

Prisoner emotion recognition method for multi-modal feature fusion based on self-weight differential encoder
A technology of differential coding and feature fusion, applied in the field of emotional computing, can solve the problems of difficult to accurately judge the true emotions of prisoners, low recognition rate, poor robustness, etc., to eliminate degradation problems, improve expressive ability, and improve accuracy Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
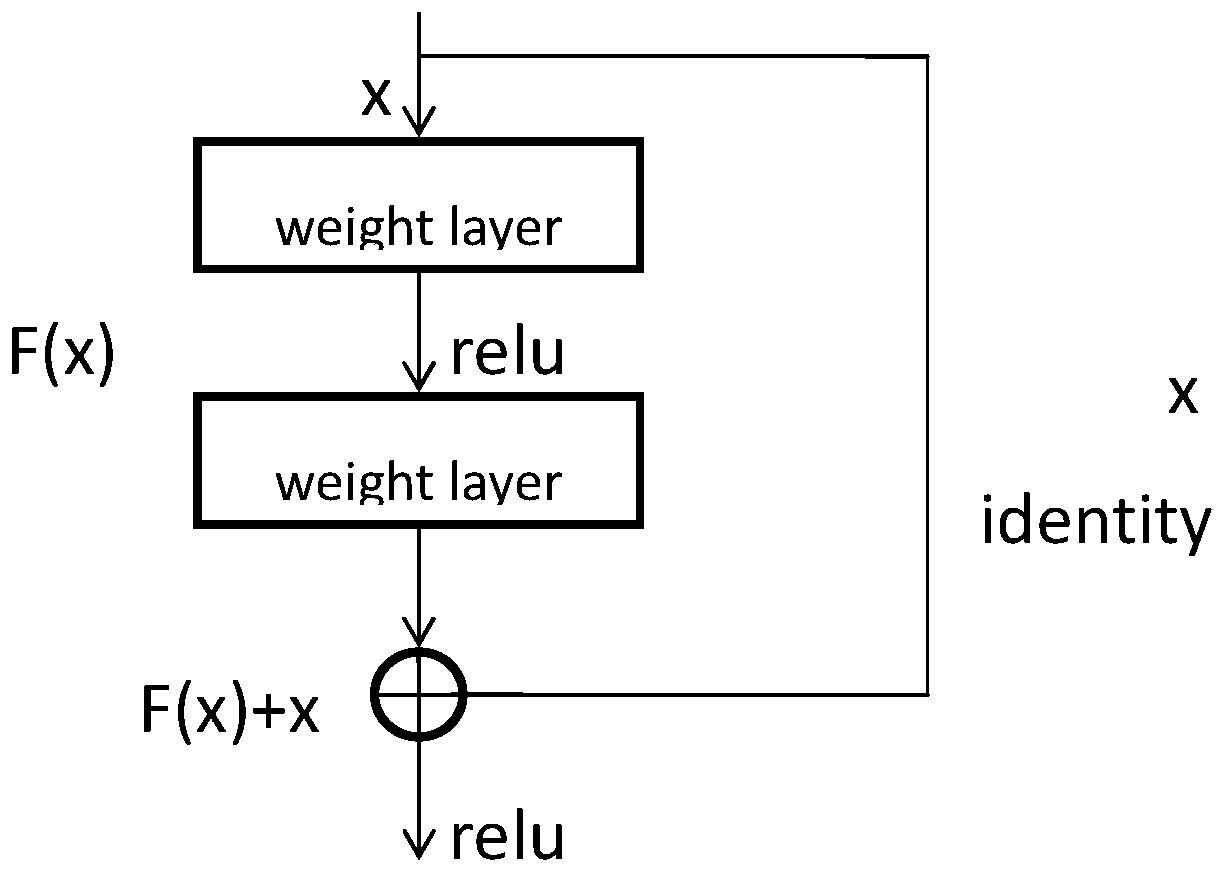
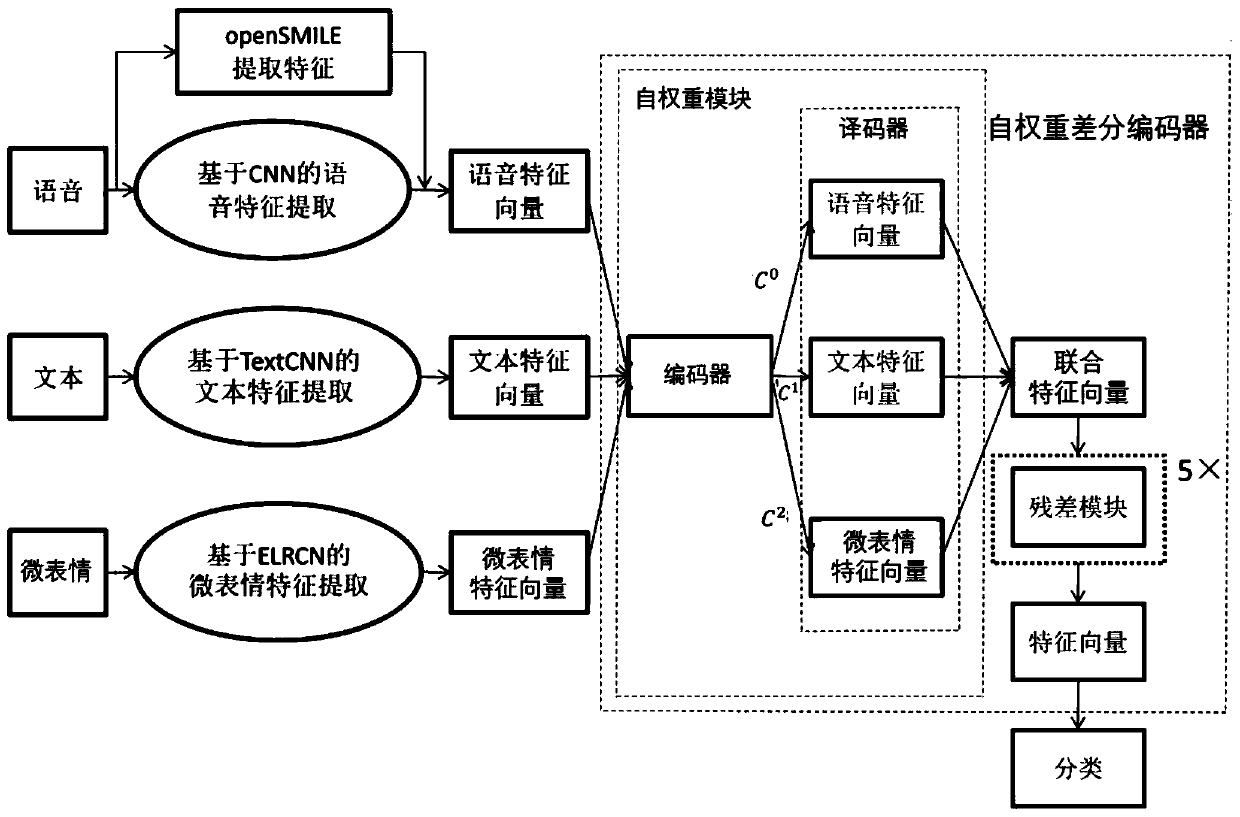
[0089] A method for emotion recognition of inmates based on self-weight differential encoder for multi-modal feature fusion, such as figure 2 shown, including the following steps:
[0090] (1) Data preprocessing: preprocess the data of the three modalities of text, voice and micro-expression, including text data, voice data, and micro-expression data, so that it meets the input requirements of the corresponding models of different modalities;
[0091] Text data refers to the text data of prison inmates’ conversations with family members / relatives and friends during remote video meetings; voice data refers to the audio data of prison inmates’ conversations with family members / relatives and friends during remote video meetings; micro-expression data refers to prison Facial micro-expression data of inmates during remote video meetings with family members / relatives and friends.
[0092] (2) Feature extraction: extract the emotional information contained in the data of the three ...
Embodiment 2
[0109] A method for emotion recognition of inmates based on self-weight differential encoder for multi-modal feature fusion according to Embodiment 1, the difference is: in the step (1),
