the specific steps are as follows:
[0033] (1-1) Build a parameter server to save and update model parameters. The CPUs of all servers in the cluster collectively form a parameter server. All model parameters are evenly stored in the memory of each CPU. The parameter update is completed by the CPU and exposed to the outside world. There are two operations, push and pull, to be invoked by working nodes. The push operation refers to the parameter server receiving the gradient sent by the working node, and the pull o...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More