

Word boundary probability estimating, probabilistic language model building, kana-kanji converting, and unknown word model building
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Benefits of technology
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
:
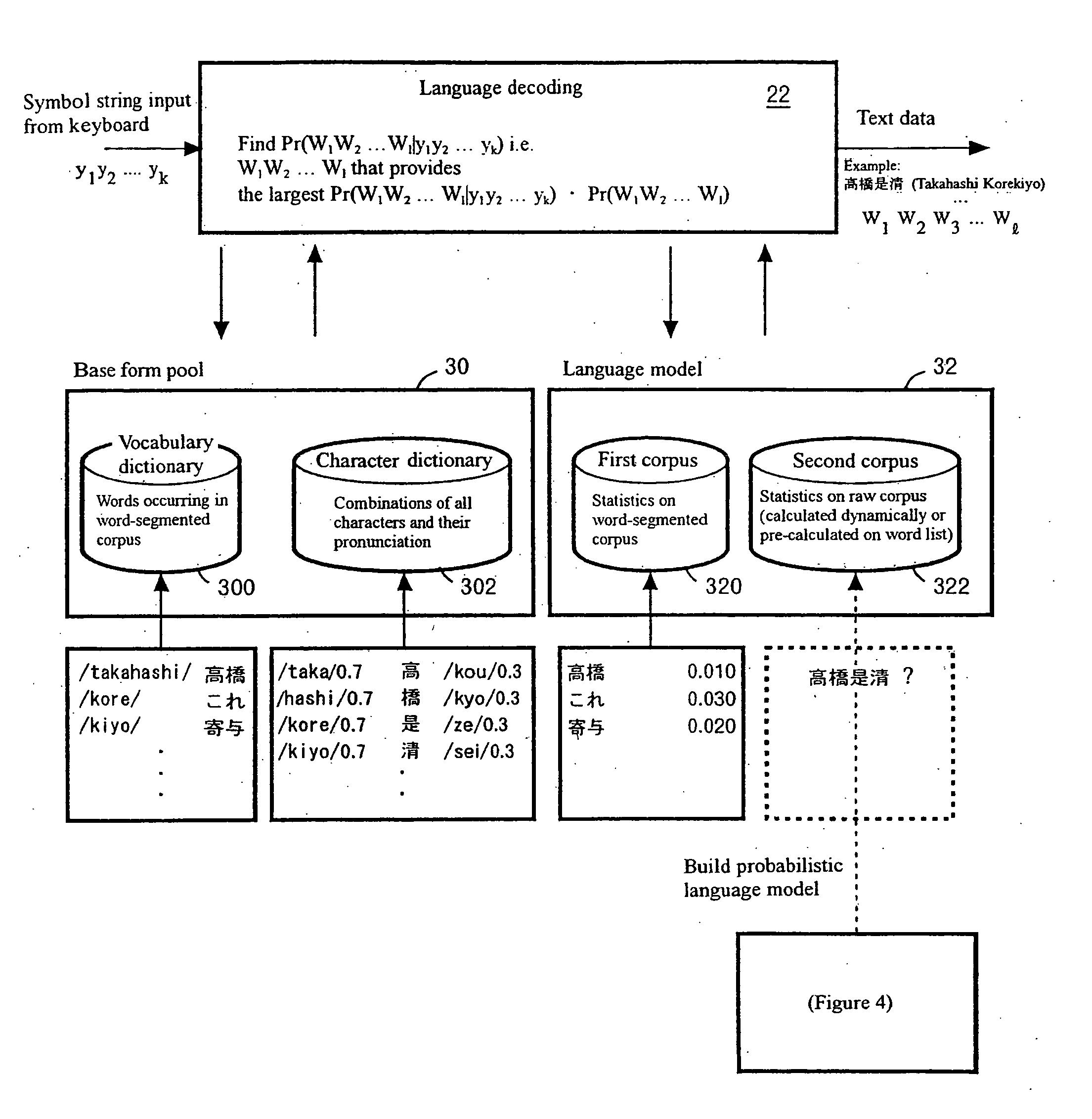
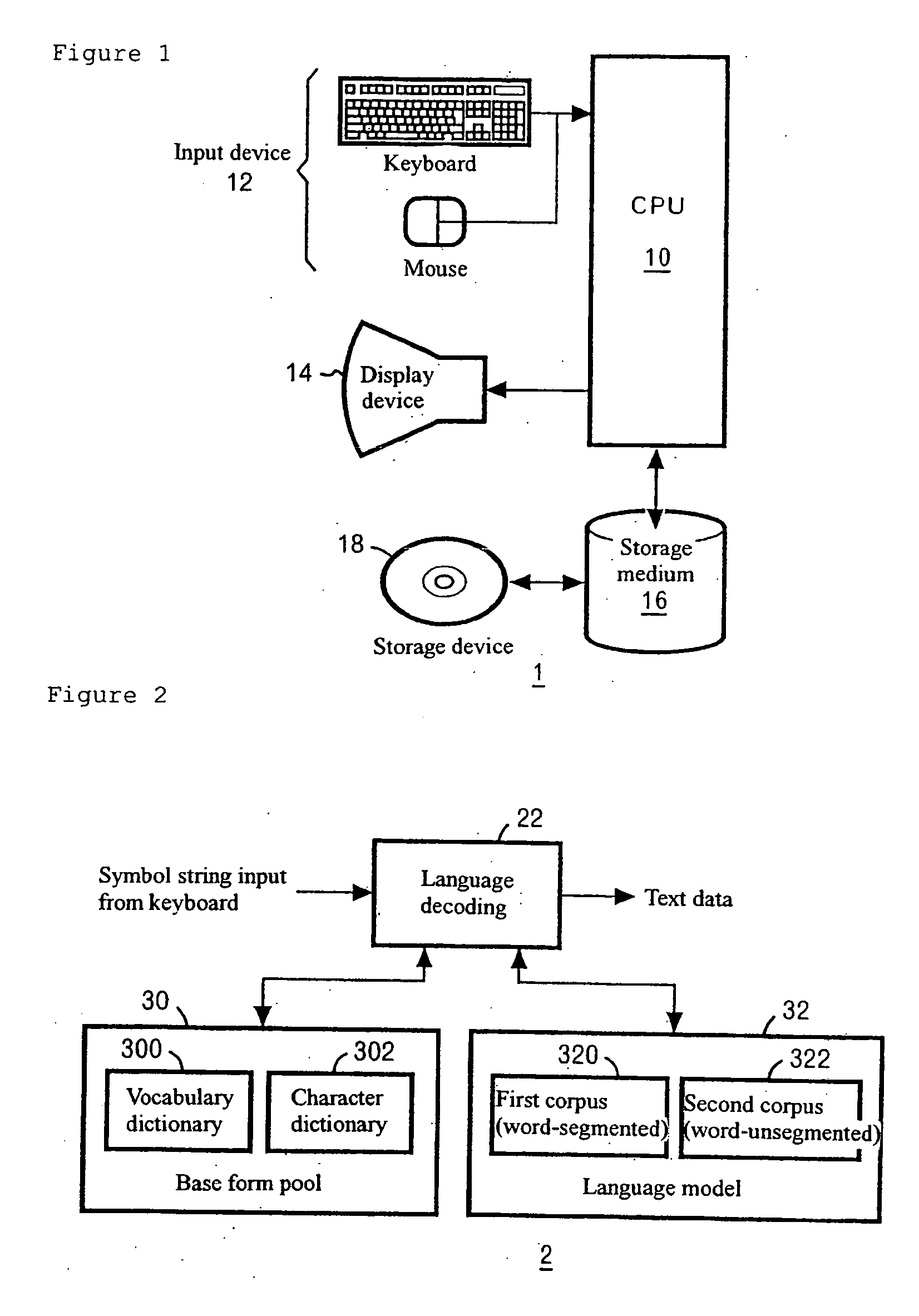
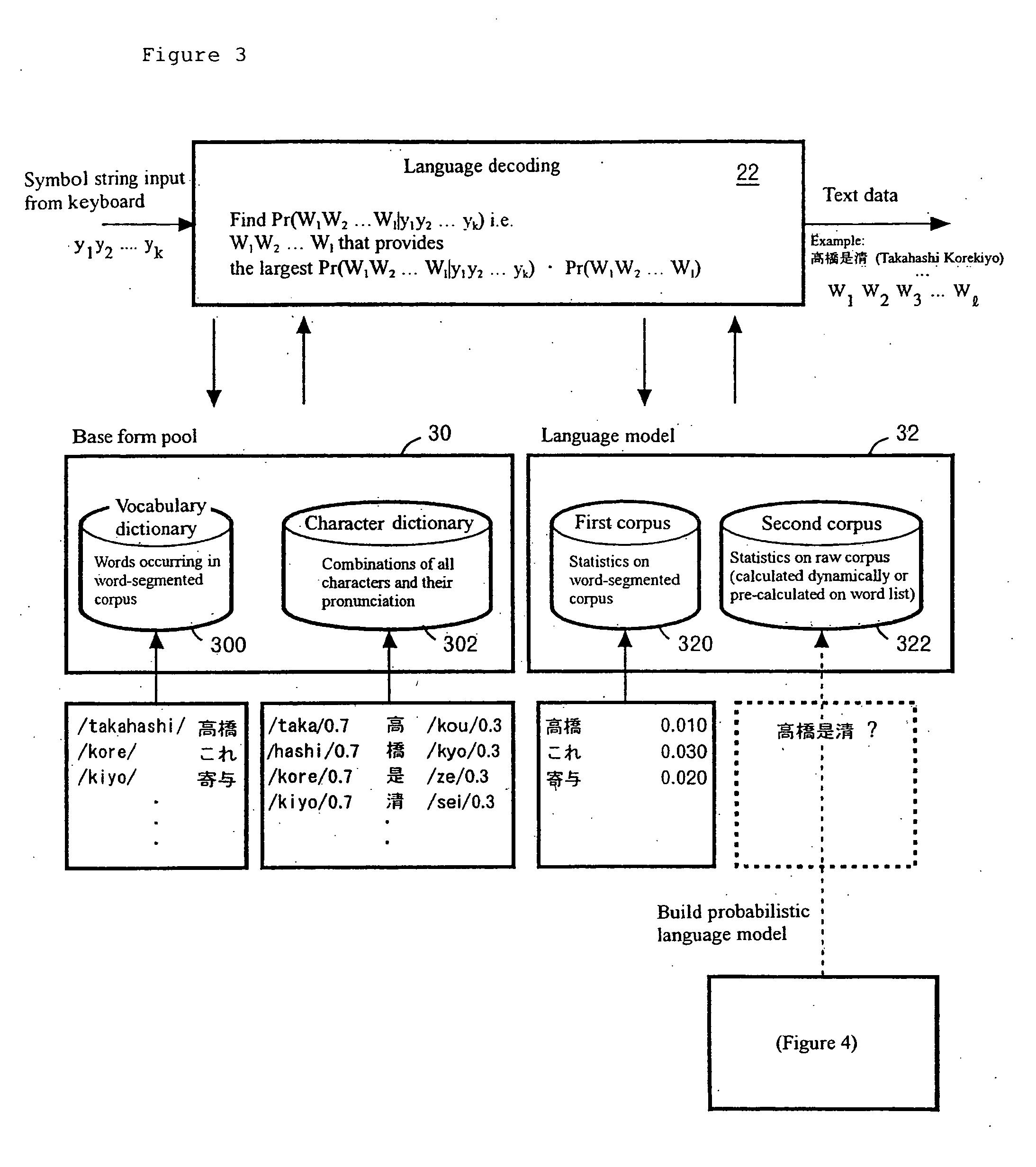
[0062] The present invention provides that a word n-gram probability is calculated with high accuracy in a situation where: [0063] (a) a first corpus (word-segmented), which is a relatively small corpus containing manually segmented word information, and [0064] (b) a second corpus (word-unsegmented), which is a relatively large corpus containing raw information are given as a training corpus that is storage containing vast quantities of sample sentences.
[0065] Vocabulary including contextual information is expanded from words occurring in the first corpus (word-segmented) of relatively small size to words occurring in the second corpus (word-unsegmented) of relatively large size by using a word n-gram probability estimated from an unknown word model and the raw corpus.
[0066] The first corpus (word-segmented) is used for calculating n-grams and the probability that the boundary between two adjacent characters will be the boundary of two words (segmentation probability). The second...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More