Model training method and related device
A model training and network model technology, applied in the field of data processing, can solve problems such as high error rate of network models
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0030] Embodiments of the present application are described below in conjunction with the accompanying drawings.
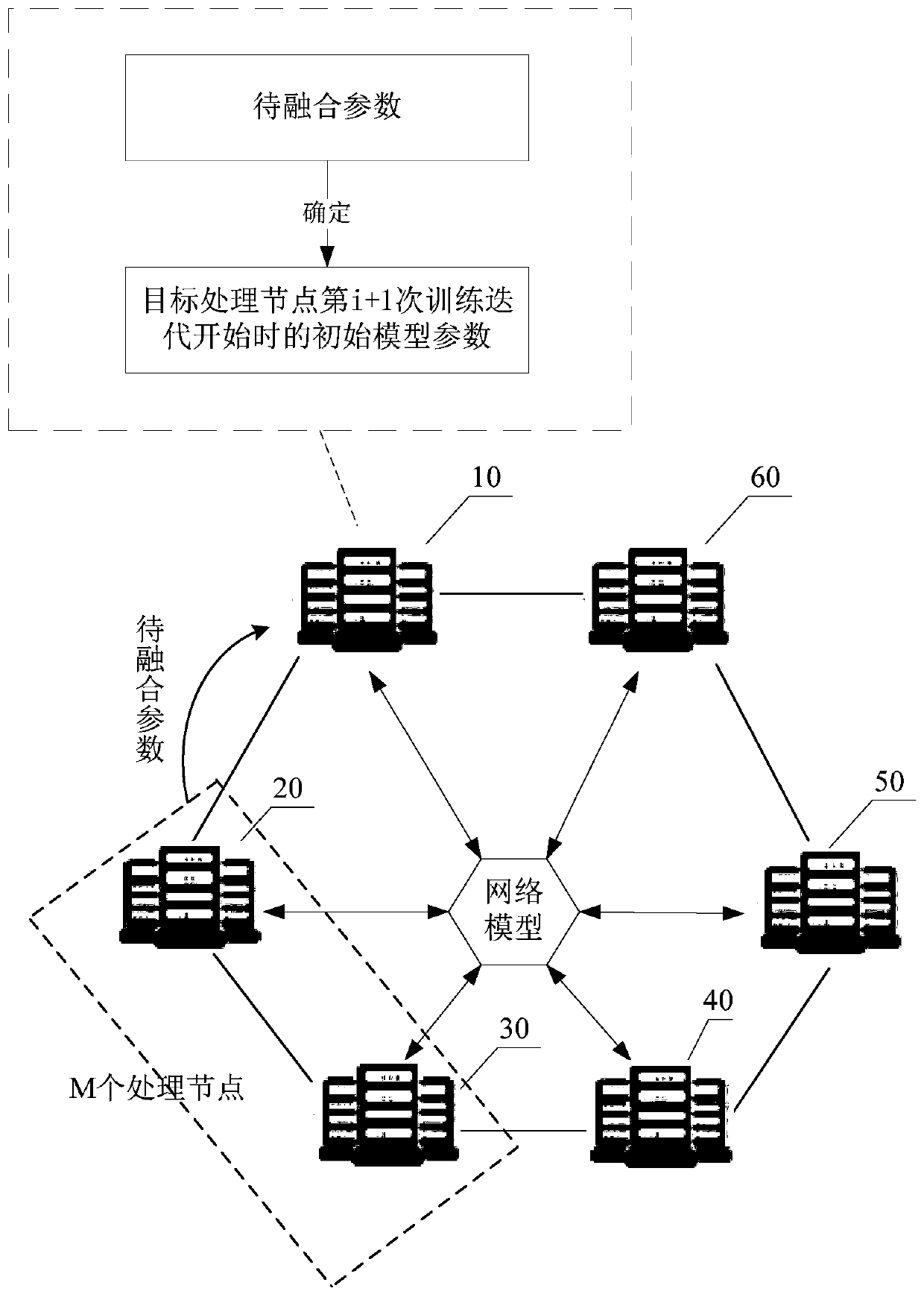
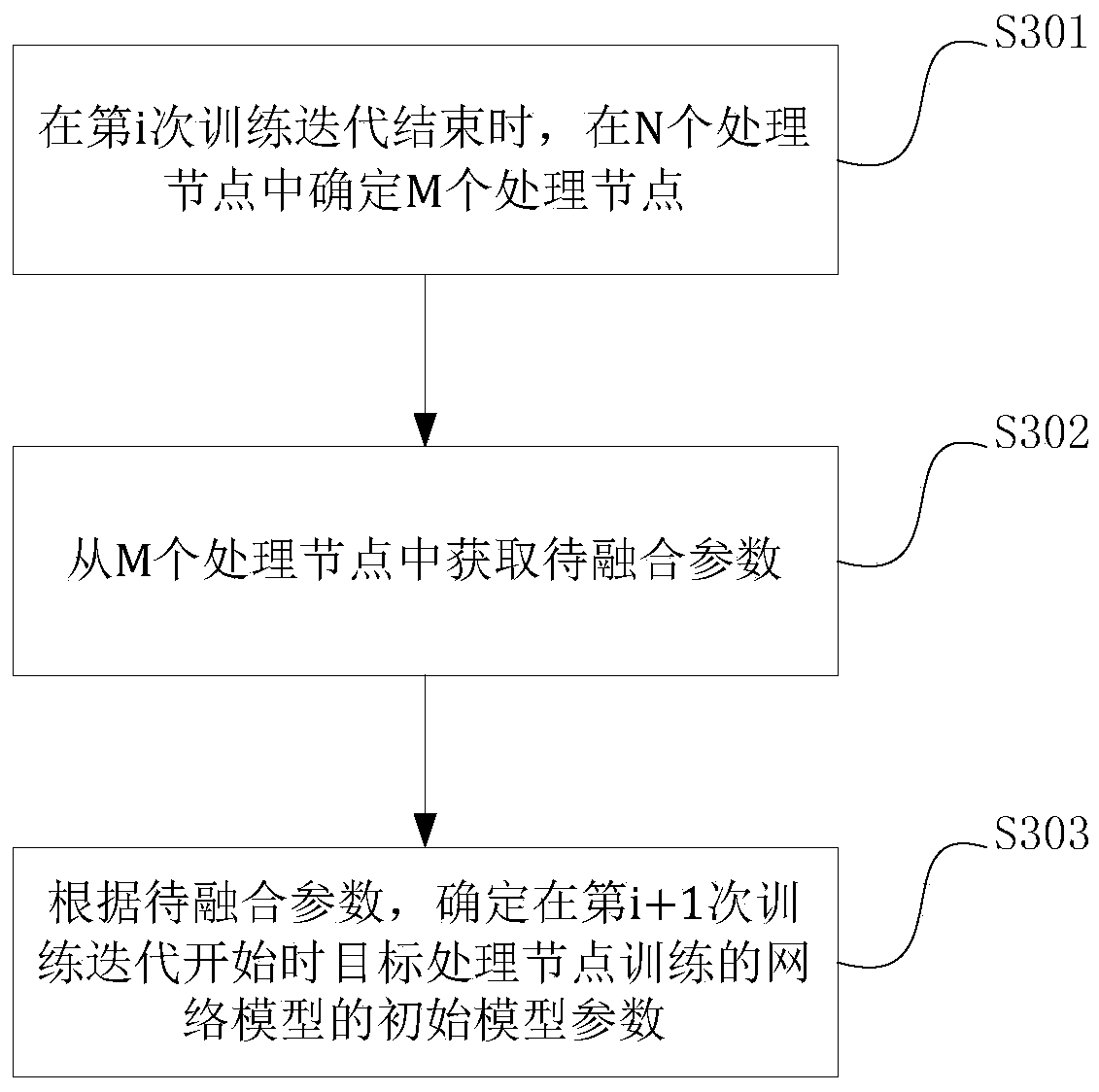
[0031] In order to improve the training speed of the complex model, a method of parallel training with multiple processing nodes can be adopted in related technologies. In order to reduce the training differences between multiple processing nodes, the model parameters of the models trained by all processing nodes are often synthesized at the end of one or more training iterations, and the synthesized model parameters are used as each processing in the next training stage. The initial parameters of the model trained by the node.
