

Data labeling system and method based on intelligent distribution algorithm
A technology of intelligent distribution and data processing system, which is applied in the direction of neural learning methods, calculations, computer components, etc., can solve the problems of different labeling literacy levels of labelers, high error rate of manual processing, etc., and achieve efficient and safe data management mode, The effect of manual processing error rate reduction and labeling quality assurance
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
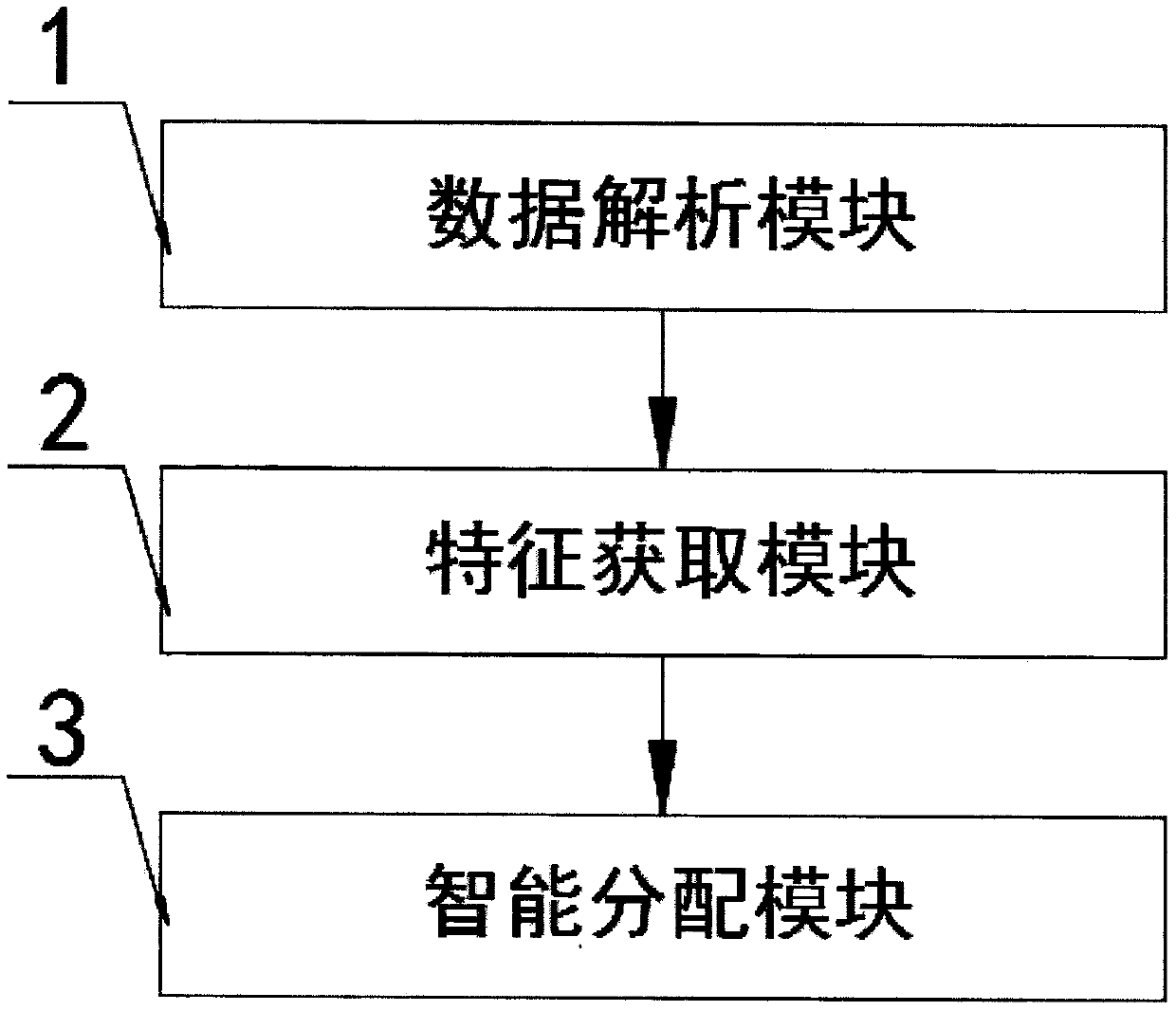
[0031] according to Figure 1-2 The shown a kind of data processing system based on intelligent allocation algorithm comprises data analysis module 1, feature acquisition module 2 and intelligent allocation module 3, and the output end of described data analysis module 1 is connected with the input end of feature acquisition module 2, and described feature The output terminal of acquisition module 2 is connected with the input terminal of intelligent distribution module 3;
[0032] The data parsing module 1 includes a model database, and a plurality of different deep learning models are internally stored in the model database;
[0033] The data analysis module 1 is used to adopt different deep learning models for different tasks, combine the coordination algorithm related to the Attention mechanism, cooperate with the multi-model fusion scheme, maximize the potential of the module, and obtain the basic quantitative characteristics of the given data. The team will analyze acco...
