

Parallel depth forest classification method based on information theory improvement
A classification method and information theory technology, applied in the field of parallel deep forest classification, can solve the problem of not considering the redundancy of large data sets and irrelevant features, too many multi-granularity scanning imbalances, etc., and achieve the effect of improving clustering accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

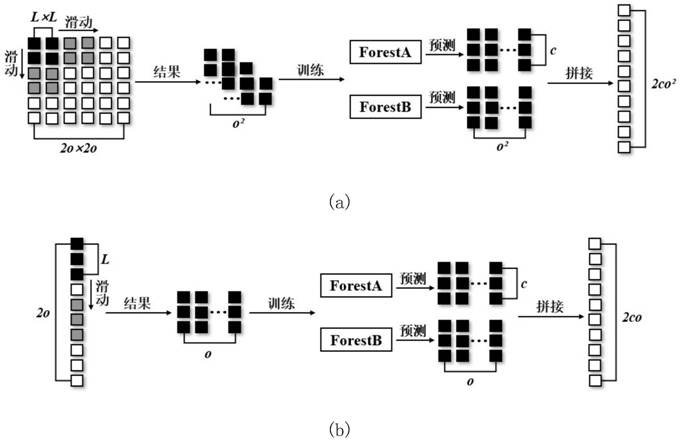
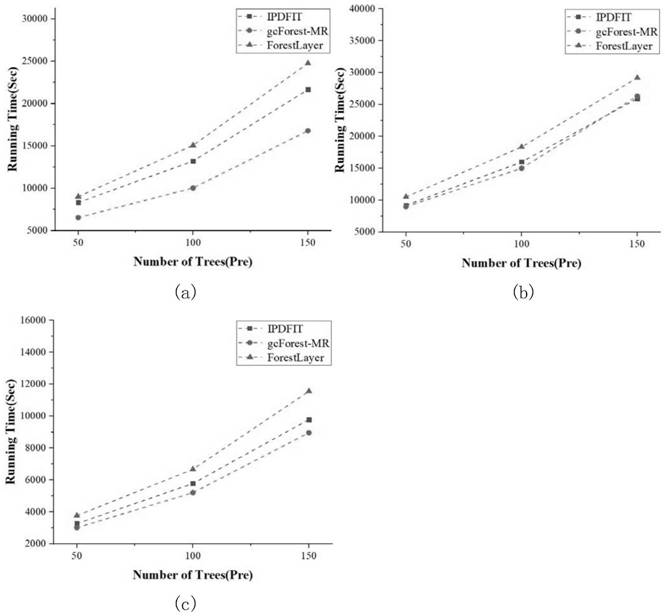
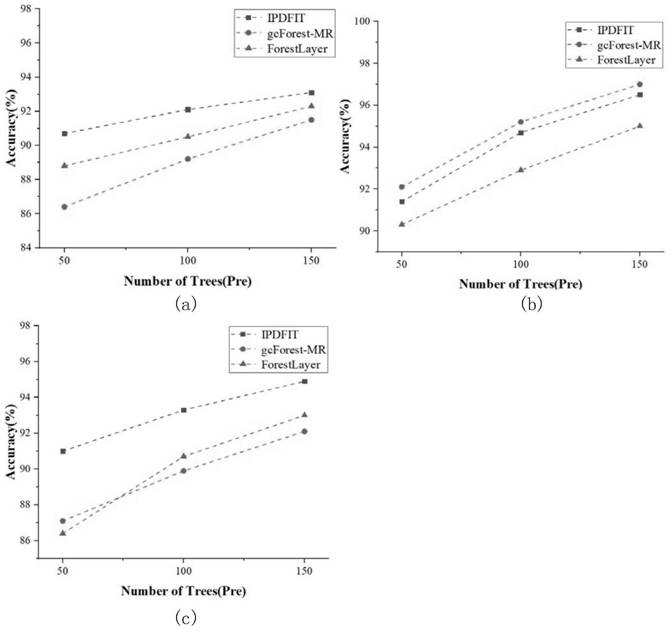
Examples
Embodiment 1
[0118] In this embodiment, medical images are used to further illustrate the present invention. Parallel deep forest classification of medical images can quickly eliminate irrelevant features, multi-layer training samples, and form a refined classification model; it is beneficial to reduce the learning cost of doctors and quickly improve The doctor's experience and practical level, as well as the sharing of medical pressure and the overall improvement of medical level.
[0119] Represents n samples in the d-dimensional feature space of the original medical image dataset DB, Indicates the medical image label vector corresponding to the medical image feature matrix X.
[0120] S1. First, use the default file block strategy in Hadoop to divide the feature space of the original medical image data set into data blocks of the same size. Then, the data block is used as input data. According to definition 1, the Mapper node calls the Map function The information gain of each featu...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More