Method and device for extracting webpage content
A webpage content and webpage technology, applied in the information field, can solve problems such as inaccurate extraction of webpage text, inaccurate extraction of webpage titles, incomplete extraction of various elements of webpages, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
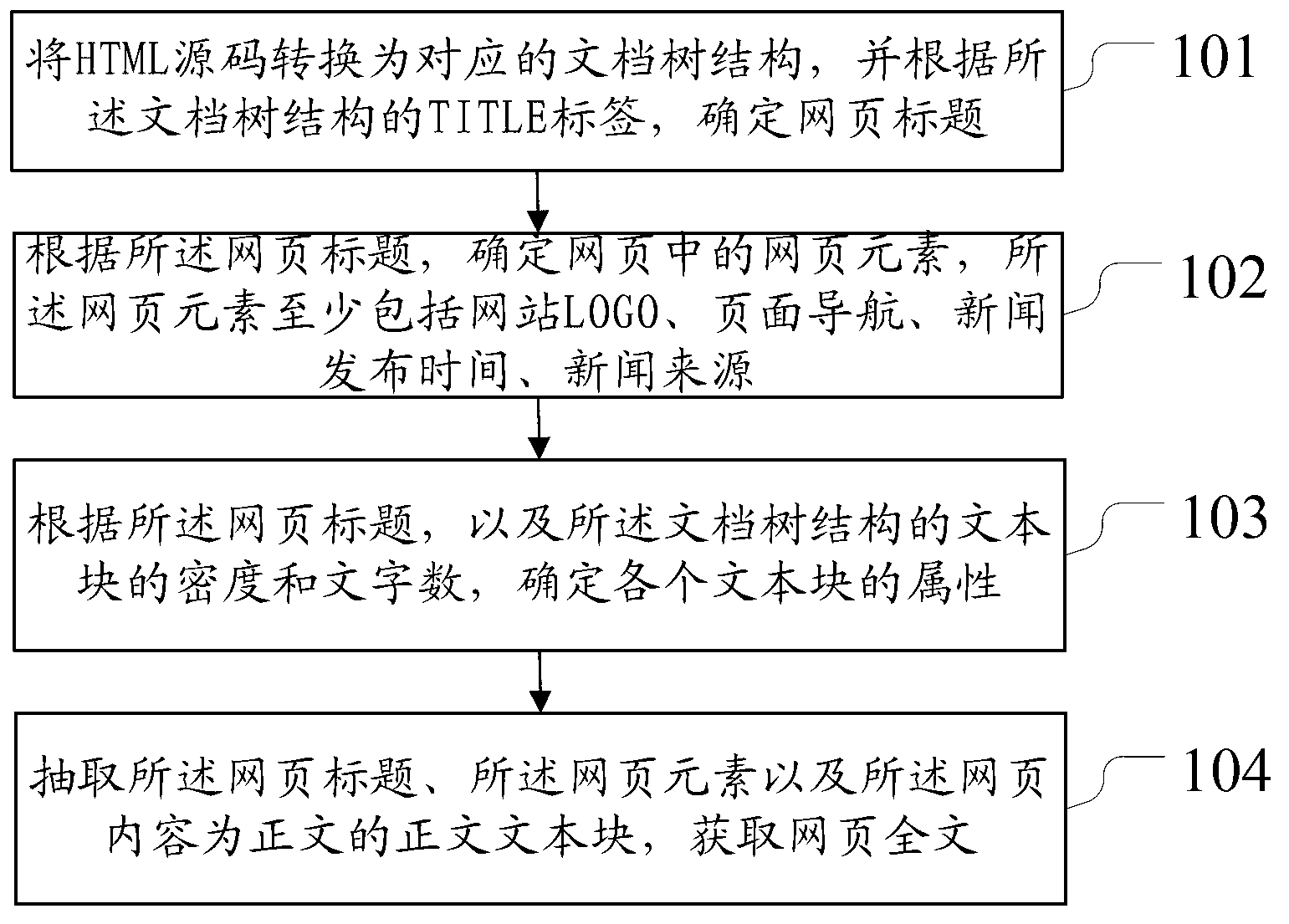
[0028] Embodiments of the present invention provide a method for extracting web page content, such as figure 1 As shown, the method includes:
[0029] Step 101, convert the HTML source code into a corresponding document tree structure, and determine the title of the web page according to the TITLE tag of the document tree structure.
