

Video encoding and decoding method and system
A video codec and video frame technology, which is applied in the field of video codec methods and systems, can solve problems such as slow model convergence, large computing power, and loss, and achieve the effect of smooth logic and coherent semantics
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
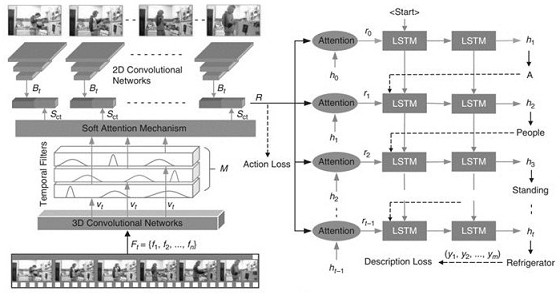
[0030] The present invention proposes a mixed 2D / 3D convolutional network (Mixed 2D / 3D Convolutional Networks, MCN). By constructing a dual-branch network structure, the first branch uses a 2D convolutional network to generate the features of each frame, and the second branch uses a 3D convolutional network to extract global feature information in all frames of the video.
[0031] Construct a deep fusion of video static and dynamic information: first sample a fixed number of frames throughout the video to cover the long-range temporal structure for understanding the video. The sampled frames span the entire video regardless of the length of the video. Therefore, we use a constant number of frame sequences Frame-by-frame input of 2D convolutional network branches to generate single-frame visual features , which represents the sampling frame number. The 2D convolutional network here uses the Inception v3 network pre-trained by ImageNet as the backbone network to extract all...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More