Embodiment 2
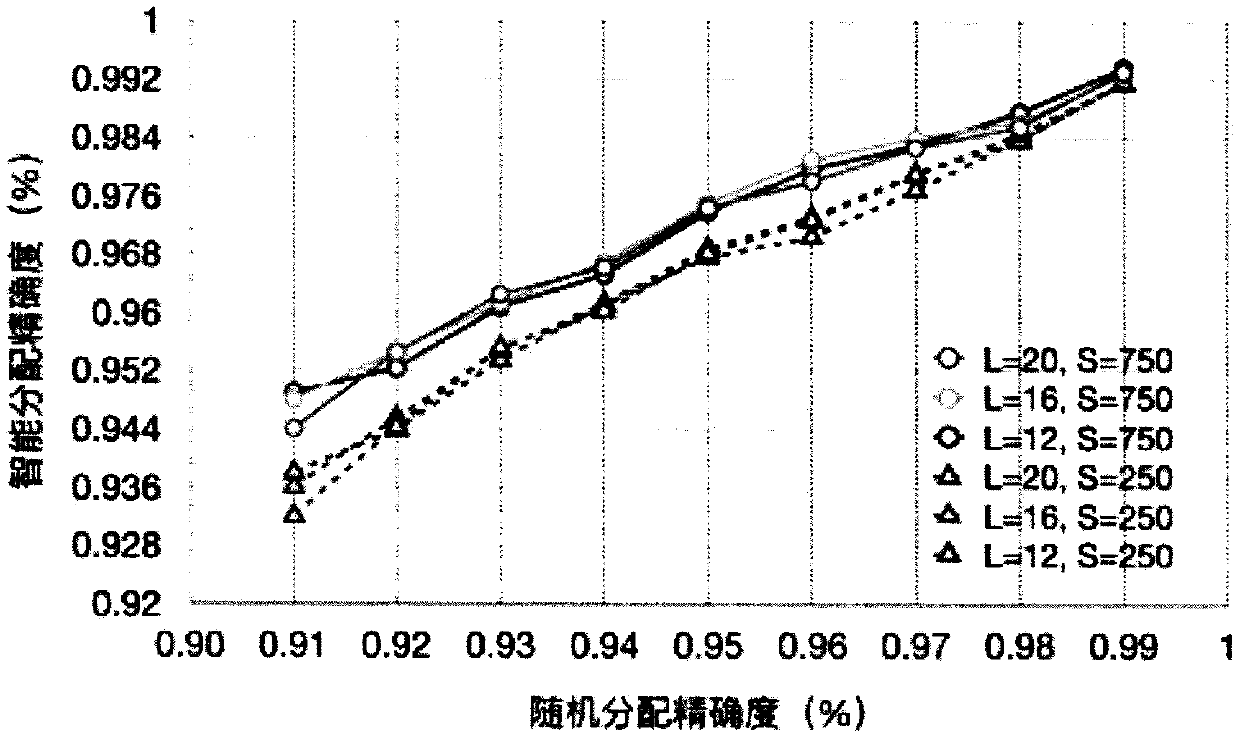
[0043] For a data labeling system and method based on an intelligent allocation algorithm proposed in the above embodiment, the algorithm evaluation is summarized as follows (note: the % in all the charts below are normalized 100%):
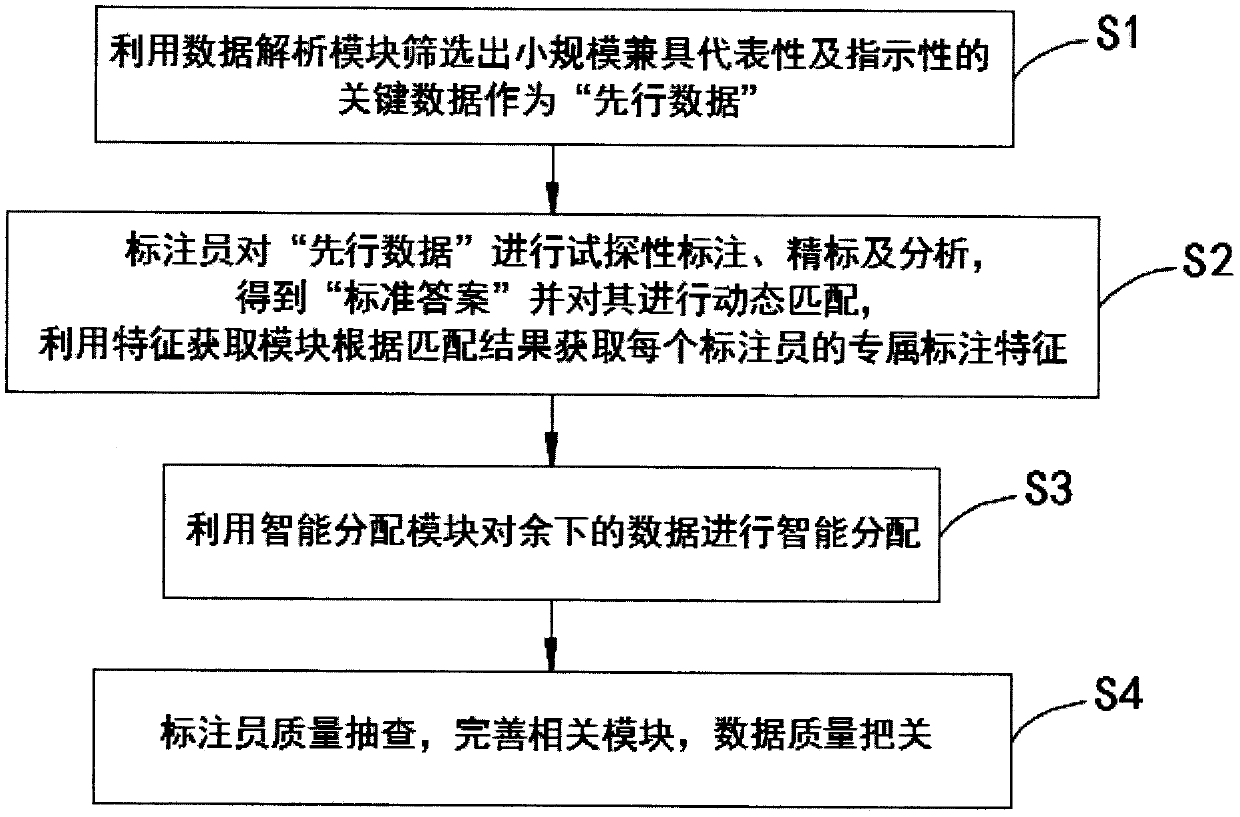
[0044] The use of intelligent allocation algorithms can reduce the error rate of manual data processing. In the manual processing tasks of text data, the manual error rate can be reduced by about 20-30%. The specific performance depends on two controllable factors: processing personnel (annotators) ) selection, the number of advance data (see step S1 in embodiment 1);
[0045] Comparative experiment settings: the data to be tagged are sentences extracted from various abstracts, such as "the remaining stars, the sadness that was hurt by you cannot be erased." The tagger needs to segment it and mark the part of speech, and the finished product is like "residual_ a’s _u star _n, _wp wipe_v not _d go_v was _p you _r hurt_v _u’s _u sad n. _wp”; this t...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More