[0030] A document object model (Document Object Model, DOM), which may also be called a document tree structure, may be obtained by parsing a source code of a hypertext markup language (Hyper Text Mark-up Language, HTML) of a web page. The document tree structure contains a lot of useful information that can be used for analysis and pattern matching. The text block can be obtained by analyzing the source code of the document tree structure with SAX. For example, in a web page with a DIV layout, the document tree structure is composed of multiple DIV blocks, and the DIV blocks are text blocks marked with DIV tags. As a container, the DI...
Embodiment 2
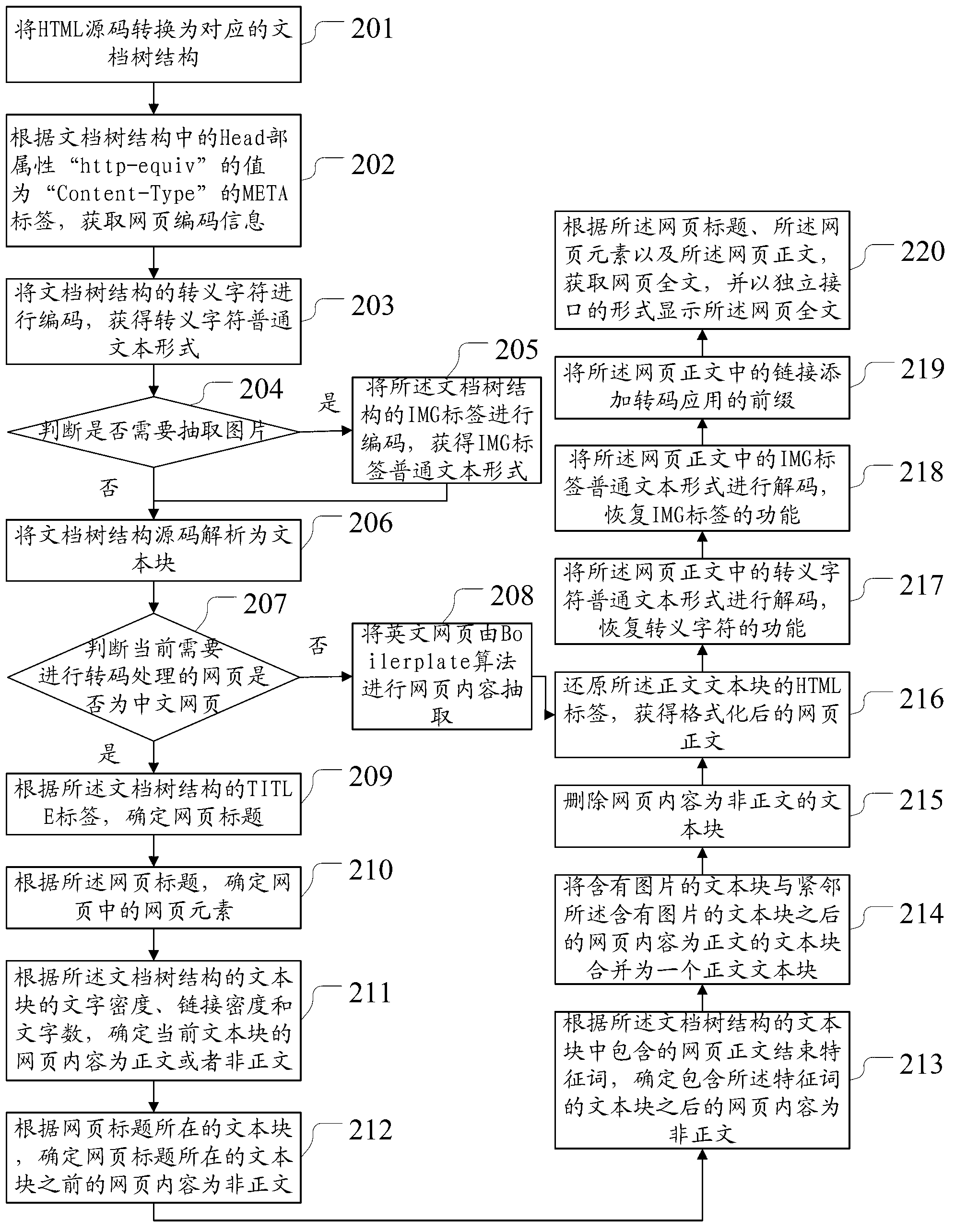
[0139] An embodiment of the present invention provides a device for extracting web page content, such as Figure 4 As shown, the device includes: a conversion unit 401, a webpage title determination unit 402, a webpage element determination unit 403, a text block attribute determination unit 404, and a webpage full-text acquisition unit 405;
