

Semantic parsing method and device for voice
A technology of semantic parsing and speech, applied in the field of communication, can solve the problem of low accuracy of semantic parsing in the field of music, and achieve the effect of improving the success rate of interaction and improving the accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
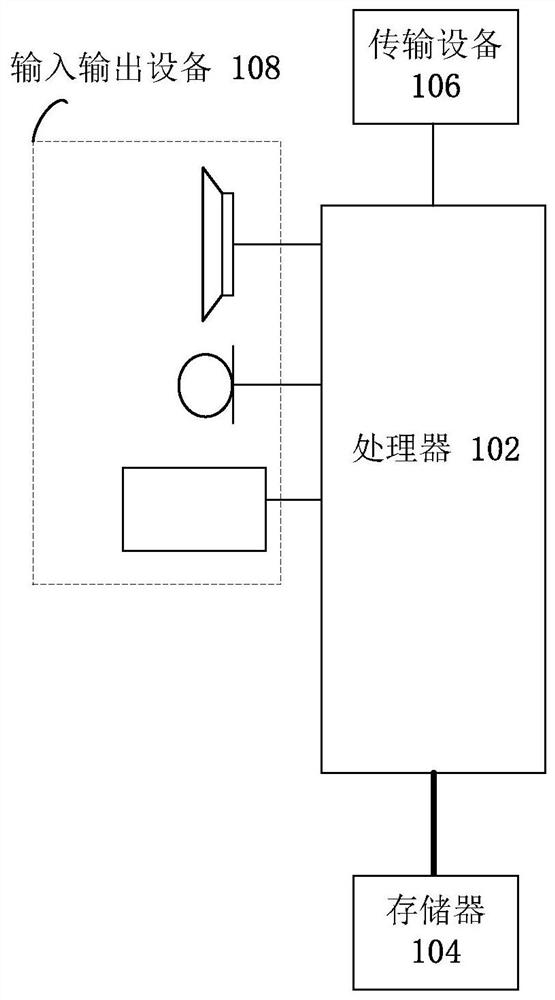
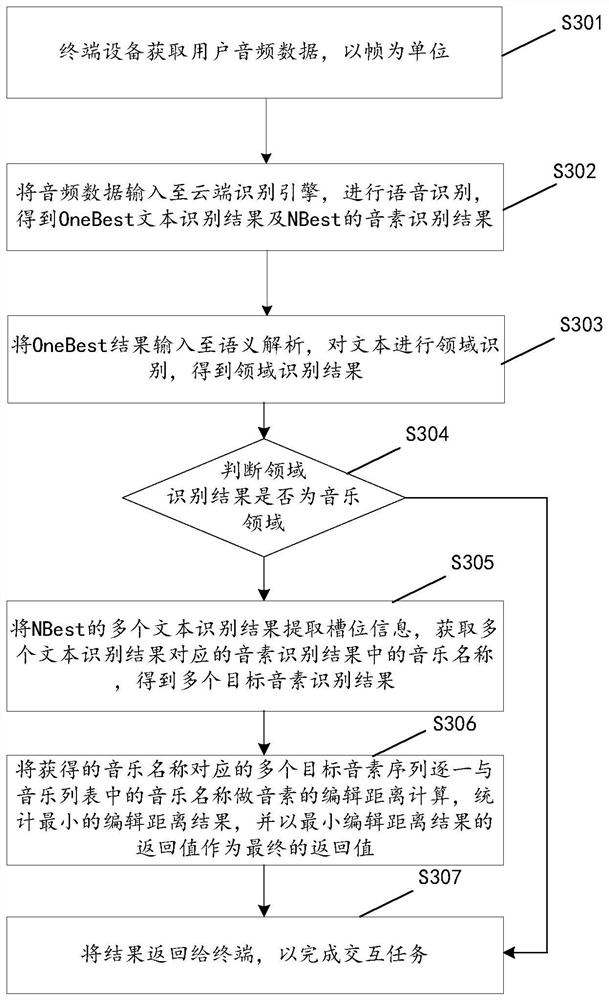
[0072] The method embodiment provided in Embodiment 1 of the present application may be executed in a mobile terminal, a computer terminal, or a similar computing device. Taking running on a mobile terminal as an example, figure 1 It is a block diagram of the hardware structure of the mobile terminal of the semantic analysis method of the voice of the embodiment of the present invention, as figure 1 As shown, the mobile terminal may include one or more ( figure 1 Only one is shown in the figure) a processor 102 (the processor 102 may include but not limited to a processing device such as a microprocessor MCU or a programmable logic device FPGA) and a memory 104 for storing data. Optionally, the above-mentioned mobile terminal also A transmission device 106 for communication functions as well as input and output devices 108 may be included. Those of ordinary skill in the art can understand that, figure 1 The shown structure is only for illustration, and does not limit the st...
