

Speech synthesis model training method, speech synthesis method and device
A technology for speech synthesis and model training, applied in the computer field, can solve the problems of complex training process, unsatisfactory effect of synthesized speech, and dull sound quality, so as to ensure the accuracy rate, reduce pronunciation errors, and improve the accuracy.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
preparation example Construction
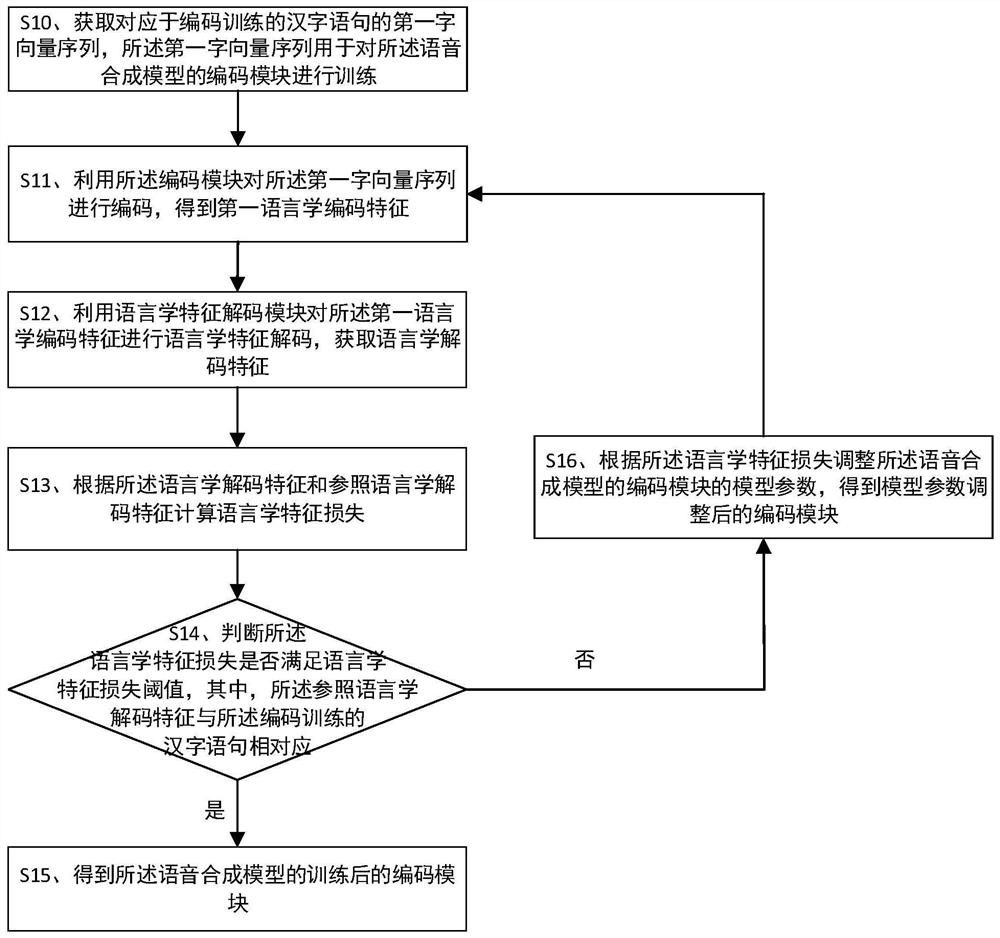
[0114] As shown in the figure, the speech synthesis method provided by the embodiment of the present invention includes:
[0115] Step S30: Obtain the third word vector sequence of the Chinese character sentence to be speech synthesized.
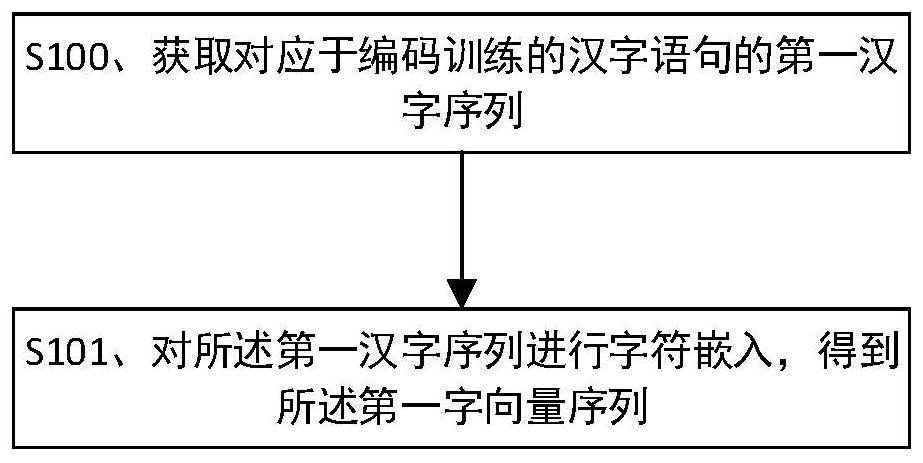
[0116] The specific content of step S30 can refer to figure 1 Step S10, which will not be repeated here.
