End-to-end speech recognition system based on deep learning
A speech recognition and deep learning technology, applied in speech recognition, speech analysis, instruments, etc., can solve the problems of assisting current tasks, long training time, inability to use historical information, etc., to achieve strong semantic information mining ability, and speed up training. , the effect of reducing training time
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0022] The present invention will be described in further detail below in conjunction with the accompanying drawings and specific embodiments. It should be understood that the specific embodiments described here are only used to explain the present invention, not to limit the present invention.
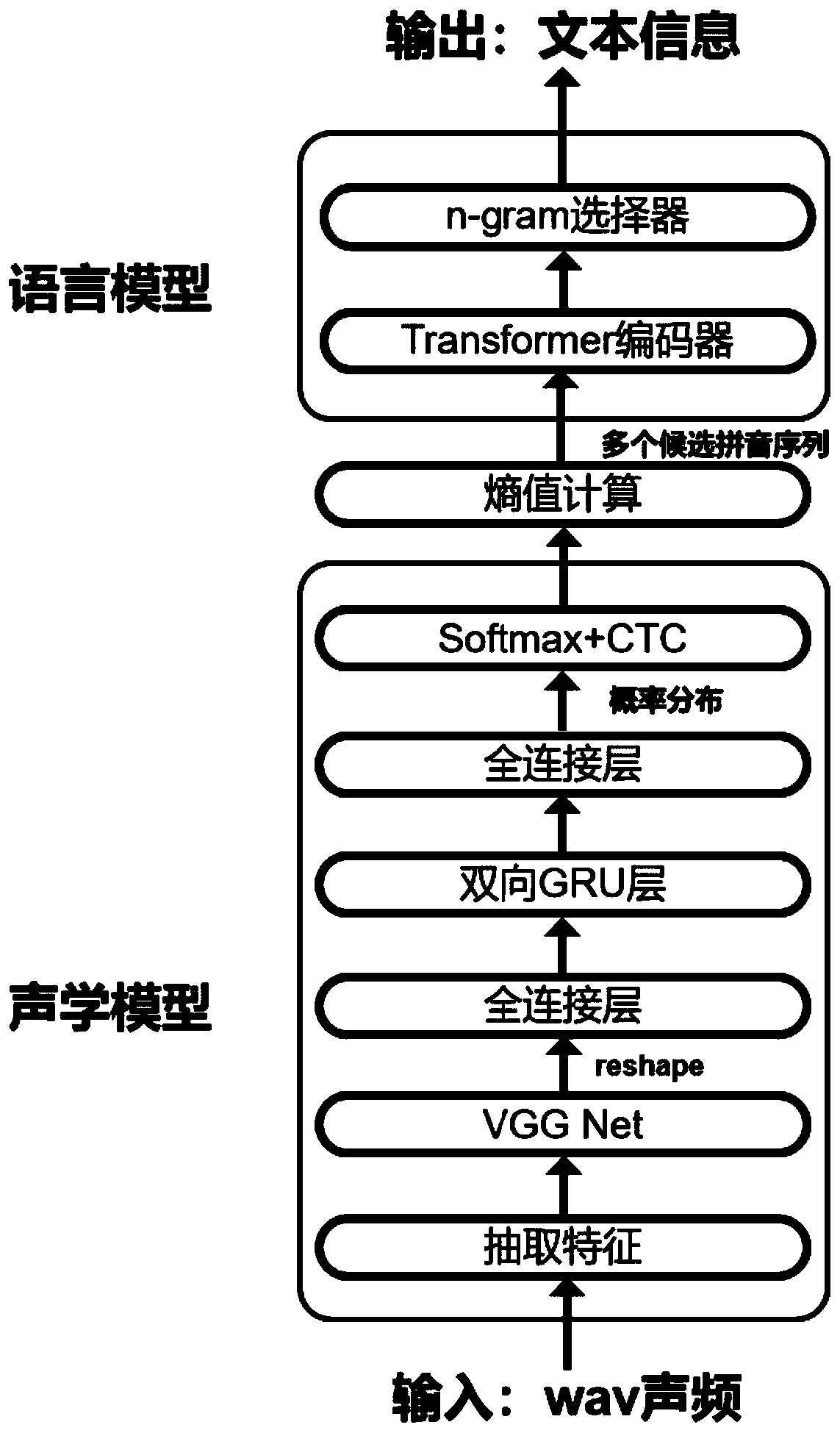
