

Method of setting up speech recognition model, speech recognition method and corresponding device
A speech recognition model and speech recognition technology, applied in the field of speech search, can solve the problems of slow update speed, limit the volume of language model, reduce the search for new things and information, etc., and achieve the effect of high search and fast real-time dynamic update
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
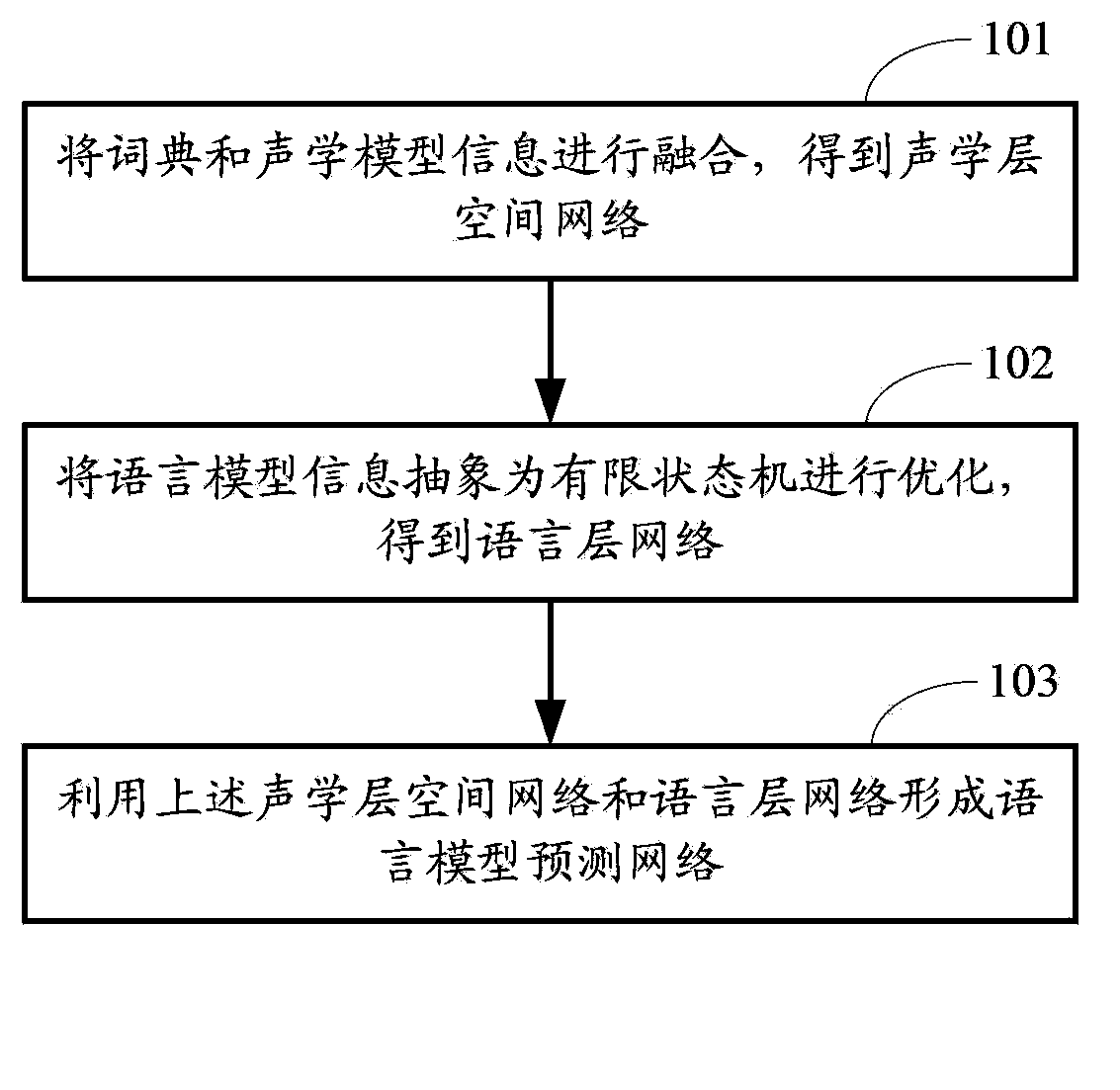
[0060] figure 1 The flow chart of the method for establishing a speech recognition model provided by Embodiment 1 of the present invention, such as figure 1 As shown, the method mainly includes the following steps:
[0061] Step 101: The dictionary and the acoustic model information are fused to obtain an acoustic layer space network.