Embodiment 2
[0112] In this embodiment, there is also provided a speech semantic analysis device, which is used to implement the above embodiments and preferred implementation modes, and what has already been described will not be repeated. As used hereinafter, the term "module" may realize a combination of software and / or hardware for a predetermined function. Although the devices described in the following embodiments are preferably implemented in software, implementations in hardware, or a combination of software and hardware are also possible and contemplated.
[0113] Figure 4 is a block diagram of a semantic analysis device for speech according to an embodiment of the present invention, such as Figure 4 shown, including:
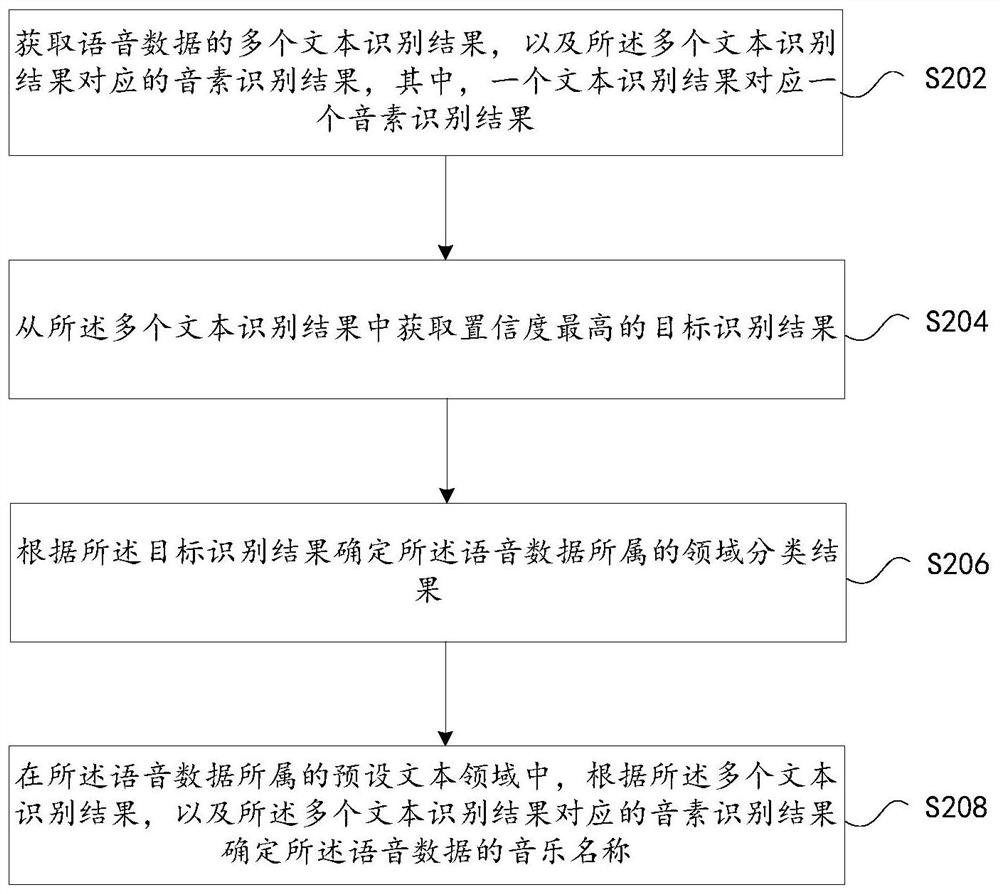
[0114] The first acquisition module 42 is configured to acquire a plurality of text recognition results of the voice data, and phoneme recognition results corresponding to the plurality of text recognition results, wherein one text recognition result co...
Embodiment 3
[0141] An embodiment of the present invention also provides a storage medium, in which a computer program is stored, wherein the computer program is set to execute the steps in any one of the above method embodiments when running.
[0142] Optionally, in this embodiment, the above-mentioned storage medium may be configured to store a computer program for performing the following steps:
[0143] S1. Acquire multiple text recognition results of speech data, and phoneme recognition results corresponding to the multiple text recognition results, wherein one text recognition result corresponds to one phoneme recognition result;
[0144] S2. Obtain the target recognition result with the highest confidence from the plurality of text recognition results;
[0145] S3. Determine the field classification result to which the voice data belongs according to the target recognition result;
[0146] S4. In the preset text domain to which the voice data belongs, determine the musi...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More