[0117]Step S31: Encoding the third character vector sequence by using the trained encoding module to obtain a third linguistic encoding feature.
[0118] After obtaining the third character vector sequence, use the trained encoding module to encode it, so as to obtain triphonetic encoding features.
[0119] The specific content of step S31 can refer to figure 1 Step S11, which will not be repeated here.
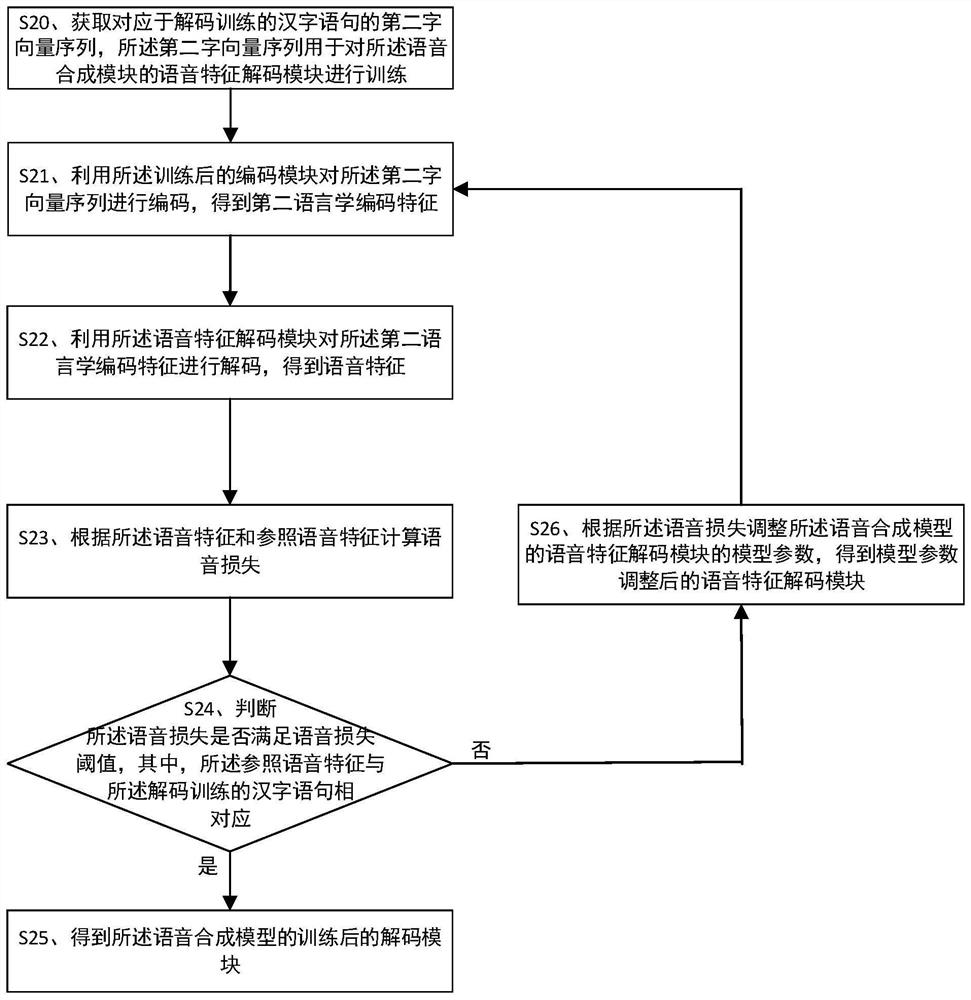
[0120] Step S32: Using the trained speech feature decoding module to decode the third linguistic coding feature to obtain a third speech feature.
[0121] After obtaining the third linguistic coding feature, use the trained speech...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More