[0140] A conversion unit 401, configured to convert the HTML source code into a corresponding document tree structure;
[0141] A webpage title determining unit 402, configured to determine the webpage title according to the TITLE tag of the document tree structure;
[0142] A webpage element determination unit 403, configured to determine webpage elements in the webpage according to the webpage title, the webpage elements at least including website LOGO, page navigation, news release time, and news sources;
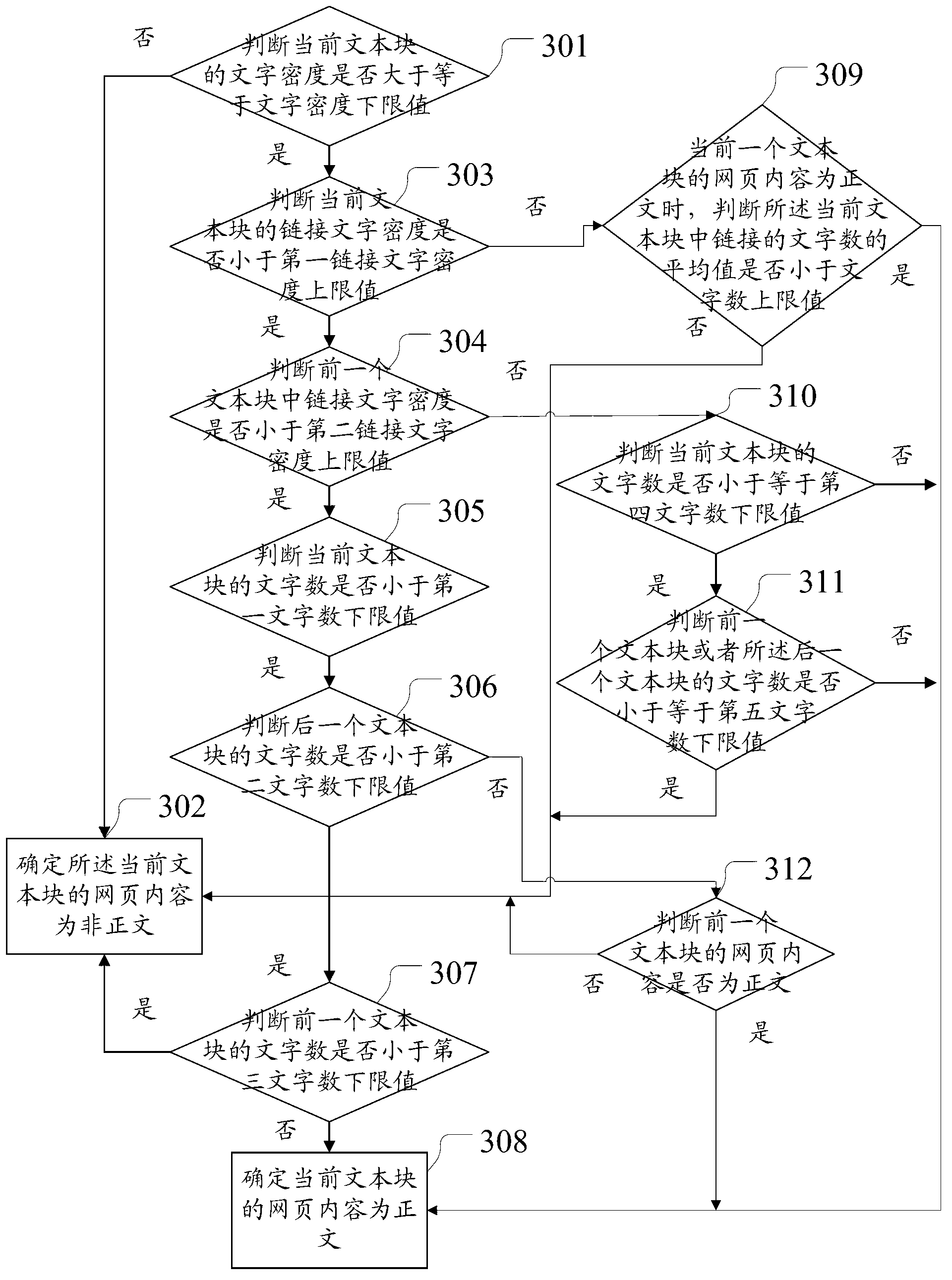
[0143] A text block attribute determination unit 404, configured to determine the attributes of each text block accor...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - Generate Ideas
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com