

Implementation scheme for improving Impala query capacity
A scheme and capacity technology, applied in the field of big data, which can solve the problems that table metadata cannot be updated and query operations cannot be performed.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
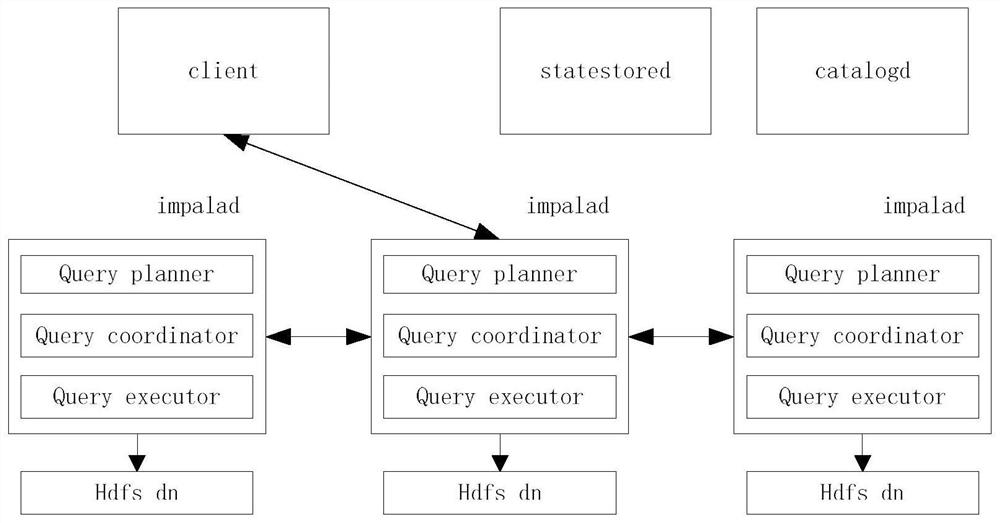
[0022] The invention discloses an implementation scheme for improving the query capacity of Impala, which comprises the following steps:
[0023] Step 1: Save the collected, filtered and preprocessed data from the data source in the Hadoop cluster;
[0024] In this step, the data collected, filtered and preprocessed from the data source includes structured data and unstructured data; the data source includes a variety of different types of data sources, and the collected data is stored in the Hadoop cluster by partition in HDFS.
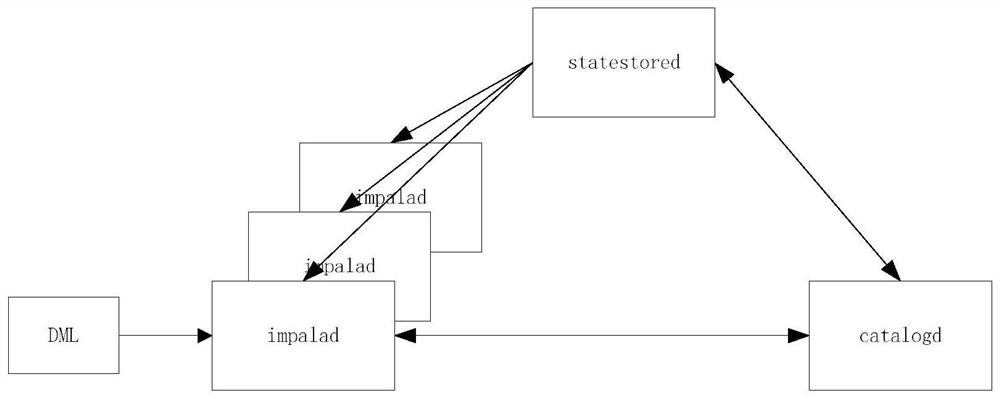
[0025] Step 2: If image 3 As shown, after Impala associates with the Hadoop cluster, it serializes all file metadata in the table and stores them in the memory database Redis;
[0026] In this step, serializing all file metadata in the table and storing it in the memory database Redis includes the following steps:
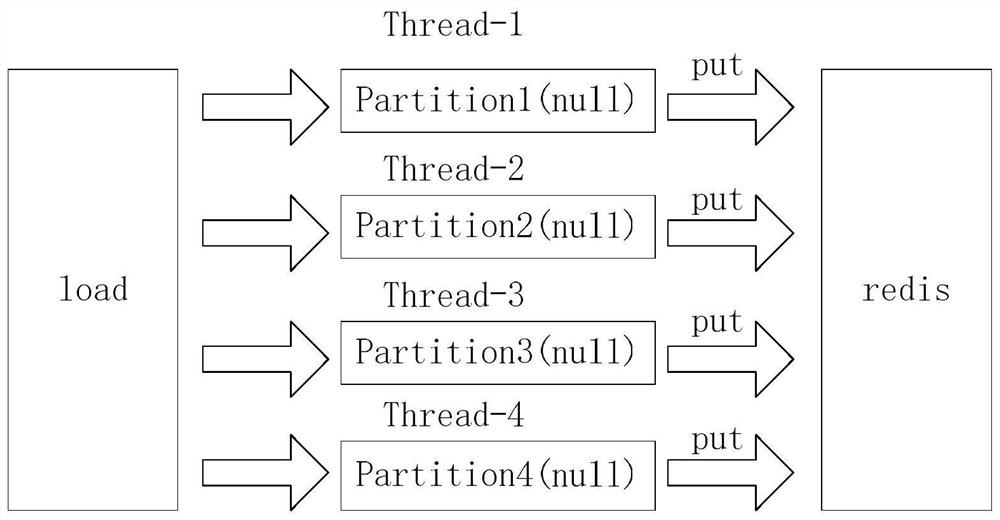
[0027] Step 2.1: Impala opens the Redis connection switch;
[0028] Step 2.2: Configure the thread pool;
[0029] Step 2.3: When m...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More