[0110] For text data, the preprocessing process includes: segmenting the text data into words, and converting the text data into a data structure that the TextCNN model can receive and calculate according to the word segmentation results and the word vectors corresponding to the words.
[0111] In the process of data conversion, all text data including each word is numbered, and a dictionary is generated. The content in the dictionary is that each word corresponds to a serial number, and then each text is segmented, according to the serial number corresponding to the word in the dictionary. The text is converted into a mathematical sequence composed of a series of serial numbers, and then the serial number corresponds to the initialized word vector list, and the sequence is converted into mat...
Embodiment 3
[0126] According to the method for emotion recognition of inmates who carry out multi-modal feature fusion based on self-weight differential encoder according to embodiment 1, the difference is: in the step (2),
[0127] For text data, the feature extraction process includes: extracting the features of the text data through the TextCNN model;
[0128] The TextCNN model uses multiple kernels of different sizes to extract key information in sentences, so that it can better capture local correlations. The biggest advantage of TextCNN is its simple network structure. In the case of a simple model network structure, the introduction of trained word vectors has a very good effect, so that our model can accelerate the convergence speed while having a good effect.
[0129] For speech data, the feature extraction process includes:
[0130] c. Run OpenSMILE on the Linux operating platform, take the voice file in WAV format as input, select cmobase2010.conf as the standard feature data ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More