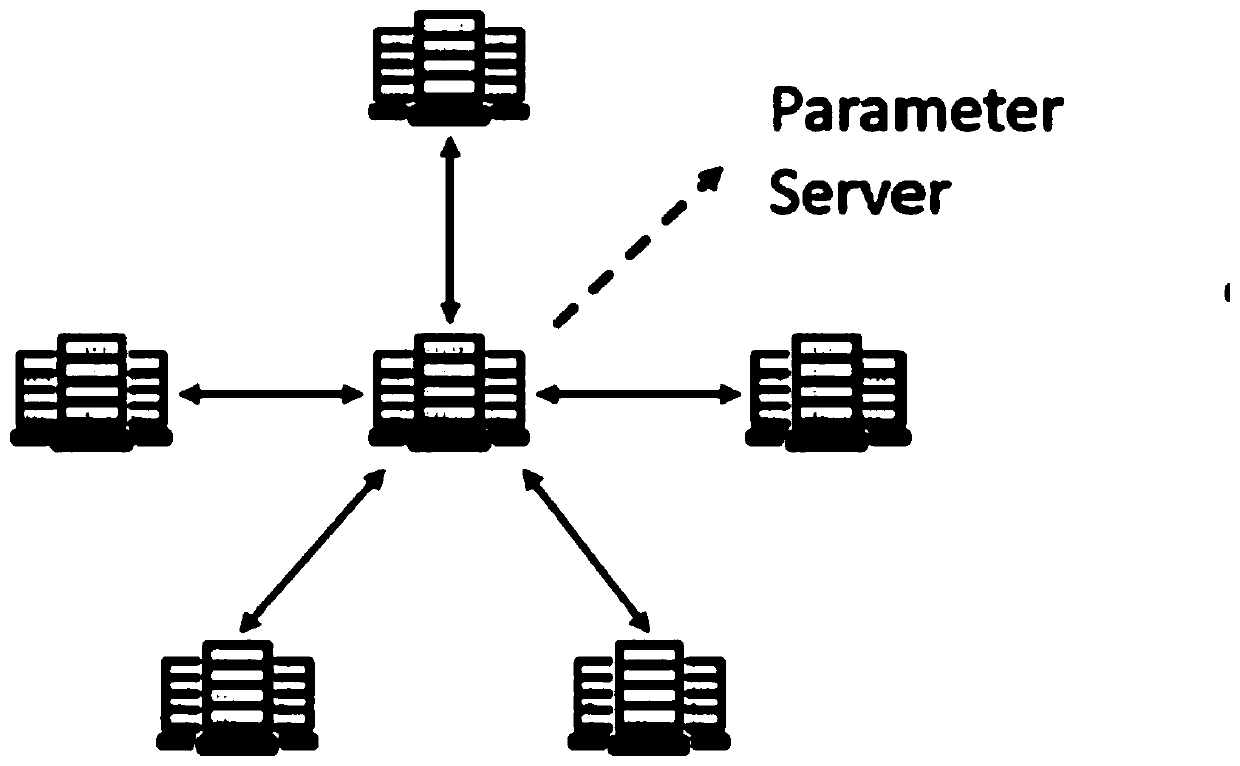
[0032] Such as figure 1 as shown, figure 1 Including a parameter server (parameter server) and multiple processing nodes (for example, 5 processing nodes), the parameter server is used as the central processing node to obtain the model parameters of all processing nodes at the end of a certain training iteration for synthesis, and obtai...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More 
PatSnap Eureka turns technology decisions into work you can execute. Powered by our Innovation Knowledge Graph, it runs expert workflows across engineering, life sciences, materials and intellectual property. Get your review-ready output in minutes.



