Flexible Huffman tree approximation for low latency coding
A coding and coding technology, applied in the field of flexible Huffman tree approximation for low-latency coding, can solve problems such as inefficient computing resources
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

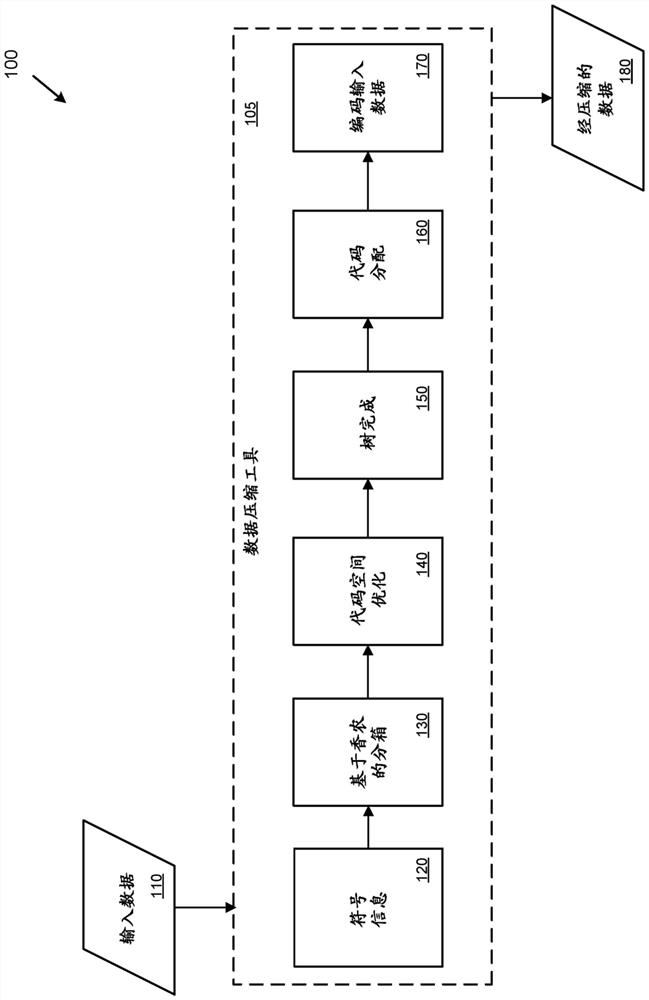
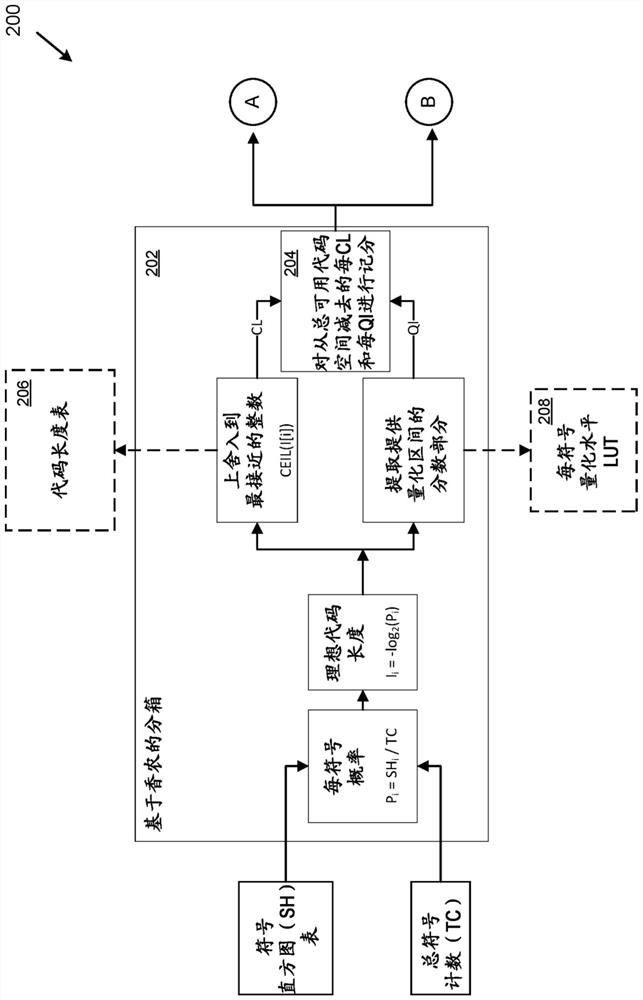
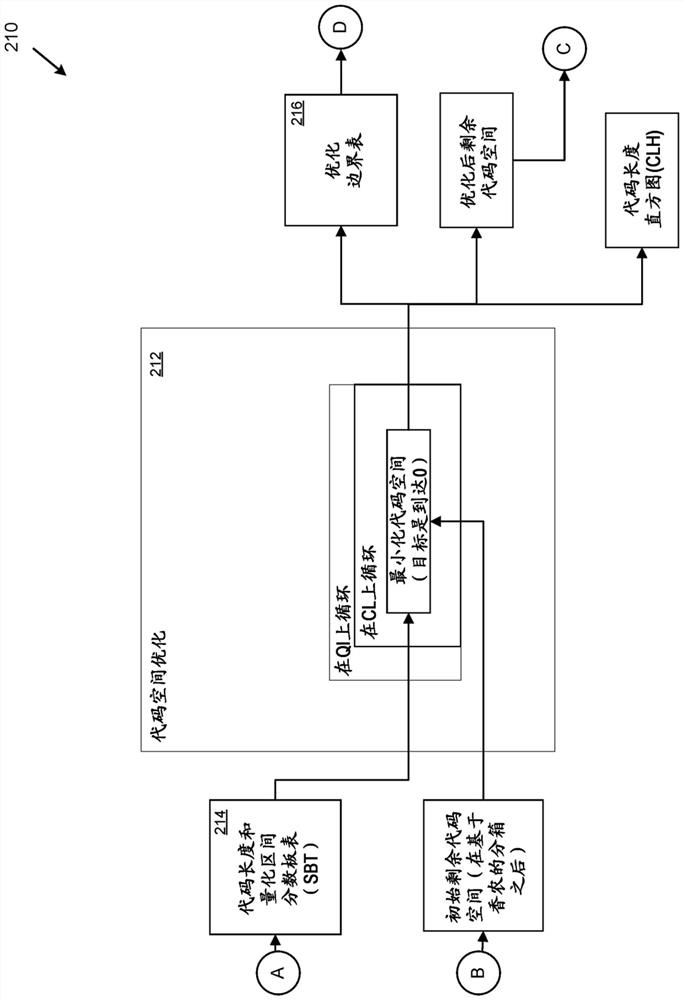
Examples
Embodiment Construction
[0012] overview
[0013] As described herein, various techniques and technical solutions can be applied to approximate the Huffman coding algorithm (also known as Huffman algorithm, Huffman decoding, or Huffman coding) without using Huffman coding algorithm. For example, these techniques can be applied to encode (e.g., compress) data that gets close to (e.g., within one percent) Huffman coding but is more efficient (e.g., in terms of computing resources, latency, , hardware implementation, etc.) compression.
[0014] The technique involves a new algorithm for approximating the Huffman algorithm. The new algorithm is also known as Quantization Interval Huffman Approximation (QuIHA).
[0015] Depending on the implementation, the new algorithm may have one or more of the following properties:
[0016] * It yields good compression ratios, typically within 0.05% of true Huffman coding, which is provably optimal.
[0017] *It is suitable for high-speed implementation in Field P...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com