

Self-adapting preferred fuzzy kernel clustering based naphtha attribute clustering method
A technology of fuzzy kernel clustering and clustering method is applied in the field of fuzzy kernel clustering for adaptively optimizing the number of clusters of naphtha attributes, which can solve the problem of low clustering accuracy, sensitivity to initial values, and limited application of fuzzy kernel clustering methods. And other issues
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

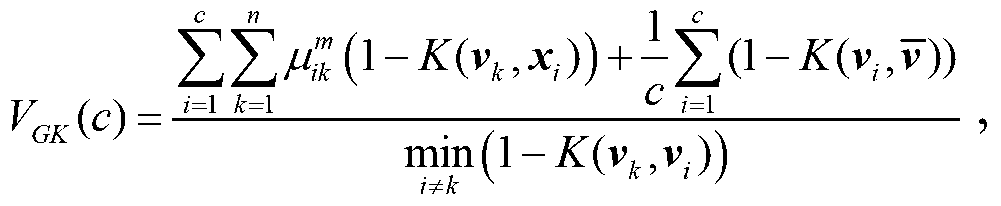
Examples
Embodiment Construction
[0051] Below in conjunction with accompanying drawing and example, further illustrate the present invention.
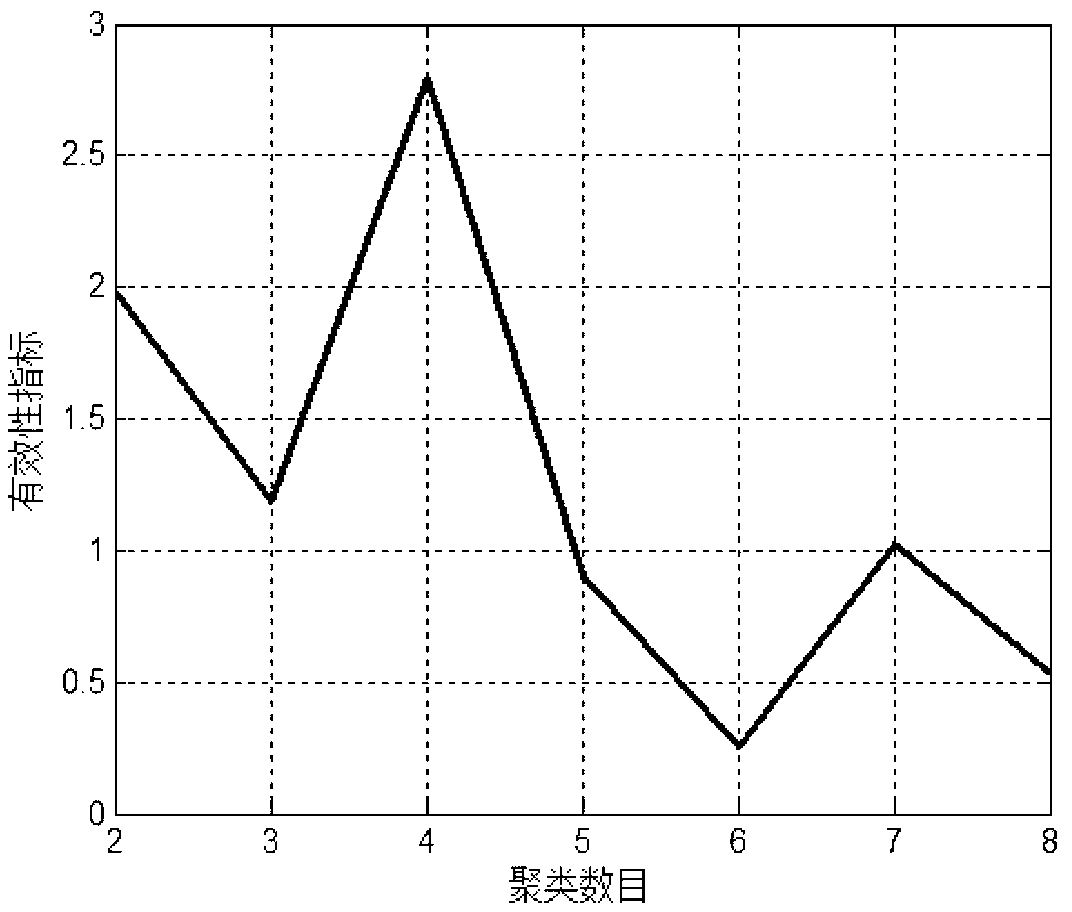
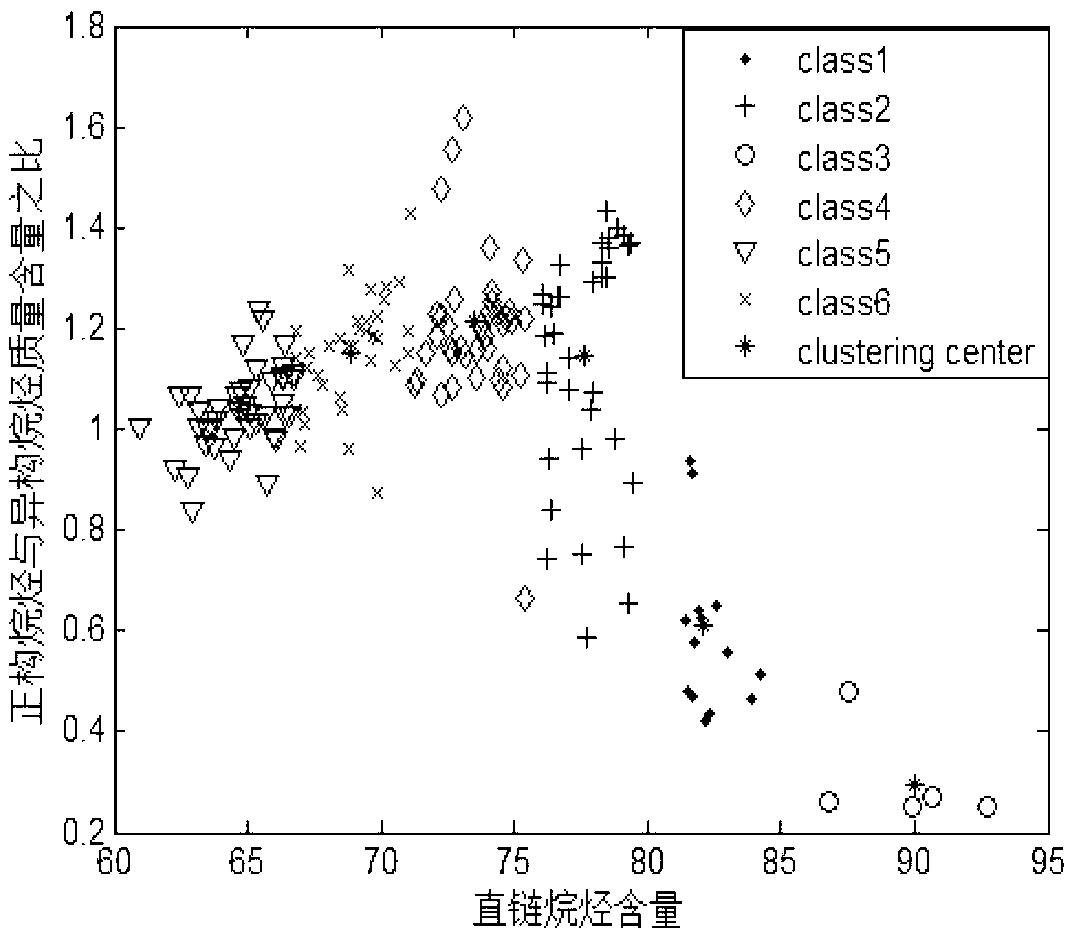
[0052] Step 1: Regularly analyze and organize the naphtha in the new and old areas of a petrochemical olefin plant. After data screening and processing, 170 sets of oil product data are obtained as the original data set for naphtha data clustering. Through mechanism analysis, the present invention selects the content of straight-chain alkanes (P+I) and the ratio of the mass content of normal alkanes to iso-alkanes (P / I) as the two attributes of clustering.
[0053] The second step: use the processed 170 sets of oil product data as the naphtha attribute data set, that is, X={x k |k=1,2,…,170}, x k =[x k1 ,x k2 ] for data x k The 2-dimensional feature vector of . Take the allowable error delt=0.00001, the maximum number of iterations t max =1000, fuzzy control index m=2, Gaussian kernel parameter σ=1.
[0054] The third step: select the initial cluster center by ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More