

Clustering analysis method based on sample density and self-adaptive adjustment of clustering center
A self-adaptive adjustment and clustering center technology, applied in character and pattern recognition, instruments, computer components, etc., can solve problems such as restrictive effects, difficult to determine the cost, and large influence of the initial value of the clustering result
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
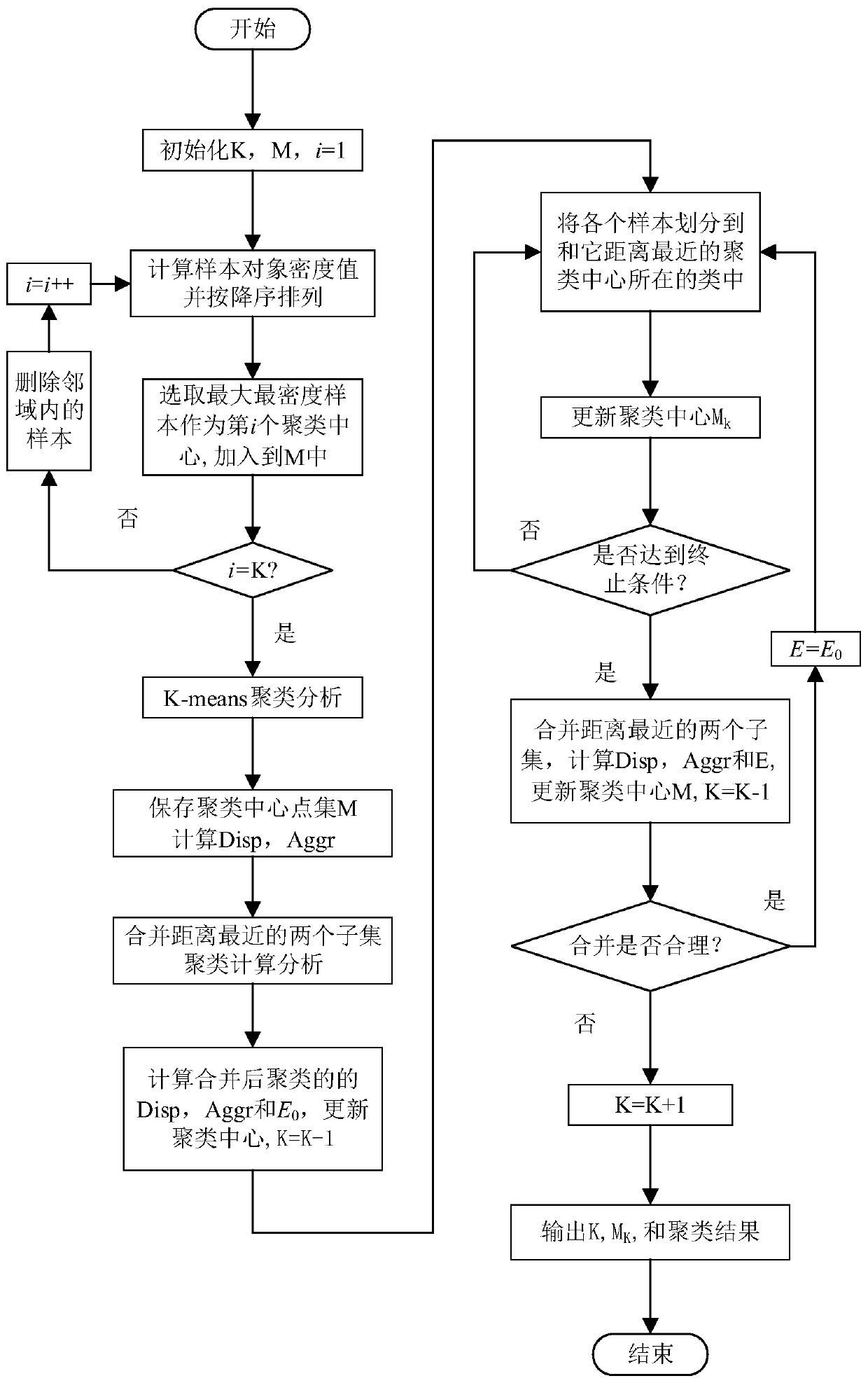
[0057] Now in conjunction with embodiment, accompanying drawing, the present invention will be further described:
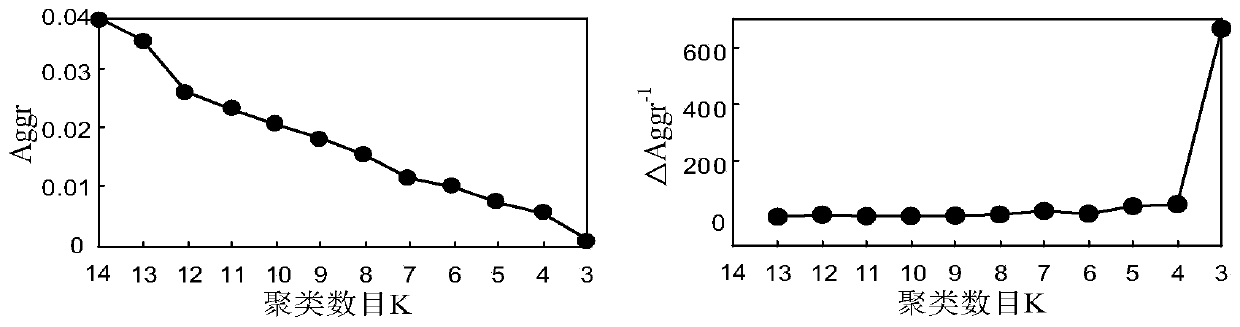
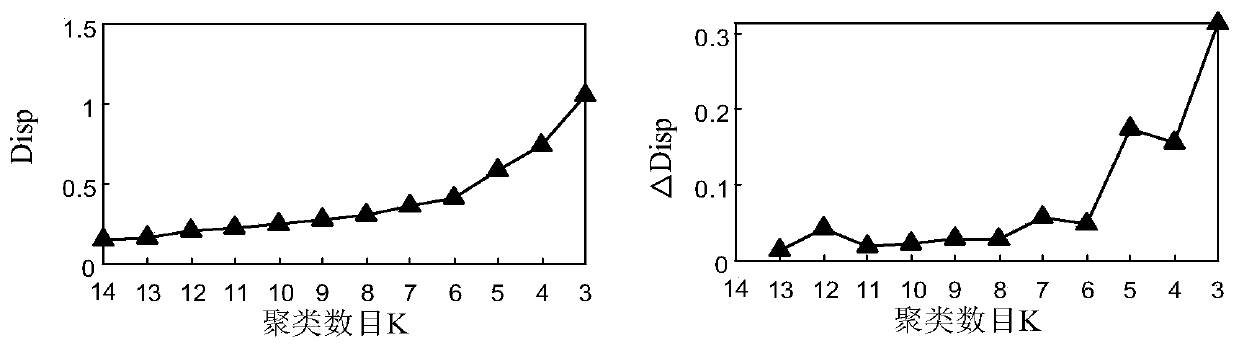
[0058] The invention improves the traditional K-means algorithm from two aspects of selecting a suitable initial cluster center and adaptively adjusting the number of clusters. First, the number of clusters K and the cluster center are initialized based on the sample density and sample neighborhood, and then the method of nearest neighbor cluster merging is used to adaptively adjust the number of clusters K, and finally the best clustering result is obtained.
[0059] A kind of cluster analysis method based on sample density and self-adaptive adjustment cluster center is characterized in that comprising the following steps:
[0060] (1) Select the initial cluster center
[0061] Step1: Initialize the number of clusters Initialize the center point set
[0062] Step2: Dataset X={x for clustering processing 1 ,x 2 ,...,x i ,...,x n}, each sample object con...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More