

Data space heterogeneous data automatic fusion method based on unsupervised learning clustering algorithm
An unsupervised learning and clustering algorithm technology, applied in the field of data integration, can solve the problem that the accuracy of matching cannot be guaranteed, the heterogeneous synonymy of attribute names is not considered, and the conflict of value data cannot be solved, so as to achieve accurate matching and solve matching problems. precise effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

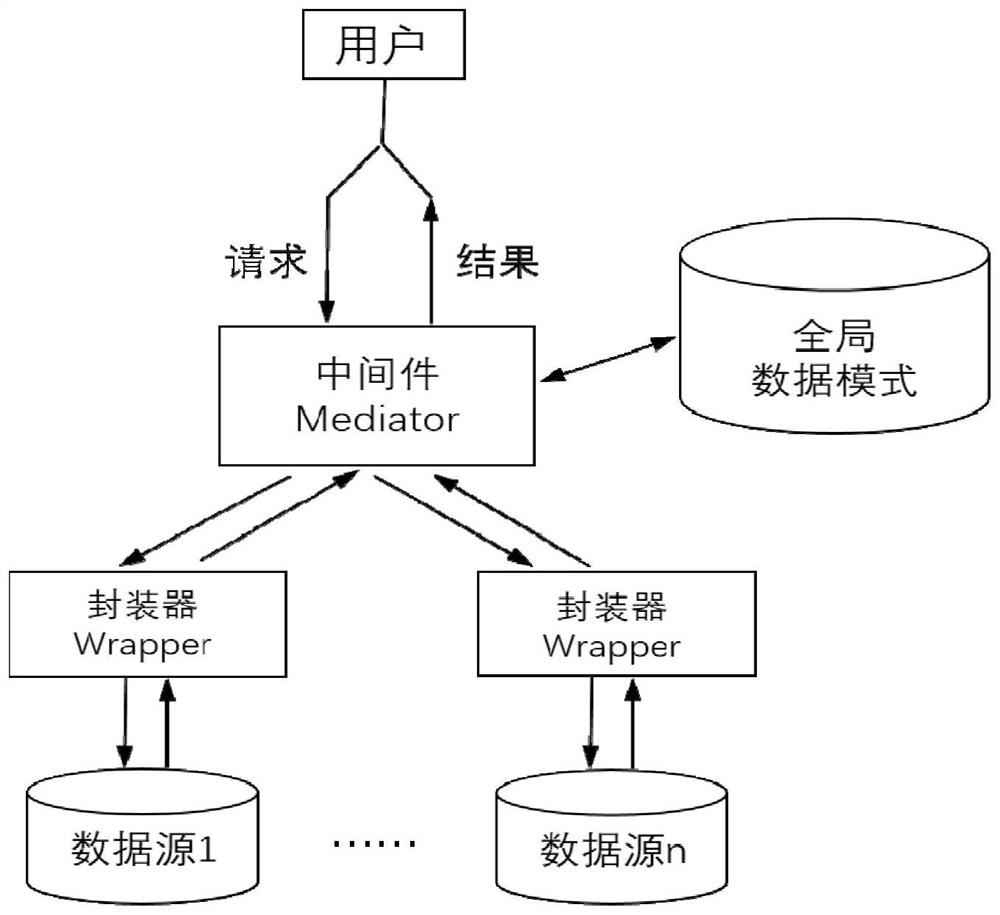


Examples
Embodiment 1
[0048] like figure 2 As shown, the method for automatic fusion of heterogeneous data in data space based on unsupervised learning clustering algorithm includes the following steps:
[0049] S1. Obtain heterogeneous data, and preprocess the heterogeneous data;
[0050] S2. Perform schema extraction on the preprocessed heterogeneous data to obtain attribute names and attribute values of the heterogeneous data;
[0051] S3. Obtain the corpus, and pre-train the word embedding module through the corpus;
[0052] S4. Input the attribute name into the pre-trained word embedding module, and obtain the attribute name vector;
[0053] S5. Pre-select a target mode, determine whether the source mode and the target mode are consistent, if they are consistent, go to the next step, if they are inconsistent, input the attribute value into the hybrid matcher, and calculate the similarity between the source mode and the target mode of the attribute value , to determine whether the source ...
Embodiment 2
[0056] like figure 2 , image 3 As shown, the method for automatic fusion of heterogeneous data in data space based on unsupervised learning clustering algorithm includes the following steps:
[0057] S1. Obtain heterogeneous data, and preprocess the heterogeneous data;
[0058] S2. Perform schema extraction on the preprocessed heterogeneous data to obtain attribute names and attribute values of the heterogeneous data;
[0059] S3. Obtain the corpus, and pre-train the word embedding module through the corpus;
[0060] S4. Input the attribute name into the pre-trained word embedding module, and obtain the attribute name vector;
[0061] S5. Pre-select a target mode, determine whether the source mode and the target mode are consistent, if they are consistent, go to the next step, if they are inconsistent, input the attribute value into the hybrid matcher, and calculate the similarity between the source mode and the target mode of the attribute value , judging whether the ...
Embodiment 3
[0102] The method for automatic fusion of heterogeneous data in data space based on unsupervised learning clustering algorithm includes the following steps:
[0103] S1. Obtain heterogeneous data, and preprocess the heterogeneous data; in this embodiment, the data to be matched is loaded into the system through the open API interface of the source data, and it is checked in turn whether there is null value or abnormal data in each mode. If it is found that the data is incomplete, the data needs to be filled or discarded according to the actual storage requirements.
[0104] S2. Perform schema extraction on the preprocessed heterogeneous data to obtain the attribute names and attribute values of the heterogeneous data; in this embodiment, the complete data attribute names need to be extracted from each data source, and the same is stored in a file, the The file can be in txt or csv format.
[0105] S3. Obtain the corpus, and pre-train the word embedding module through the co...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More