

Quick clustering method for massive text data
A text data and clustering method technology, applied in the field of text clustering, can solve the problems of small similarity, lack, and the clustering algorithm cannot meet the needs of text data clustering, and achieve the effect of the optimal clustering algorithm strategy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0032] In order to have a clearer understanding of the technical features, purposes and effects of the present invention, the specific implementation manners of the present invention will now be described with reference to the accompanying drawings.
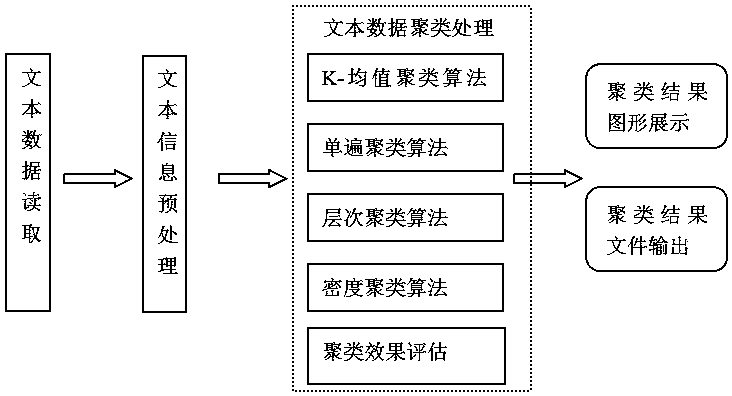
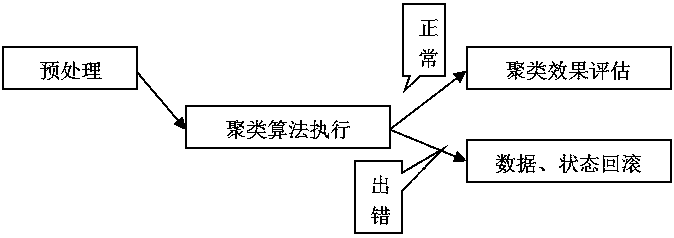
[0033] Massive text data fast clustering method, suitable for execution in computer equipment, the command line parameters input by the external interface and the text information read in the specified directory are preprocessed, and then the preset structure is called through the internal interface to complete the processing in the specified directory Clustering of text data, output the clustering results of EXCEL files or graphical interface in the specified directory, and evaluate the clustering effect.
[0034] The command line parameters include clustering algorithm, word vector encoding method, text distance measurement method and evaluation method; clustering algorithm includes K-means, single-pass clustering, hierarchical ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More