[0062] The purpose of this step is to establish an acoustic layer space network representing acoustic model information, which is used to organize all acoustic-related information content in speech recognition into a network connected by a large number of nodes that is easy for computer processing.
[0063] The resources required for the construction of the acoustic layer space network are dictionaries and acoustic model information, without any language model information.
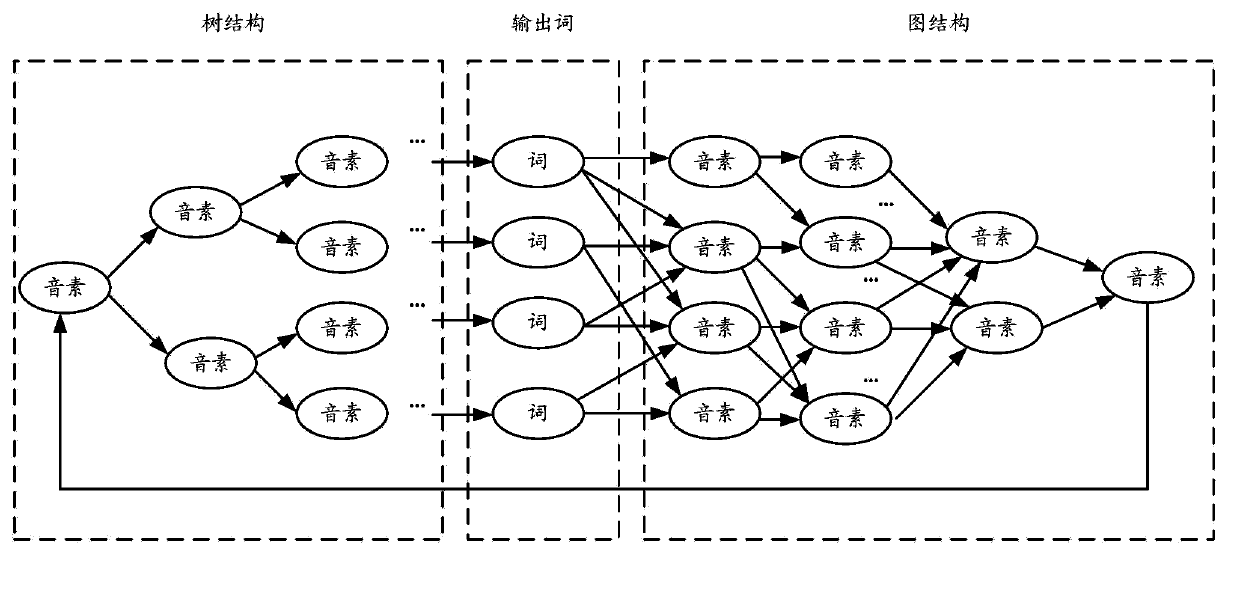
[0064] Specifically, the method for constructing the acoustic layer space network specifically includes: after arranging the words in the dictionary, constructing a jump-...
