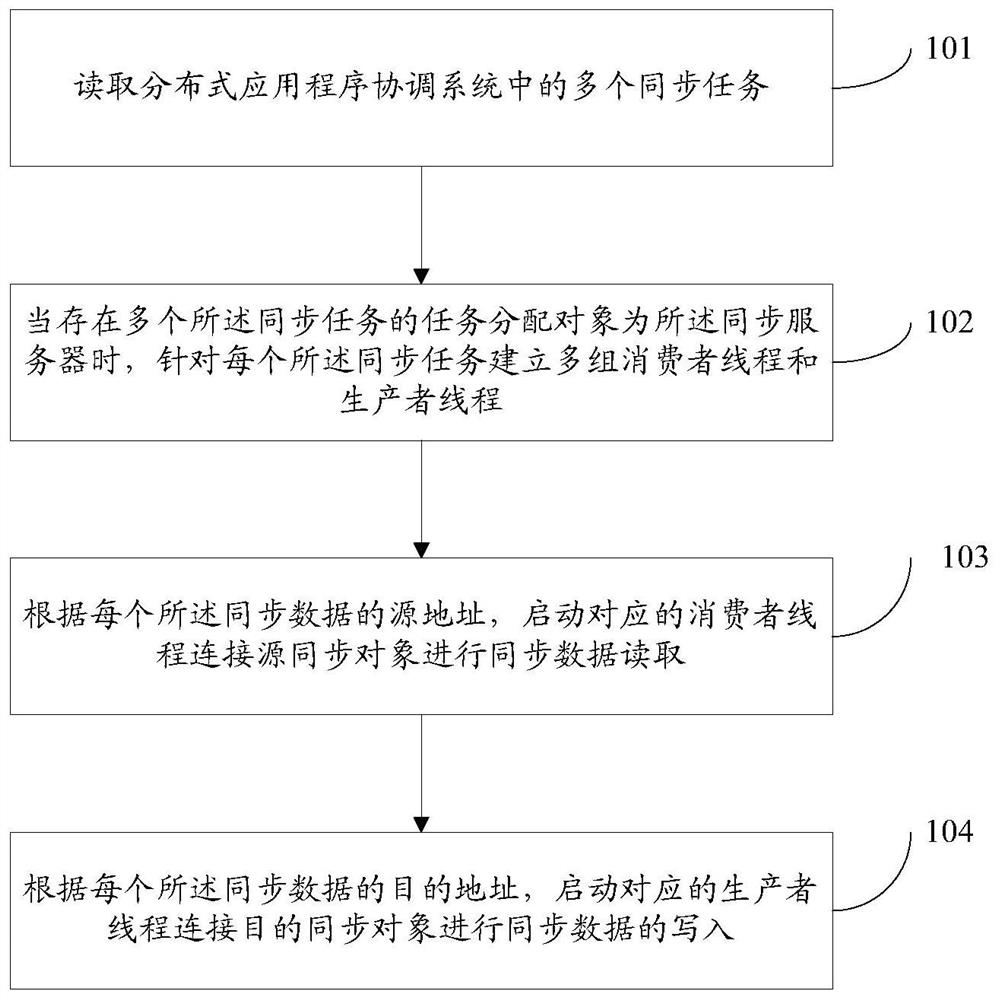
Data synchronization method, device and system and storage medium
A data synchronization and data synchronization technology, which is applied in the field of information processing, can solve the problems that the uReplicator cluster cannot realize the synchronization of a large amount of data, and achieve the effects of high concurrency, synchronization, and improved utilization
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
example 1
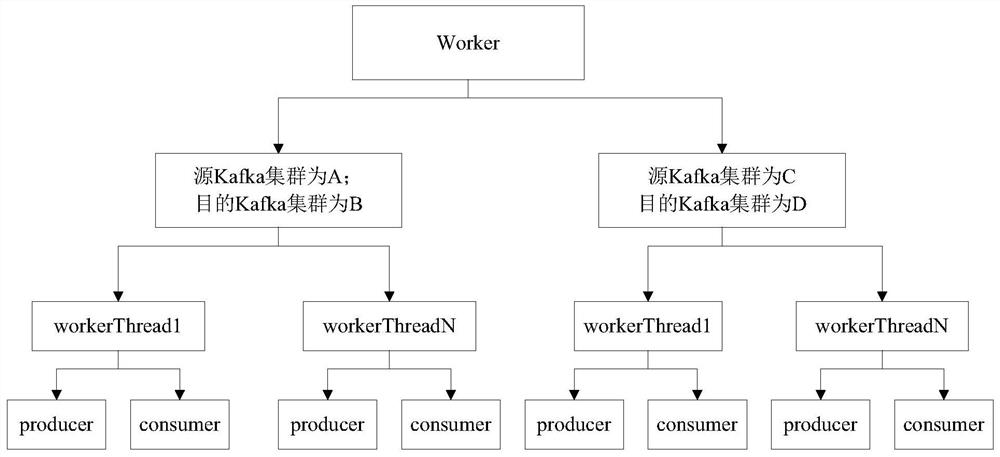
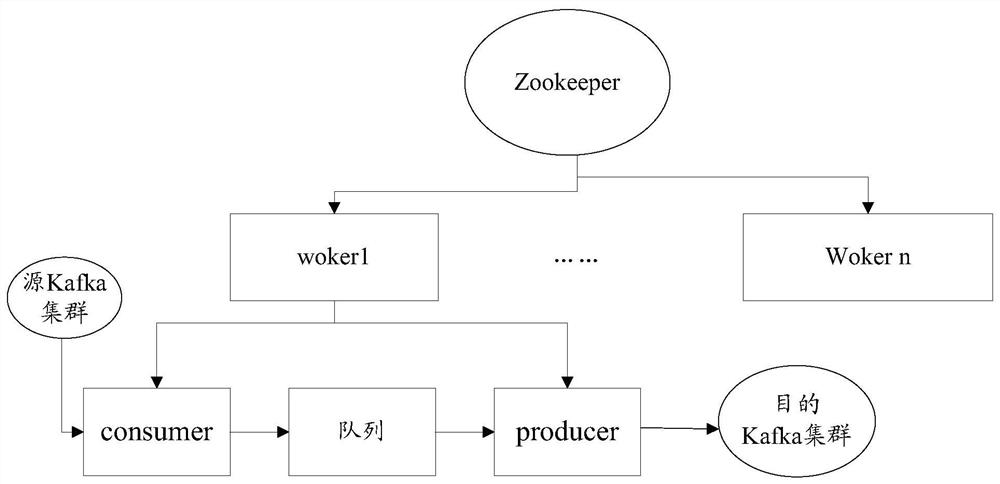
[0187] Example 1. The source address is the address of the Kafka cluster, and the destination address is the address of the Kafka cluster. When it is necessary to synchronize topicA in the source Kafka cluster cluster1 to topicB in the destination Kafka cluster cluster2, topicA and topicB have three partitions, two The data synchronization process between Kafka clusters is as follows:
[0188] After the control server receives the data synchronization request, it sends a synchronization task request. The synchronization task request includes: the address of the source Kafka cluster cluster1, the address of the destination Kafka cluster cluster2; source topicA, the number of partitions is 3, respectively partition0, partition1, partition2 , purpose topicB.
[0189] After the control server receives the task request, it assigns the task, and assigns the three partitions of topicA to different workers for data synchronization.
[0190] In this step, you can assign partition0 to ...
example 2
[0192] Example 2, the source address is the Kafka cluster address, and the destination address is HDFS. When it is necessary to synchronize topicA in the source Kafka cluster cluster1 to the HDFS directory corresponding to the destination HDFS, topicA has 3 partitions, and data synchronization between the Kafka cluster and HDFS The process is as follows:
[0193] After the control server receives the data synchronization request, it sends a synchronization task request. The synchronization task request includes: the address of the source Kafka cluster cluster1, the destination HDFS address; the source topicA, the number of partitions is 3, which are partition0, partition1, partition2, and destination HDFS Table of contents.
[0194] After the control server receives the task request, it assigns the task, and assigns the three partitions of topicA to different workers for data synchronization.
[0195] In this step, you can assign partition0 to worker1, partition1 to worker2, ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com