

Parallel PLSA (Probabilistic Latent Semantic Analysis) method based on Hadoop
A functional and overall technology, applied in the field of parallel implementation of PLSA, can solve the problems of slow running of PLSA, reduce the overall running time and improve the efficiency of operation
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0018] Below in conjunction with accompanying drawing and specific embodiment, further illustrate the present invention, should be understood that these embodiments are only for illustrating the present invention and are not intended to limit the scope of the present invention, after having read the present invention, those skilled in the art will understand various aspects of the present invention Modifications in equivalent forms all fall within the scope defined by the appended claims of this application.
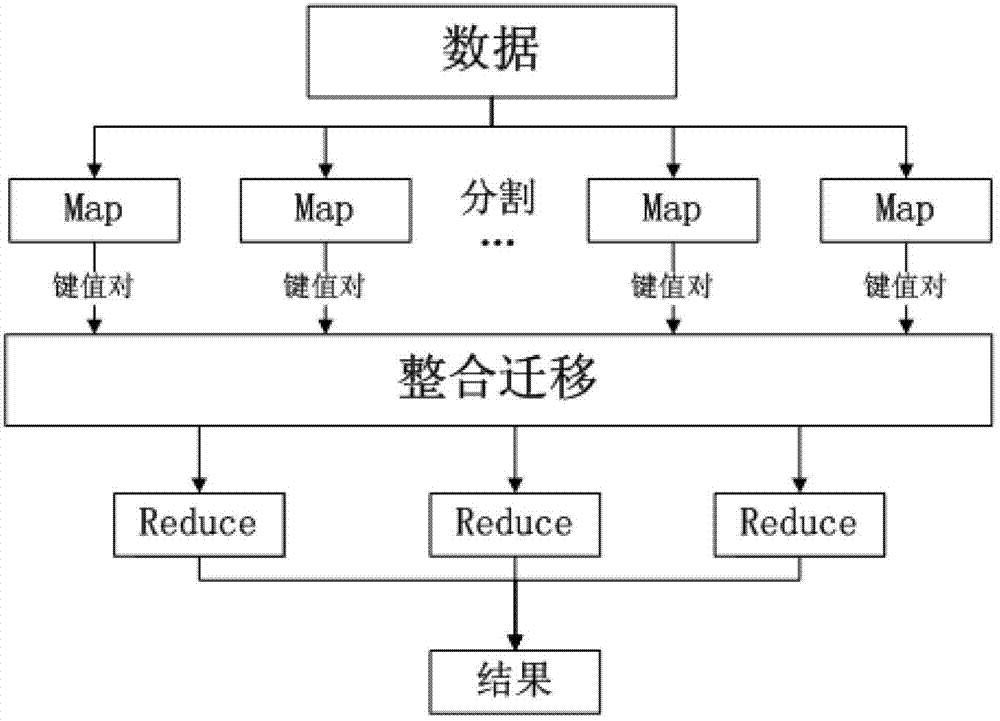
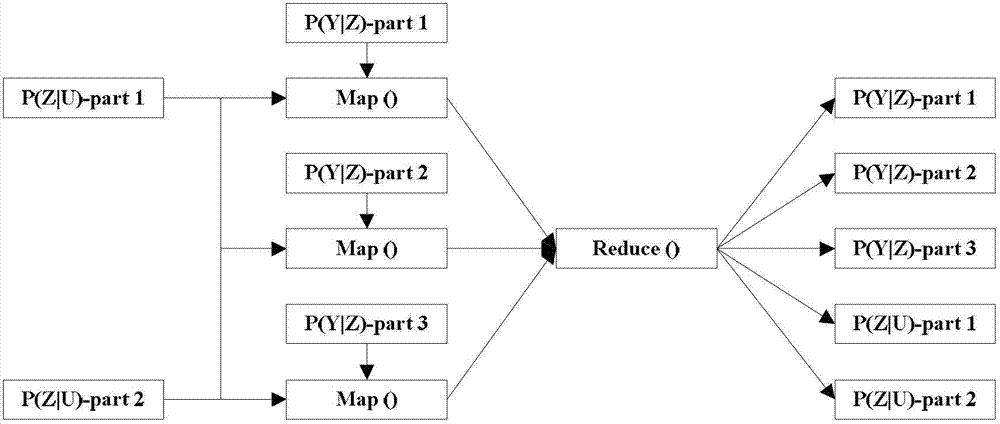
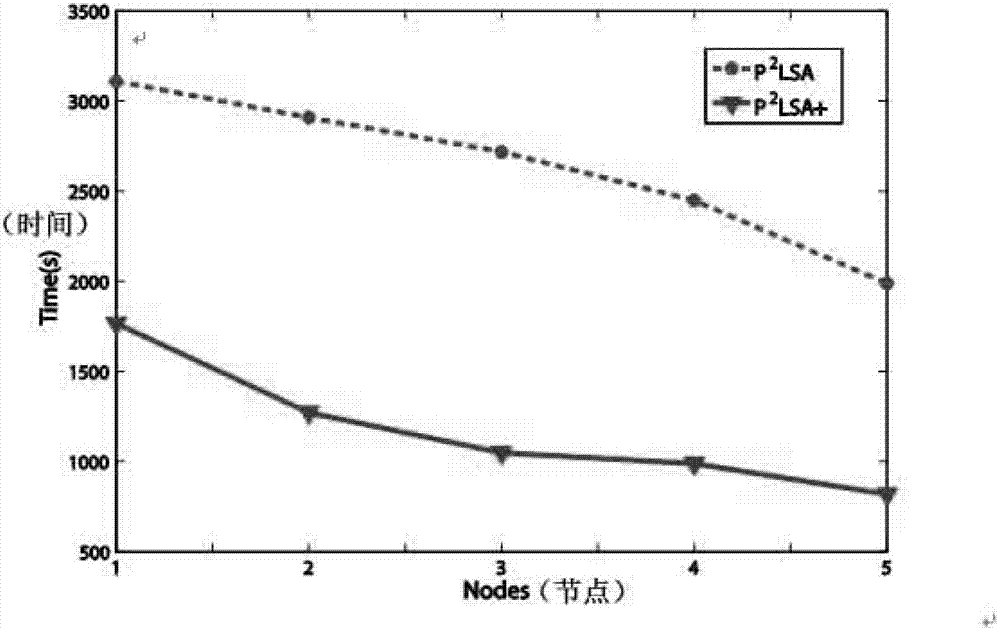
[0019] The present invention mainly realizes the parallelization of the algorithm through mapreduce, and its process is as follows figure 1 shown. and, if figure 2 As shown, for each probability result, the result obtained in the previous iteration can be used as the input to the next iteration, so as to realize the continuous update of the result until convergence.
[0020] Method 1 of the present invention is described in detail below:
[0021] The main idea of t...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More