Method and apparatus for directionally grabbing page resource
A page resource and page technology, applied in the field of Internet resource collection, can solve the problems of missed pages and low recall rate, and achieve the effect of ensuring representativeness, improving efficiency, and ensuring accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

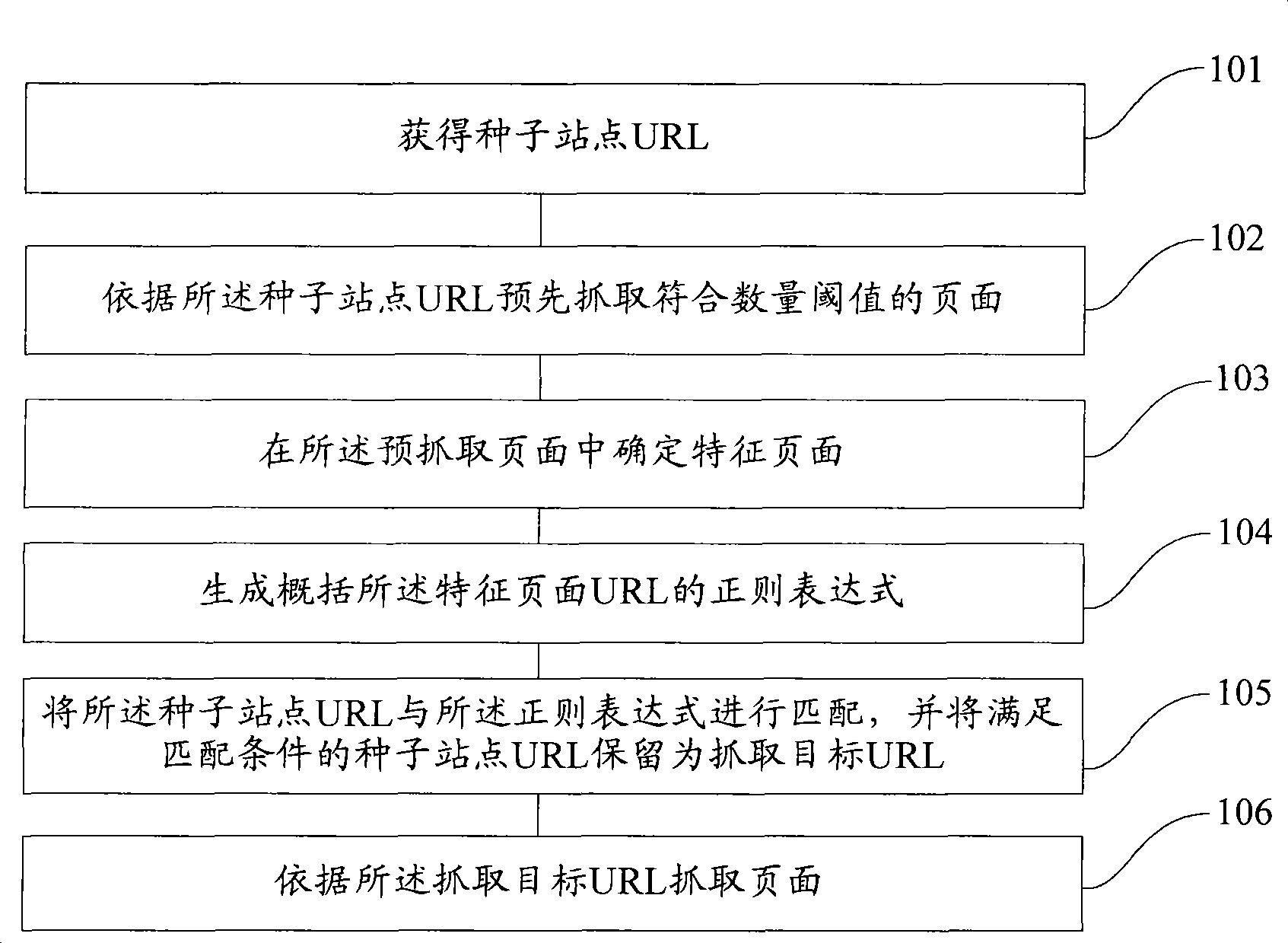
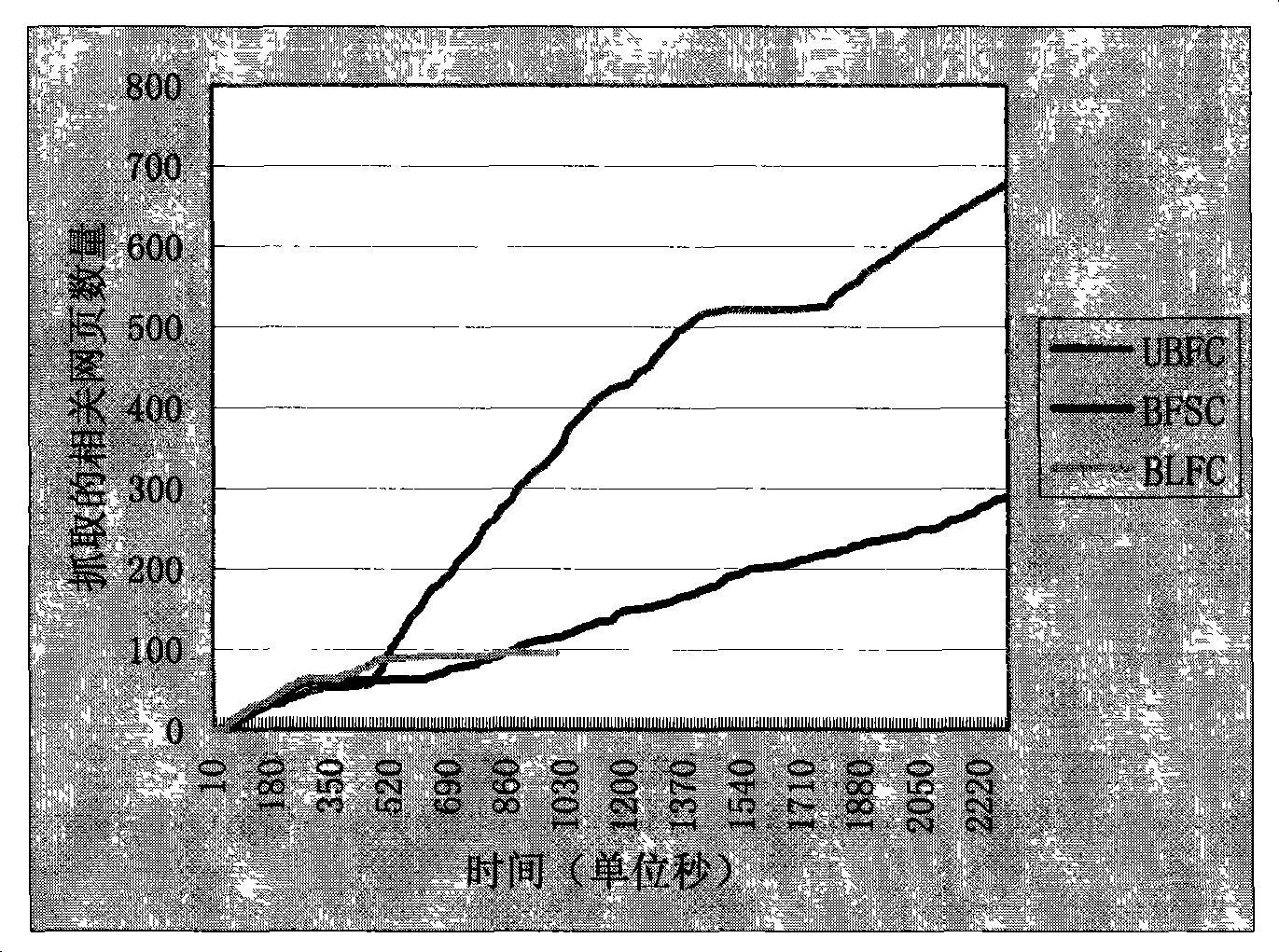
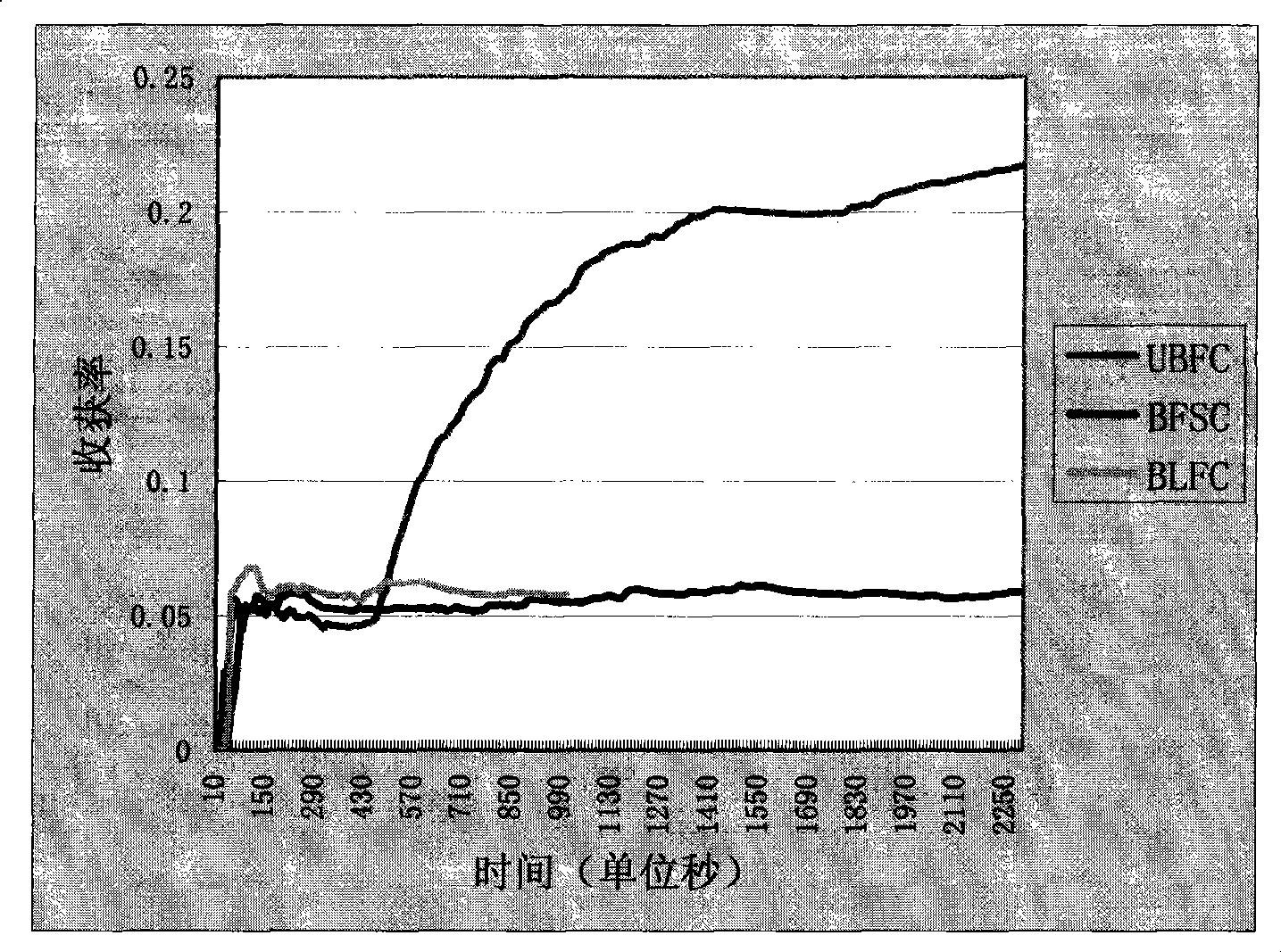
Examples
Embodiment Construction
[0093] In order to make the above objects, features and advantages of the present invention more comprehensible, the present invention will be further described in detail below in conjunction with the accompanying drawings and specific embodiments.
[0094] The invention is applicable to numerous general purpose or special purpose computing device environments or configurations. For example: personal computer, server computer, handheld or portable device, tablet type device, multiprocessor device, distributed computing environment including any of the above devices or devices, etc.
[0095] The invention may be described in the general context of computer-executable instructions, such as program modules, being executed by a computer. Generally, program modules include routines, programs, objects, components, data structures, etc. that perform particular tasks or implement particular abstract data types. The invention may also be practiced in distributed computing environments...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More