[0023] Such as figure 1 As shown, the present invention is based on the end-to-end speech recognition system of deep learning, including:
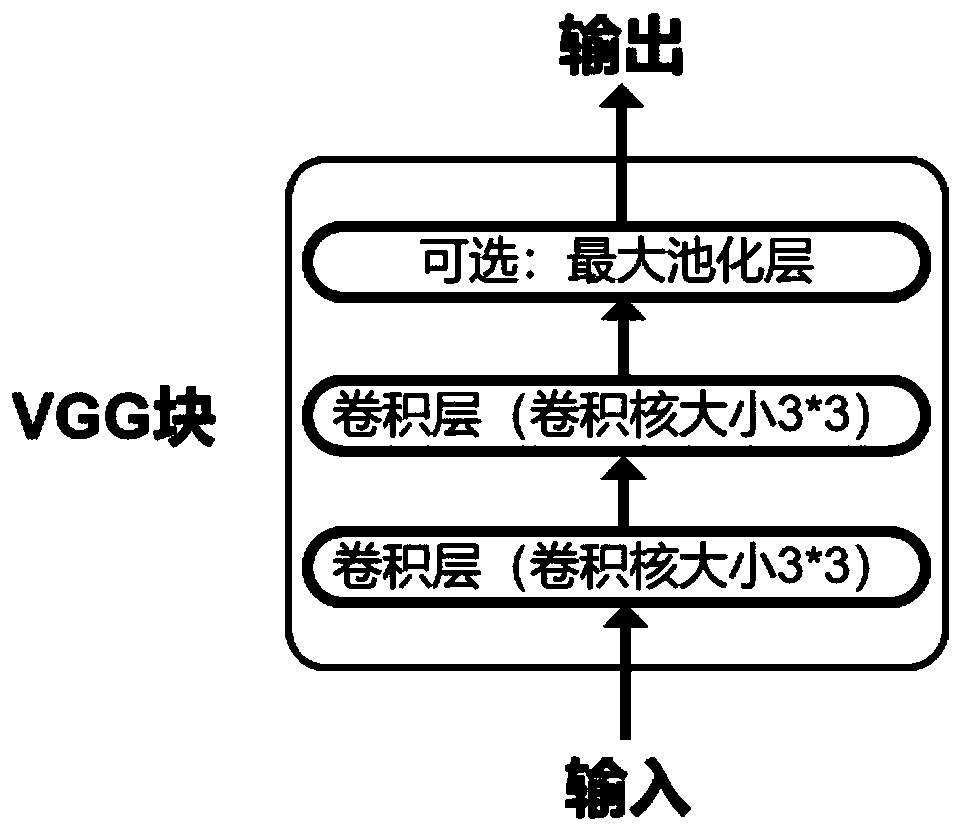
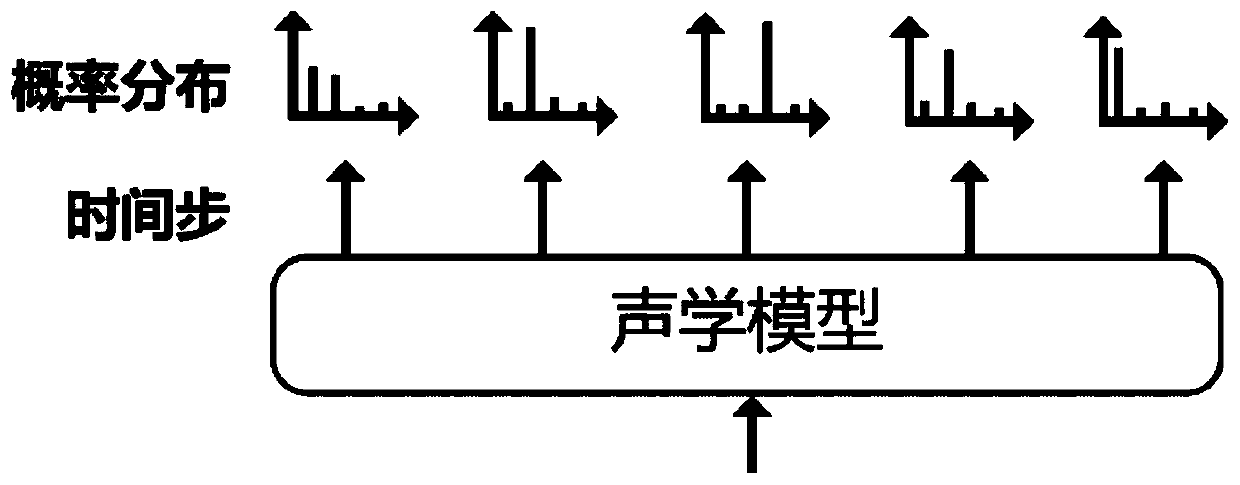
[0024] The acoustic model includes the VGG-Net layer, the first fully connected layer, the bidirectional RNN layer, the second fully connected layer, the Softmax layer and the CTC layer in turn, which are used to extract the two-dimensional FBank features of the audio, and pass through the VGG-Net layer , the first fully connected layer, the bidirectional RNN layer, the second fully connected layer, the Softmax layer, and the CTC layer, after processing, the normalized probability distribution of each time step is obtained; and then the entropy v...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com