Embodiment 2
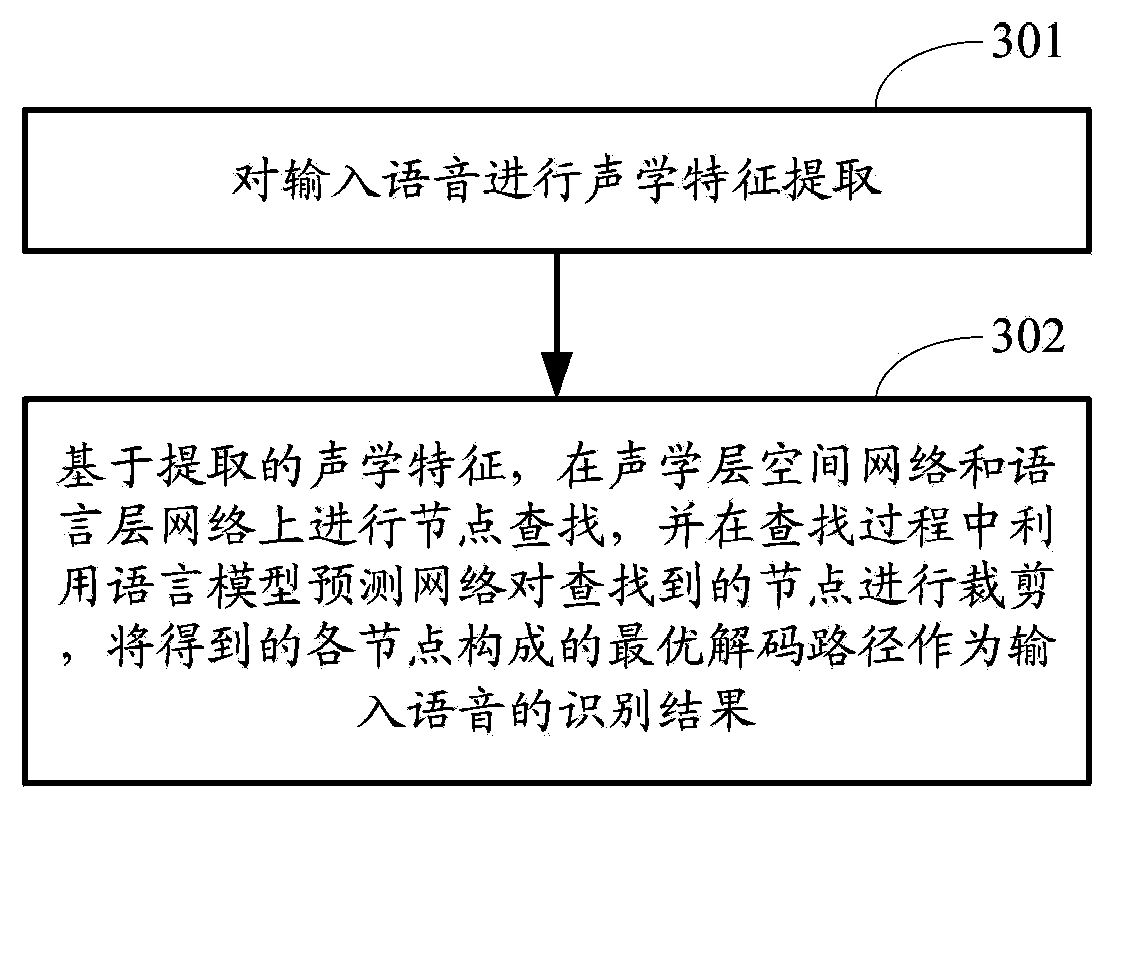
[0078] image 3 The flow chart of the voice recognition method provided by Embodiment 2 of the present invention, such as image 3 As shown, the method may include the following steps:
[0079] Step 301: Acoustic feature extraction is performed on the input speech.
[0080] In this step, the acoustic feature extraction of the input speech can be performed in any way in the prior art, and there is no specific limitation here, such as the extraction of linear predictive cepstral coefficients (LPCC) and Mel frequency cepstral coefficients (MFCC) Wait.
[0081] Step 302: Based on the extracted acoustic features, search for nodes on the acoustic layer space network and the language layer network, and use the language model prediction network to cut the found nodes during the search process, and construct the optimal The decoding path serves as the recognition result of the input speech.
[0082] This step is the core content of speech recognition, in which the search for the ac...
Embodiment 3
[0095] Figure 5 The structure diagram of the device for establishing the speech recognition model provided by Embodiment 3 of the present invention, such as Figure 5 As shown, the device may include: an acoustic layer construction unit 500 , a language layer construction unit 510 and a prediction model construction unit 520 .
[0096] The acoustic layer construction unit 500 fuses the dictionary and the acoustic model information to obtain the acoustic layer space network. The resources required for the construction of the acoustic layer space network are dictionaries and acoustic model information, without any language model information.
[0097] Figure 6 An implementation of the acoustic layer construction unit 500 is shown in , as Figure 6 As shown, it may specifically include: a first construction subunit 501 , a second construction subunit 502 and an optimization subunit 503 .
[0098] After arranging the words in the dictionary, the first construction subunit 501...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More